




Jordan Meyer
@jordanmeyer.bsky.social
Cofounder/CEO at Spawning | Zillow Prize winner
pfp by @irisluckhaus.bsky.social
pfp by @irisluckhaus.bsky.social
Reposted by Jordan Meyer

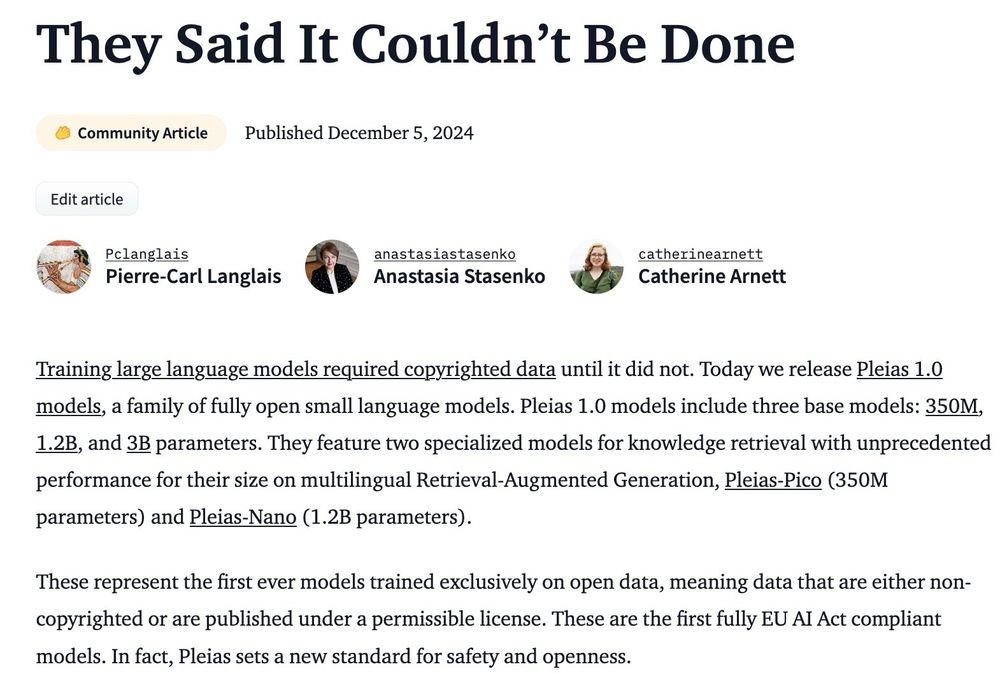
“They said it could not be done”. We’re releasing Pleias 1.0, the first suite of models trained on open data (either permissibly licensed or uncopyrighted): Pleias-3b, Pleias-1b and Pleias-350m, all based on the two trillion tokens set from Common Corpus.
December 5, 2024 at 4:39 PM
“They said it could not be done”. We’re releasing Pleias 1.0, the first suite of models trained on open data (either permissibly licensed or uncopyrighted): Pleias-3b, Pleias-1b and Pleias-350m, all based on the two trillion tokens set from Common Corpus.
███░░░░░░░░░ ~25% trained
"A painting of a mountain lake with a boat in the foreground, surrounded by lush green grass, trees, and rocks. The sky is filled with white, fluffy clouds, creating a peaceful atmosphere."
"A painting of a mountain lake with a boat in the foreground, surrounded by lush green grass, trees, and rocks. The sky is filled with white, fluffy clouds, creating a peaceful atmosphere."

December 6, 2024 at 10:28 PM
███░░░░░░░░░ ~25% trained
"A painting of a mountain lake with a boat in the foreground, surrounded by lush green grass, trees, and rocks. The sky is filled with white, fluffy clouds, creating a peaceful atmosphere."
"A painting of a mountain lake with a boat in the foreground, surrounded by lush green grass, trees, and rocks. The sky is filled with white, fluffy clouds, creating a peaceful atmosphere."
Reposted by Jordan Meyer

Last week we submitted to the #EU AI Office our comments on the 1st draft of the #AI Code of Practice, focusing on #copyright. ©️
On our blog, Teresa Nobre explains our responses and also the concerns expressed by other stakeholders:
communia-association.org/2024/12/04/o...
On our blog, Teresa Nobre explains our responses and also the concerns expressed by other stakeholders:
communia-association.org/2024/12/04/o...

Our analysis of the 1st draft of the General-Purpose AI Code of Practice
In this blogpost, we highlight some of COMMUNIA's responses to the EU survey on the first draft of the GPAI Code of Practice, as well as some of the concerns expressed by other stakeholders at the mee...
communia-association.org
December 4, 2024 at 12:49 PM
Last week we submitted to the #EU AI Office our comments on the 1st draft of the #AI Code of Practice, focusing on #copyright. ©️
On our blog, Teresa Nobre explains our responses and also the concerns expressed by other stakeholders:
communia-association.org/2024/12/04/o...
On our blog, Teresa Nobre explains our responses and also the concerns expressed by other stakeholders:
communia-association.org/2024/12/04/o...
Reposted by Jordan Meyer

Great study on misinformation. Just want to point out that this kind of work is impossible without the fair use doctrine. Massive copying, computational analysis, ...

I’m super excited to announce I'm part of an amazing team (<3 @williambrady.bsky.social @killianmcloughlin.bsky.social @mjcrockett.bsky.social) that just published a paper in @science.org on the role of outrage in spread of misinformation
Link here:
science.org/doi/10.1126/...
Summary in🧵🔽
1/
Link here:
science.org/doi/10.1126/...
Summary in🧵🔽
1/

November 29, 2024 at 10:42 PM
Great study on misinformation. Just want to point out that this kind of work is impossible without the fair use doctrine. Massive copying, computational analysis, ...
Reposted by Jordan Meyer

Hi, so I've spent the past almost-decade studying research uses of public social media data, like e.g. ML researchers using content from Twitter, Reddit, and Mastodon.
Anyway, buckle up this is about to be a VERY long thread with lots of thoughts and links to papers. 🧵
Anyway, buckle up this is about to be a VERY long thread with lots of thoughts and links to papers. 🧵

First dataset for the new @huggingface.bsky.social @bsky.app community organisation: one-million-bluesky-posts 🦋
📊 1M public posts from Bluesky's firehose API
🔍 Includes text, metadata, and language predictions
🔬 Perfect to experiment with using ML for Bluesky 🤗
huggingface.co/datasets/blu...
📊 1M public posts from Bluesky's firehose API
🔍 Includes text, metadata, and language predictions
🔬 Perfect to experiment with using ML for Bluesky 🤗
huggingface.co/datasets/blu...

bluesky-community/one-million-bluesky-posts · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 27, 2024 at 3:31 PM
Hi, so I've spent the past almost-decade studying research uses of public social media data, like e.g. ML researchers using content from Twitter, Reddit, and Mastodon.
Anyway, buckle up this is about to be a VERY long thread with lots of thoughts and links to papers. 🧵
Anyway, buckle up this is about to be a VERY long thread with lots of thoughts and links to papers. 🧵
Reposted by Jordan Meyer

Sincerely do not tell anyone in the replies what the fire hose is lmao

November 15, 2024 at 10:14 PM
Sincerely do not tell anyone in the replies what the fire hose is lmao