




Jaydeep Borkar
@jaydeepborkar.bsky.social
Visiting Researcher at Meta NYC🦙 and PhD student at Northeastern. Organizer at the Trustworthy ML Initiative (trustworthyml.org). s&p in language models + mountain biking.
jaydeepborkar.github.io
jaydeepborkar.github.io
Pinned

What happens if we fine-tune an LLM on more PII? We find that PII that wasn’t previously extracted gets extracted after fine-tuning on *other* PII. This could have implications for earlier seen data (e.g. during post-training or further fine-tuning). 🧵
paper: arxiv.org/pdf/2502.15680
paper: arxiv.org/pdf/2502.15680
Reposted by Jaydeep Borkar

Syntax that spuriously correlates with safe domains can jailbreak LLMs - e.g. below with GPT4o mini
Our paper (co w/ Vinith Suriyakumar) on syntax-domain spurious correlations will appear at #NeurIPS2025 as a ✨spotlight!
+ @marzyehghassemi.bsky.social, @byron.bsky.social, Levent Sagun
Our paper (co w/ Vinith Suriyakumar) on syntax-domain spurious correlations will appear at #NeurIPS2025 as a ✨spotlight!
+ @marzyehghassemi.bsky.social, @byron.bsky.social, Levent Sagun


October 24, 2025 at 4:23 PM
Syntax that spuriously correlates with safe domains can jailbreak LLMs - e.g. below with GPT4o mini
Our paper (co w/ Vinith Suriyakumar) on syntax-domain spurious correlations will appear at #NeurIPS2025 as a ✨spotlight!
+ @marzyehghassemi.bsky.social, @byron.bsky.social, Levent Sagun
Our paper (co w/ Vinith Suriyakumar) on syntax-domain spurious correlations will appear at #NeurIPS2025 as a ✨spotlight!
+ @marzyehghassemi.bsky.social, @byron.bsky.social, Levent Sagun
Reposted by Jaydeep Borkar

It is PhD application season again 🍂 For those looking to do a PhD in AI, these are some useful resources 🤖:
1. Examples of statements of purpose (SOPs) for computer science PhD programs: cs-sop.org [1/4]
1. Examples of statements of purpose (SOPs) for computer science PhD programs: cs-sop.org [1/4]

CS PhD Statements of Purpose
cs-sop.org is a platform intended to help CS PhD applicants. It hosts a database of example statements of purpose (SoP) shared by previous applicants to Computer Science PhD programs.
cs-sop.org
October 1, 2025 at 8:37 PM
It is PhD application season again 🍂 For those looking to do a PhD in AI, these are some useful resources 🤖:
1. Examples of statements of purpose (SOPs) for computer science PhD programs: cs-sop.org [1/4]
1. Examples of statements of purpose (SOPs) for computer science PhD programs: cs-sop.org [1/4]
Reposted by Jaydeep Borkar
"AI slop" seems to be everywhere, but what exactly makes text feel like "slop"?
In our new work (w/ @tuhinchakr.bsky.social, Diego Garcia-Olano, @byron.bsky.social ) we provide a systematic attempt at measuring AI "slop" in text!
arxiv.org/abs/2509.19163
🧵 (1/7)
In our new work (w/ @tuhinchakr.bsky.social, Diego Garcia-Olano, @byron.bsky.social ) we provide a systematic attempt at measuring AI "slop" in text!
arxiv.org/abs/2509.19163
🧵 (1/7)


September 24, 2025 at 1:21 PM
"AI slop" seems to be everywhere, but what exactly makes text feel like "slop"?
In our new work (w/ @tuhinchakr.bsky.social, Diego Garcia-Olano, @byron.bsky.social ) we provide a systematic attempt at measuring AI "slop" in text!
arxiv.org/abs/2509.19163
🧵 (1/7)
In our new work (w/ @tuhinchakr.bsky.social, Diego Garcia-Olano, @byron.bsky.social ) we provide a systematic attempt at measuring AI "slop" in text!
arxiv.org/abs/2509.19163
🧵 (1/7)
Reposted by Jaydeep Borkar

After 2 years in press, it's published!
"Talkin' 'Bout AI Generation: Copyright and the Generative-AI Supply Chain," is out in the 72nd volume of the Journal of the Copyright Society
copyrightsociety.org/journal-entr...
written with @katherinelee.bsky.social & @jtlg.bsky.social (2023)
"Talkin' 'Bout AI Generation: Copyright and the Generative-AI Supply Chain," is out in the 72nd volume of the Journal of the Copyright Society
copyrightsociety.org/journal-entr...
written with @katherinelee.bsky.social & @jtlg.bsky.social (2023)

TALKIN' 'BOUT AI GENERATION: COPYRIGHT AND THE GENERATIVE-AI SUPPLY CHAIN | The Copyright Society
We know copyright
copyrightsociety.org
September 10, 2025 at 7:12 PM
After 2 years in press, it's published!
"Talkin' 'Bout AI Generation: Copyright and the Generative-AI Supply Chain," is out in the 72nd volume of the Journal of the Copyright Society
copyrightsociety.org/journal-entr...
written with @katherinelee.bsky.social & @jtlg.bsky.social (2023)
"Talkin' 'Bout AI Generation: Copyright and the Generative-AI Supply Chain," is out in the 72nd volume of the Journal of the Copyright Society
copyrightsociety.org/journal-entr...
written with @katherinelee.bsky.social & @jtlg.bsky.social (2023)
Excited to be attending ACL in Vienna next week! I’ll be co-presenting a poster with Niloofar Mireshghallah on our recent PII memorization work on July 29 16:00-17:30 Session 10 Hall 4/5 (& at LLM memorization workshop)!
If you would like to chat memorization/privacy/safety/, please reach out :)
If you would like to chat memorization/privacy/safety/, please reach out :)
What happens if we fine-tune an LLM on more PII? We find that PII that wasn’t previously extracted gets extracted after fine-tuning on *other* PII. This could have implications for earlier seen data (e.g. during post-training or further fine-tuning). 🧵
paper: arxiv.org/pdf/2502.15680
paper: arxiv.org/pdf/2502.15680
July 22, 2025 at 4:38 AM
Excited to be attending ACL in Vienna next week! I’ll be co-presenting a poster with Niloofar Mireshghallah on our recent PII memorization work on July 29 16:00-17:30 Session 10 Hall 4/5 (& at LLM memorization workshop)!
If you would like to chat memorization/privacy/safety/, please reach out :)
If you would like to chat memorization/privacy/safety/, please reach out :)
What happens if we fine-tune an LLM on more PII? We find that PII that wasn’t previously extracted gets extracted after fine-tuning on *other* PII. This could have implications for earlier seen data (e.g. during post-training or further fine-tuning). 🧵
paper: arxiv.org/pdf/2502.15680
paper: arxiv.org/pdf/2502.15680
May 15, 2025 at 5:24 PM
Very excited to be joining Meta GenAI as a Visiting Researcher starting this June in New York City!🗽 I’ll be continuing my work on studying memorization and safety in language models.
If you’re in NYC and would like to hang out, please message me :)
If you’re in NYC and would like to hang out, please message me :)

May 15, 2025 at 3:18 AM
Very excited to be joining Meta GenAI as a Visiting Researcher starting this June in New York City!🗽 I’ll be continuing my work on studying memorization and safety in language models.
If you’re in NYC and would like to hang out, please message me :)
If you’re in NYC and would like to hang out, please message me :)
Reposted by Jaydeep Borkar

I am at CHI this week to present my poster (Framing Health Information: The Impact of Search Methods and Source Types on User Trust and Satisfaction in the Age of LLMs) on Wednesday April 30
CHI Program Link: programs.sigchi.org/chi/2025/pro...
Looking forward to connecting with you all!
CHI Program Link: programs.sigchi.org/chi/2025/pro...
Looking forward to connecting with you all!

April 29, 2025 at 12:50 AM
I am at CHI this week to present my poster (Framing Health Information: The Impact of Search Methods and Source Types on User Trust and Satisfaction in the Age of LLMs) on Wednesday April 30
CHI Program Link: programs.sigchi.org/chi/2025/pro...
Looking forward to connecting with you all!
CHI Program Link: programs.sigchi.org/chi/2025/pro...
Looking forward to connecting with you all!
Reposted by Jaydeep Borkar

4/26 at 3pm:
'Recite, Reconstruct, Recollect: Memorization in LMs as a Multifaceted Phenomenon'
USVSN Sai Prashanth · @nsaphra.bsky.social et al
Submission: openreview.net/forum?id=3E8...
'Recite, Reconstruct, Recollect: Memorization in LMs as a Multifaceted Phenomenon'
USVSN Sai Prashanth · @nsaphra.bsky.social et al
Submission: openreview.net/forum?id=3E8...

April 25, 2025 at 5:28 PM
4/26 at 3pm:
'Recite, Reconstruct, Recollect: Memorization in LMs as a Multifaceted Phenomenon'
USVSN Sai Prashanth · @nsaphra.bsky.social et al
Submission: openreview.net/forum?id=3E8...
'Recite, Reconstruct, Recollect: Memorization in LMs as a Multifaceted Phenomenon'
USVSN Sai Prashanth · @nsaphra.bsky.social et al
Submission: openreview.net/forum?id=3E8...
Bummed to be missing ICLR, but if you’re interested in all things memorization, stop by poster #200 Hall 3 + Hall 2B on April 26 3-5:30 pm and chat with several of my awesome co-authors.
We propose a taxonomy for different types of memorization in LMs. Paper: openreview.net/pdf?id=3E8YN...
We propose a taxonomy for different types of memorization in LMs. Paper: openreview.net/pdf?id=3E8YN...
openreview.net
April 21, 2025 at 7:22 PM
Bummed to be missing ICLR, but if you’re interested in all things memorization, stop by poster #200 Hall 3 + Hall 2B on April 26 3-5:30 pm and chat with several of my awesome co-authors.
We propose a taxonomy for different types of memorization in LMs. Paper: openreview.net/pdf?id=3E8YN...
We propose a taxonomy for different types of memorization in LMs. Paper: openreview.net/pdf?id=3E8YN...
Reposted by Jaydeep Borkar

[📄] Are LLMs mindless token-shifters, or do they build meaningful representations of language? We study how LLMs copy text in-context, and physically separate out two types of induction heads: token heads, which copy literal tokens, and concept heads, which copy word meanings.
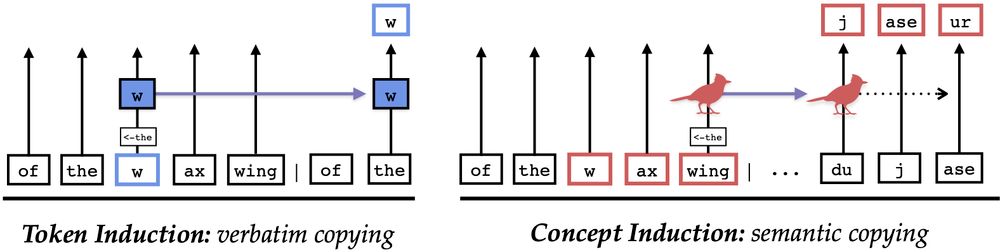
April 7, 2025 at 1:54 PM
[📄] Are LLMs mindless token-shifters, or do they build meaningful representations of language? We study how LLMs copy text in-context, and physically separate out two types of induction heads: token heads, which copy literal tokens, and concept heads, which copy word meanings.
BU and Boston are incredibly lucky to have Naomi!!!
Life update: I'm starting as faculty at Boston University
@bucds.bsky.social in 2026! BU has SCHEMES for LM interpretability & analysis, I couldn't be more pumped to join a burgeoning supergroup w/ @najoung.bsky.social @amuuueller.bsky.social. Looking for my first students, so apply and reach out!
@bucds.bsky.social in 2026! BU has SCHEMES for LM interpretability & analysis, I couldn't be more pumped to join a burgeoning supergroup w/ @najoung.bsky.social @amuuueller.bsky.social. Looking for my first students, so apply and reach out!

March 27, 2025 at 4:39 AM
BU and Boston are incredibly lucky to have Naomi!!!
Really liked this slide by @afedercooper.bsky.social on categorizing extraction vs regurgitation vs memorization of training data at CS&Law today!

March 25, 2025 at 9:11 PM
Really liked this slide by @afedercooper.bsky.social on categorizing extraction vs regurgitation vs memorization of training data at CS&Law today!
This is some great work!! I personally feel that one of the bottlenecks with memorization evals is having access to the gigantic training data. Super cool to see we can still run reliable evals without having access to the training data!
Want to know what training data has been memorized by models like GPT-4?
We propose information-guided probes, a method to uncover memorization evidence in *completely black-box* models,
without requiring access to
🙅♀️ Model weights
🙅♀️ Training data
🙅♀️ Token probabilities 🧵 (1/5)
We propose information-guided probes, a method to uncover memorization evidence in *completely black-box* models,
without requiring access to
🙅♀️ Model weights
🙅♀️ Training data
🙅♀️ Token probabilities 🧵 (1/5)

Information-Guided Identification of Training Data Imprint in (Proprietary) Large Language Models
High-quality training data has proven crucial for developing performant large language models (LLMs). However, commercial LLM providers disclose few, if any, details about the data used for training. ...
arxiv.org
March 23, 2025 at 11:24 PM
This is some great work!! I personally feel that one of the bottlenecks with memorization evals is having access to the gigantic training data. Super cool to see we can still run reliable evals without having access to the training data!
Excited to be in Munich for my first ACM CS&Law! If you are interested in chatting about memorization + privacy/law in language models, we should hang out :)
March 23, 2025 at 11:09 PM
Excited to be in Munich for my first ACM CS&Law! If you are interested in chatting about memorization + privacy/law in language models, we should hang out :)
Reposted by Jaydeep Borkar

If you're in the northeastern US and you're submitting a paper to COLM on March 27, you should absolutely be sending its abstract to New England NLP on March 28.
New England NLP Meeting Series
nenlp.github.io
March 19, 2025 at 7:59 PM
If you're in the northeastern US and you're submitting a paper to COLM on March 27, you should absolutely be sending its abstract to New England NLP on March 28.
Reposted by Jaydeep Borkar

*Please repost* @sjgreenwood.bsky.social and I just launched a new personalized feed (*please pin*) that we hope will become a "must use" for #academicsky. The feed shows posts about papers filtered by *your* follower network. It's become my default Bluesky experience bsky.app/profile/pape...
March 10, 2025 at 6:14 PM
*Please repost* @sjgreenwood.bsky.social and I just launched a new personalized feed (*please pin*) that we hope will become a "must use" for #academicsky. The feed shows posts about papers filtered by *your* follower network. It's become my default Bluesky experience bsky.app/profile/pape...
Reposted by Jaydeep Borkar
I'm searching for some comp/ling experts to provide a precise definition of “slop” as it refers to text (see: corp.oup.com/word-of-the-...)
I put together a google form that should take no longer than 10 minutes to complete: forms.gle/oWxsCScW3dJU...
If you can help, I'd appreciate your input! 🙏
I put together a google form that should take no longer than 10 minutes to complete: forms.gle/oWxsCScW3dJU...
If you can help, I'd appreciate your input! 🙏

Oxford Word of the Year 2024 - Oxford University Press
The Oxford Word of the Year 2024 is 'brain rot'. Discover more about the winner, our shortlist, and 20 years of words that reflect the world.
corp.oup.com
March 10, 2025 at 8:00 PM
I'm searching for some comp/ling experts to provide a precise definition of “slop” as it refers to text (see: corp.oup.com/word-of-the-...)
I put together a google form that should take no longer than 10 minutes to complete: forms.gle/oWxsCScW3dJU...
If you can help, I'd appreciate your input! 🙏
I put together a google form that should take no longer than 10 minutes to complete: forms.gle/oWxsCScW3dJU...
If you can help, I'd appreciate your input! 🙏
Reposted by Jaydeep Borkar
We’ve been receiving a bunch of questions about a CFP for GenLaw 2025.
We wanted to let you know that we chose not to submit a workshop proposal this year (we need a break!!). We’ll be at ICML though and look forward to catching up there!
You can watch our prior videos!
We wanted to let you know that we chose not to submit a workshop proposal this year (we need a break!!). We’ll be at ICML though and look forward to catching up there!
You can watch our prior videos!

March 9, 2025 at 8:33 PM
We’ve been receiving a bunch of questions about a CFP for GenLaw 2025.
We wanted to let you know that we chose not to submit a workshop proposal this year (we need a break!!). We’ll be at ICML though and look forward to catching up there!
You can watch our prior videos!
We wanted to let you know that we chose not to submit a workshop proposal this year (we need a break!!). We’ll be at ICML though and look forward to catching up there!
You can watch our prior videos!
Reposted by Jaydeep Borkar

Nicholas is leaving GDM at the end of this week, and we're feeling big sad about it: nicholas.carlini.com/writing/2025...
Career Update: Google DeepMind -> Anthropic
TODO
nicholas.carlini.com
March 5, 2025 at 9:56 PM
Nicholas is leaving GDM at the end of this week, and we're feeling big sad about it: nicholas.carlini.com/writing/2025...
Reposted by Jaydeep Borkar
Last CFP at ACM CS&Law ‘25! Please submit your two-minute lightning talks. It’s a great way to advertise work to the community and to find potential new collaborators!
More info (including about registration) on the website: computersciencelaw.org/2025
More info (including about registration) on the website: computersciencelaw.org/2025
2025 - ACM Symposium on Computer Science & Law
CS&Law 2025 4th ACM Symposium on Computer Science and Law March 25-27, 2025Munich, Germany Submission for lightning talks is open…
computersciencelaw.org
March 5, 2025 at 7:16 PM
Last CFP at ACM CS&Law ‘25! Please submit your two-minute lightning talks. It’s a great way to advertise work to the community and to find potential new collaborators!
More info (including about registration) on the website: computersciencelaw.org/2025
More info (including about registration) on the website: computersciencelaw.org/2025
What happens if we fine-tune an LLM on more PII? We find that PII that wasn’t previously extracted gets extracted after fine-tuning on *other* PII. This could have implications for earlier seen data (e.g. during post-training or further fine-tuning). 🧵
paper: arxiv.org/pdf/2502.15680
paper: arxiv.org/pdf/2502.15680
March 2, 2025 at 7:20 PM
What happens if we fine-tune an LLM on more PII? We find that PII that wasn’t previously extracted gets extracted after fine-tuning on *other* PII. This could have implications for earlier seen data (e.g. during post-training or further fine-tuning). 🧵
paper: arxiv.org/pdf/2502.15680
paper: arxiv.org/pdf/2502.15680
Reposted by Jaydeep Borkar

More on LLM training dynamics from @jaydeepborkar.bsky.social: Even when personal information is sampled independently from the rest of the training data, interactions in term statistics can still increase leakage. arxiv.org/abs/2502.15680

Privacy Ripple Effects from Adding or Removing Personal Information in Language Model Training
Due to the sensitive nature of personally identifiable information (PII), its owners may have the authority to control its inclusion or request its removal from large-language model (LLM) training. Be...
arxiv.org
February 27, 2025 at 3:26 PM
More on LLM training dynamics from @jaydeepborkar.bsky.social: Even when personal information is sampled independently from the rest of the training data, interactions in term statistics can still increase leakage. arxiv.org/abs/2502.15680
Reposted by Jaydeep Borkar
A antique sci-fi treat for everyone talking about language models, copyright, plagiarism, and when humans can exhaust the space of all possible art.
Spider Robinson: Melancholy Elephants
www.spiderrobinson.com
January 4, 2025 at 3:13 AM
A antique sci-fi treat for everyone talking about language models, copyright, plagiarism, and when humans can exhaust the space of all possible art.