




Faro Stöter
@faroit.bsky.social
AudioML research scientist at https://audioshake.ai, before: post-doc @inria@social.numerique.gouv.fr, Editor at https://bsky.app/profile/joss-openjournals.bsky.social
All in 17.68% of grey, located in Frankfurt (Germany)
All in 17.68% of grey, located in Frankfurt (Germany)
Enjoyed my first @interspeech.bsky.social conference. Seems like a great community. Well organized and great venue. This is how big conferences could look like. Take notes, ICASSP!
August 21, 2025 at 8:18 AM
Enjoyed my first @interspeech.bsky.social conference. Seems like a great community. Well organized and great venue. This is how big conferences could look like. Take notes, ICASSP!
August 17, 2025 at 8:24 PM
Reposted by Faro Stöter

Harvard Business on Open Source: When PyTorch left Meta for its own non-profit, "this shift led to a significant decrease in contributions from Meta but a notable increase from external companies...participation increased from complementors (Chip Manufacturers);" papers.ssrn.com/sol3/papers....
Igniting Innovation: Evidence from PyTorch on Technology Control in Open Collaboration
<div>
Many companies offer free access to their technology to encourage outside add-on <span>innovation, hoping to later profit by raising prices or harne
papers.ssrn.com
March 20, 2025 at 9:08 PM
Harvard Business on Open Source: When PyTorch left Meta for its own non-profit, "this shift led to a significant decrease in contributions from Meta but a notable increase from external companies...participation increased from complementors (Chip Manufacturers);" papers.ssrn.com/sol3/papers....
🚀 We’re looking for a Master’s student to join our research team for a 6-month internship at AudioShake!
Deep dive into PyTorch, optimize our SOTA audio models, and help make ML sound better (and faster) 🎶
Based in Paris or remote 🇫🇷 → audioshake.notion.site/Internship-M... #AudioML #Internship
Deep dive into PyTorch, optimize our SOTA audio models, and help make ML sound better (and faster) 🎶
Based in Paris or remote 🇫🇷 → audioshake.notion.site/Internship-M... #AudioML #Internship

Internship: ML Optimization | Notion
Location: Paris preferred (remote within France/EU possible)
audioshake.notion.site
June 25, 2025 at 2:02 PM
🚀 We’re looking for a Master’s student to join our research team for a 6-month internship at AudioShake!
Deep dive into PyTorch, optimize our SOTA audio models, and help make ML sound better (and faster) 🎶
Based in Paris or remote 🇫🇷 → audioshake.notion.site/Internship-M... #AudioML #Internship
Deep dive into PyTorch, optimize our SOTA audio models, and help make ML sound better (and faster) 🎶
Based in Paris or remote 🇫🇷 → audioshake.notion.site/Internship-M... #AudioML #Internship
Reposted by Faro Stöter

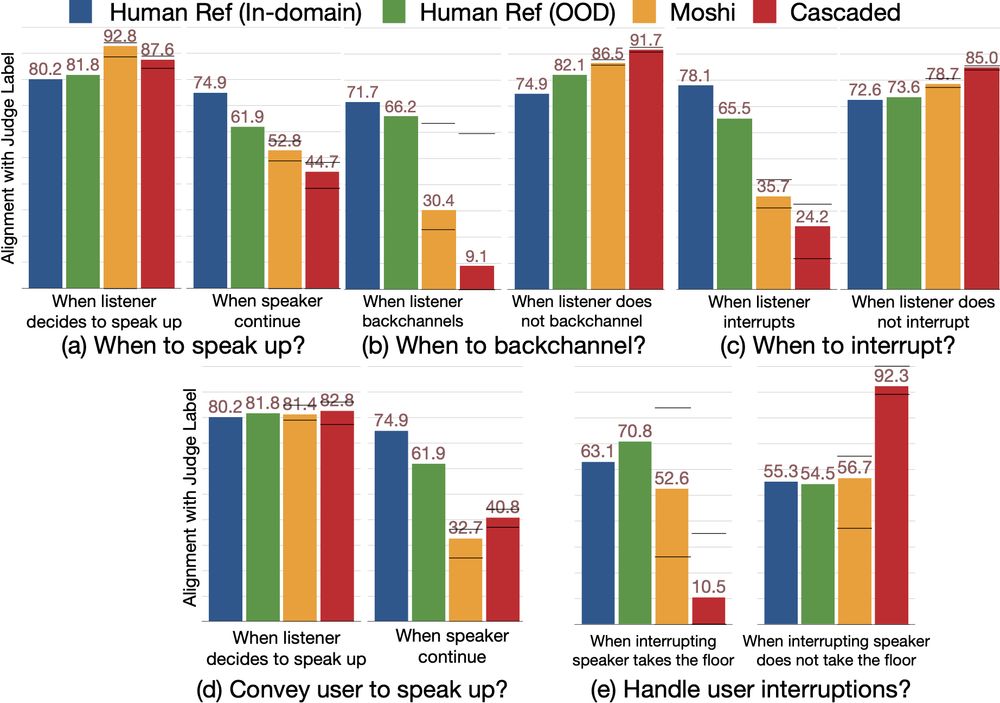
🚀 New #ICLR2025 Paper Alert! 🚀
Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊
We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇
📜: arxiv.org/abs/2503.01174
Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊
We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇
📜: arxiv.org/abs/2503.01174
March 5, 2025 at 4:03 PM
🚀 New #ICLR2025 Paper Alert! 🚀
Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊
We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇
📜: arxiv.org/abs/2503.01174
Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊
We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇
📜: arxiv.org/abs/2503.01174
@interspeech.bsky.social new to the speech community coming from ISMIR/ICASSP/Eusipco/DAFX. How come Interspeech is that much more expensive than other conferences? This makes it very hard for many researchers to get approval!

May 20, 2025 at 7:03 PM
@interspeech.bsky.social new to the speech community coming from ISMIR/ICASSP/Eusipco/DAFX. How come Interspeech is that much more expensive than other conferences? This makes it very hard for many researchers to get approval!
Not knowing much about spatial audio: how do people render multiple dry mono sources to a wet reverberated stereo image where each source has a fixed position in space? I guess one could use ambisonics RiRs to create stereo images? But whats the easier way to handle the positioning?
April 4, 2025 at 1:18 PM
Not knowing much about spatial audio: how do people render multiple dry mono sources to a wet reverberated stereo image where each source has a fixed position in space? I guess one could use ambisonics RiRs to create stereo images? But whats the easier way to handle the positioning?
Reposted by Faro Stöter

AudioShake’s Multi-Speaker Separation is the first-ever hi-res solution for isolating overlapping voices. Perfect for media pros, transcription, & AI voice workflows. 🔗www.audioshake.ai/post/introducing-multi-speaker-separation-from-audioshake

March 5, 2025 at 6:58 PM
AudioShake’s Multi-Speaker Separation is the first-ever hi-res solution for isolating overlapping voices. Perfect for media pros, transcription, & AI voice workflows. 🔗www.audioshake.ai/post/introducing-multi-speaker-separation-from-audioshake
Reposted by Faro Stöter
How stem separation tech brought the legendary voice of Maria Callas back to life in “Maria". 🎶 Isolating Callas’s original vocals allowed @warnerclassics.bsky.social and filmmakers to control and blend her voice with Jolie’s performance. 🔗 Read: www.audioshake.ai/post/audiosh...

AudioShake Isolations Bring Maria Callas’ Voice to Life in Netflix film, “Maria”
Filmmakers and Warner Classics in partnership with the Maria Callas Estate, used AudioShake’s stem separation to isolate her voice to perfect the biopic’s music
www.audioshake.ai
February 13, 2025 at 8:41 PM
How stem separation tech brought the legendary voice of Maria Callas back to life in “Maria". 🎶 Isolating Callas’s original vocals allowed @warnerclassics.bsky.social and filmmakers to control and blend her voice with Jolie’s performance. 🔗 Read: www.audioshake.ai/post/audiosh...
Reposted by Faro Stöter

We just released the Helium-1 model , a 2B multi-lingual LLM which @exgrv.bsky.social and @lmazare.bsky.social have been crafting for us! Best model so far under 2.17B params on multi-lingual benchmarks 🇬🇧🇮🇹🇪🇸🇵🇹🇫🇷🇩🇪
On HF, under CC-BY licence: huggingface.co/kyutai/heliu...
On HF, under CC-BY licence: huggingface.co/kyutai/heliu...

January 13, 2025 at 6:10 PM
We just released the Helium-1 model , a 2B multi-lingual LLM which @exgrv.bsky.social and @lmazare.bsky.social have been crafting for us! Best model so far under 2.17B params on multi-lingual benchmarks 🇬🇧🇮🇹🇪🇸🇵🇹🇫🇷🇩🇪
On HF, under CC-BY licence: huggingface.co/kyutai/heliu...
On HF, under CC-BY licence: huggingface.co/kyutai/heliu...
Reposted by Faro Stöter

Our article, "Diffusion Models for Audio Restoration: A Review," is now published in the IEEE Signal Processing Magazine!
A huge thank you to all co-authors Jean-Marie Lemercier, Julius Richter, Simon Welker, Eloi Moliner, and Vesa Välimäki for a great collaboration.
doi.org/10.1109/MSP....
A huge thank you to all co-authors Jean-Marie Lemercier, Julius Richter, Simon Welker, Eloi Moliner, and Vesa Välimäki for a great collaboration.
doi.org/10.1109/MSP....

Diffusion Models for Audio Restoration: A review [Special Issue On Model-Based and Data-Driven Audio Signal Processing]
With the development of audio playback devices and fast data transmission, the demand for high sound quality is rising for both entertainment and communications. In this quest for better sound quality...
doi.org
January 6, 2025 at 8:17 AM
Our article, "Diffusion Models for Audio Restoration: A Review," is now published in the IEEE Signal Processing Magazine!
A huge thank you to all co-authors Jean-Marie Lemercier, Julius Richter, Simon Welker, Eloi Moliner, and Vesa Välimäki for a great collaboration.
doi.org/10.1109/MSP....
A huge thank you to all co-authors Jean-Marie Lemercier, Julius Richter, Simon Welker, Eloi Moliner, and Vesa Välimäki for a great collaboration.
doi.org/10.1109/MSP....
Reposted by Faro Stöter

Today, we’re introducing NatureLM-audio: the first large audio-language model tailored for understanding animal sounds. arxiv.org/abs/2411.07186 🧵👇

December 5, 2024 at 12:45 AM
Today, we’re introducing NatureLM-audio: the first large audio-language model tailored for understanding animal sounds. arxiv.org/abs/2411.07186 🧵👇
Where is AGI that charges all my devices and batteries?
December 27, 2024 at 7:47 PM
Where is AGI that charges all my devices and batteries?
Reposted by Faro Stöter

Since this is a new platform and mHuBERT-147 just reached 86k downloads, let me make some promotion!
This year we released a compact powerful multilingual SSL model. Trained on balanced, high-quality, open-license data, this model rivals MMS-1B but is 10x smaller.
huggingface.co/utter-projec...
This year we released a compact powerful multilingual SSL model. Trained on balanced, high-quality, open-license data, this model rivals MMS-1B but is 10x smaller.
huggingface.co/utter-projec...

utter-project/mHuBERT-147 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 21, 2024 at 3:43 PM
Since this is a new platform and mHuBERT-147 just reached 86k downloads, let me make some promotion!
This year we released a compact powerful multilingual SSL model. Trained on balanced, high-quality, open-license data, this model rivals MMS-1B but is 10x smaller.
huggingface.co/utter-projec...
This year we released a compact powerful multilingual SSL model. Trained on balanced, high-quality, open-license data, this model rivals MMS-1B but is 10x smaller.
huggingface.co/utter-projec...
Reposted by Faro Stöter

Looking for reviewers before Christmas
December 11, 2024 at 5:25 AM
Looking for reviewers before Christmas
Reposted by Faro Stöter

🌟 URGENT Challenge @ #Interspeech2025 🌟
Join the Universal, Robust, & Generalizable Speech EnhancemeNT (URGENT) challenge! Explore noisy corpora, tackle diverse speech degradations, and test scalability across 2 tracks (~2.5k/60k hrs).
🚀 Learn more: urgent-challenge.github.io/urgent2025/
Join the Universal, Robust, & Generalizable Speech EnhancemeNT (URGENT) challenge! Explore noisy corpora, tackle diverse speech degradations, and test scalability across 2 tracks (~2.5k/60k hrs).
🚀 Learn more: urgent-challenge.github.io/urgent2025/

December 6, 2024 at 12:37 PM
🌟 URGENT Challenge @ #Interspeech2025 🌟
Join the Universal, Robust, & Generalizable Speech EnhancemeNT (URGENT) challenge! Explore noisy corpora, tackle diverse speech degradations, and test scalability across 2 tracks (~2.5k/60k hrs).
🚀 Learn more: urgent-challenge.github.io/urgent2025/
Join the Universal, Robust, & Generalizable Speech EnhancemeNT (URGENT) challenge! Explore noisy corpora, tackle diverse speech degradations, and test scalability across 2 tracks (~2.5k/60k hrs).
🚀 Learn more: urgent-challenge.github.io/urgent2025/
Reposted by Faro Stöter

new paper! 🗣️Sketch2Sound💥
Sketch2Sound can create sounds from sonic imitations (i.e., a vocal imitation or a reference sound) via interpretable, time-varying control signals.
paper: arxiv.org/abs/2412.08550
web: hugofloresgarcia.art/sketch2sound
Sketch2Sound can create sounds from sonic imitations (i.e., a vocal imitation or a reference sound) via interpretable, time-varying control signals.
paper: arxiv.org/abs/2412.08550
web: hugofloresgarcia.art/sketch2sound
December 12, 2024 at 2:43 PM
new paper! 🗣️Sketch2Sound💥
Sketch2Sound can create sounds from sonic imitations (i.e., a vocal imitation or a reference sound) via interpretable, time-varying control signals.
paper: arxiv.org/abs/2412.08550
web: hugofloresgarcia.art/sketch2sound
Sketch2Sound can create sounds from sonic imitations (i.e., a vocal imitation or a reference sound) via interpretable, time-varying control signals.
paper: arxiv.org/abs/2412.08550
web: hugofloresgarcia.art/sketch2sound
Reposted by Faro Stöter

📢 Audio AI Job opportunity at Adobe!
The Sound Design AI Group (SODA) is looking for an exceptional research engineer to join us in building the future of AI-assisted audio and video creation.
Strong ML background, GenAI experience a plus.
Details: adobe.wd5.myworkdayjobs.com/external_exp...
The Sound Design AI Group (SODA) is looking for an exceptional research engineer to join us in building the future of AI-assisted audio and video creation.
Strong ML background, GenAI experience a plus.
Details: adobe.wd5.myworkdayjobs.com/external_exp...
December 9, 2024 at 7:00 PM
📢 Audio AI Job opportunity at Adobe!
The Sound Design AI Group (SODA) is looking for an exceptional research engineer to join us in building the future of AI-assisted audio and video creation.
Strong ML background, GenAI experience a plus.
Details: adobe.wd5.myworkdayjobs.com/external_exp...
The Sound Design AI Group (SODA) is looking for an exceptional research engineer to join us in building the future of AI-assisted audio and video creation.
Strong ML background, GenAI experience a plus.
Details: adobe.wd5.myworkdayjobs.com/external_exp...
Reposted by Faro Stöter

🚨🚨My team @GoogleDeepMind in Tokyo is looking for a talented research scientist to work on audio generative models! 🔊
Please consider applying if you have expertise in the domain or related areas such as multimodal models, video generation 📹, etc.
boards.greenhouse.io/deepmind/job...
Please consider applying if you have expertise in the domain or related areas such as multimodal models, video generation 📹, etc.
boards.greenhouse.io/deepmind/job...

DeepMind
boards.greenhouse.io
December 6, 2024 at 7:09 AM
🚨🚨My team @GoogleDeepMind in Tokyo is looking for a talented research scientist to work on audio generative models! 🔊
Please consider applying if you have expertise in the domain or related areas such as multimodal models, video generation 📹, etc.
boards.greenhouse.io/deepmind/job...
Please consider applying if you have expertise in the domain or related areas such as multimodal models, video generation 📹, etc.
boards.greenhouse.io/deepmind/job...
€700M and not even generative? Doesn’t seem like a good investment.
www.theguardian.com/world/2024/n...
www.theguardian.com/world/2024/n...

Notre Dame reopening offers ‘shock of hope’, says Emmanuel Macron
French president tours medieval cathedral in Paris to view restoration after devastating 2019 fire
www.theguardian.com
December 7, 2024 at 9:22 AM
€700M and not even generative? Doesn’t seem like a good investment.
www.theguardian.com/world/2024/n...
www.theguardian.com/world/2024/n...
Reposted by Faro Stöter

🎓Academia or the industry 💸? I wrote a detailed point of view on Twitter a few months ago, so maybe I should share it here again. I think that most things are still true, the only slight change would be linked to the GenAI bubble, but only time will tell.
www.darnault-parcollet.fr/documents/Ba...
www.darnault-parcollet.fr/documents/Ba...
www.darnault-parcollet.fr
December 1, 2024 at 9:03 AM
🎓Academia or the industry 💸? I wrote a detailed point of view on Twitter a few months ago, so maybe I should share it here again. I think that most things are still true, the only slight change would be linked to the GenAI bubble, but only time will tell.
www.darnault-parcollet.fr/documents/Ba...
www.darnault-parcollet.fr/documents/Ba...
Reposted by Faro Stöter

The Reality for AI Startups
December 1, 2024 at 12:59 AM
The Reality for AI Startups
Reposted by Faro Stöter

Here’s the most charitable reading I can offer:
The tech barons behaved as though they were atop a social hierarchy, and expected mass adoration for their generosity+forgiveness for mistakes.
Instead, Elizabeth Warren, Lina Khan et al treated them like the heads of *massive corporations.*
The tech barons behaved as though they were atop a social hierarchy, and expected mass adoration for their generosity+forgiveness for mistakes.
Instead, Elizabeth Warren, Lina Khan et al treated them like the heads of *massive corporations.*

November 30, 2024 at 1:26 AM
Here’s the most charitable reading I can offer:
The tech barons behaved as though they were atop a social hierarchy, and expected mass adoration for their generosity+forgiveness for mistakes.
Instead, Elizabeth Warren, Lina Khan et al treated them like the heads of *massive corporations.*
The tech barons behaved as though they were atop a social hierarchy, and expected mass adoration for their generosity+forgiveness for mistakes.
Instead, Elizabeth Warren, Lina Khan et al treated them like the heads of *massive corporations.*
Reposted by Faro Stöter

🤖👂🎶 > Towards Improved Objective Perceptual Audio Quality Assessment -- Part 1: A Novel Data-Driven Cognitive Model arxiv.org/abs/2411.18222

Towards Improved Objective Perceptual Audio Quality Assessment -- Part 1: A Novel Data-Driven Cognitive Model
Efficient audio quality assessment is vital for streamlining audio codec development. Objective assessment tools have been developed over time to algorithmically predict quality ratings from subjectiv...
arxiv.org
November 28, 2024 at 7:24 AM
🤖👂🎶 > Towards Improved Objective Perceptual Audio Quality Assessment -- Part 1: A Novel Data-Driven Cognitive Model arxiv.org/abs/2411.18222
Reposted by Faro Stöter

For those of you who haven't yet, give scholar-inbox.com a try! It's a free personal paper recommender which helps you stay up-to-date by sending daily/weekly paper digests directly to your inbox. Your votes train your own classifier, and you can have a peek at its feature words. Here are mine!

November 24, 2024 at 4:09 PM
For those of you who haven't yet, give scholar-inbox.com a try! It's a free personal paper recommender which helps you stay up-to-date by sending daily/weekly paper digests directly to your inbox. Your votes train your own classifier, and you can have a peek at its feature words. Here are mine!