



Edd
@erlandpg.bsky.social
Very cool found from Unsloth team as always 🫡

Introducing Unsloth Dynamic 4-bit Quantization!
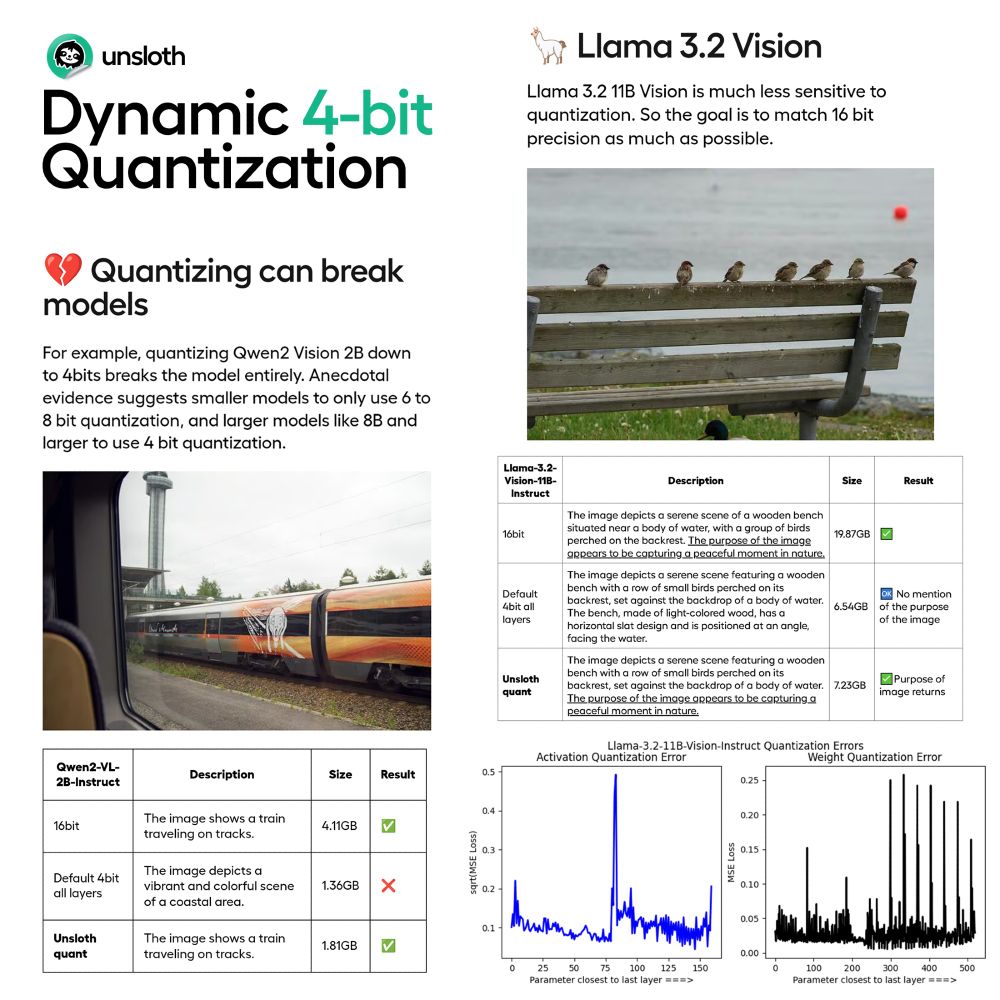
Naive quantization often harms accuracy but we avoid quantizing certain parameters. This achieves higher accuracy using only <10% more VRAM than BnB 4bit
Read our Blog: unsloth.ai/blog/dynamic...
Quants on Hugging Face: huggingface.co/collections/...
Naive quantization often harms accuracy but we avoid quantizing certain parameters. This achieves higher accuracy using only <10% more VRAM than BnB 4bit
Read our Blog: unsloth.ai/blog/dynamic...
Quants on Hugging Face: huggingface.co/collections/...
December 4, 2024 at 7:53 PM
Very cool found from Unsloth team as always 🫡
Reposted by Edd


GitHub - villasv/ssh-artwork
Contribute to villasv/ssh-artwork development by creating an account on GitHub.
github.com
November 27, 2024 at 12:02 PM
Reposted by Edd

I'm looking for an intern!
If you are:
* Driven
* Love OSS
* Interested in distributed PyTorch training/FSDPv2/DeepSpeed
Come work with me!
Fully remote, more details to apply in the comments
If you are:
* Driven
* Love OSS
* Interested in distributed PyTorch training/FSDPv2/DeepSpeed
Come work with me!
Fully remote, more details to apply in the comments

November 26, 2024 at 4:01 PM
I'm looking for an intern!
If you are:
* Driven
* Love OSS
* Interested in distributed PyTorch training/FSDPv2/DeepSpeed
Come work with me!
Fully remote, more details to apply in the comments
If you are:
* Driven
* Love OSS
* Interested in distributed PyTorch training/FSDPv2/DeepSpeed
Come work with me!
Fully remote, more details to apply in the comments
Reposted by Edd

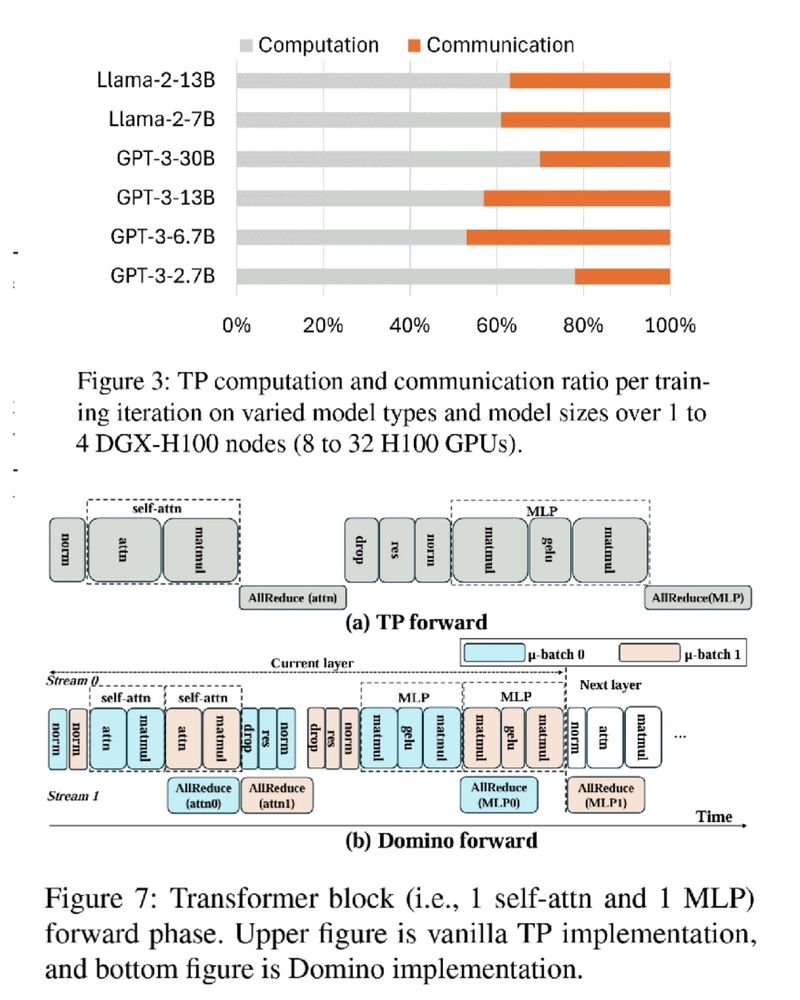
🚨 GPUs wasting 75% of training time on communication 🤯 Not anymore!
DeepSpeed Domino, with a new tensor parallelism engine, minimizes communication overhead for faster LLM training. 🚀
✅ Near-complete communication hiding
✅ Multi-node scalable solution
Blog: github.com/microsoft/De...
DeepSpeed Domino, with a new tensor parallelism engine, minimizes communication overhead for faster LLM training. 🚀
✅ Near-complete communication hiding
✅ Multi-node scalable solution
Blog: github.com/microsoft/De...
November 26, 2024 at 2:35 PM
🚨 GPUs wasting 75% of training time on communication 🤯 Not anymore!
DeepSpeed Domino, with a new tensor parallelism engine, minimizes communication overhead for faster LLM training. 🚀
✅ Near-complete communication hiding
✅ Multi-node scalable solution
Blog: github.com/microsoft/De...
DeepSpeed Domino, with a new tensor parallelism engine, minimizes communication overhead for faster LLM training. 🚀
✅ Near-complete communication hiding
✅ Multi-node scalable solution
Blog: github.com/microsoft/De...
Reposted by Edd

Releasing SmolVLM, a small 2 billion parameters Vision+Language Model (VLM) built for on-device/in-browser inference with images/videos.
Outperforms all models at similar GPU RAM usage and tokens throughputs
Blog post: huggingface.co/blog/smolvlm
Outperforms all models at similar GPU RAM usage and tokens throughputs
Blog post: huggingface.co/blog/smolvlm

November 26, 2024 at 4:58 PM
Releasing SmolVLM, a small 2 billion parameters Vision+Language Model (VLM) built for on-device/in-browser inference with images/videos.
Outperforms all models at similar GPU RAM usage and tokens throughputs
Blog post: huggingface.co/blog/smolvlm
Outperforms all models at similar GPU RAM usage and tokens throughputs
Blog post: huggingface.co/blog/smolvlm
I use Bookmarks features a lot on the other platforms. Can we get one here too? .-.
November 25, 2024 at 6:40 PM
I use Bookmarks features a lot on the other platforms. Can we get one here too? .-.
Reposted by Edd

Very good read from Aidan McLau on the other site about o1-style "reasoning models," what their limits are, and why they aren't as good at general language tasks: aidanmclaughlin.notion.site/reasoners-pr...

November 25, 2024 at 6:14 PM
Very good read from Aidan McLau on the other site about o1-style "reasoning models," what their limits are, and why they aren't as good at general language tasks: aidanmclaughlin.notion.site/reasoners-pr...
Reposted by Edd

the BigVision repo is my current reference impl for gemma and ViT. such an underrated repo @giffmana.bsky.social and team are doing the lord's work
github.com/google-resea...
github.com/google-resea...
github.com/google-resea...
github.com/google-resea...
big_vision/big_vision/models/ppp/gemma.py at main · google-research/big_vision
Official codebase used to develop Vision Transformer, SigLIP, MLP-Mixer, LiT and more. - google-research/big_vision
github.com
November 24, 2024 at 5:25 PM
the BigVision repo is my current reference impl for gemma and ViT. such an underrated repo @giffmana.bsky.social and team are doing the lord's work
github.com/google-resea...
github.com/google-resea...
github.com/google-resea...
github.com/google-resea...
Reposted by Edd

distributed learning for LLM?
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵

November 25, 2024 at 12:02 PM
distributed learning for LLM?
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵
Reposted by Edd
very interesting work and it reminds me a bit of this paper. Tokenizers and ROPE must die. after samplers, i am on to those next ...
arxiv.org/abs/2407.036...
arxiv.org/abs/2407.036...
November 25, 2024 at 2:20 AM
very interesting work and it reminds me a bit of this paper. Tokenizers and ROPE must die. after samplers, i am on to those next ...
arxiv.org/abs/2407.036...
arxiv.org/abs/2407.036...
Reposted by Edd
Adaptive Decoding via Latent Preference Optimization: arxiv.org/abs/2411.09661
* Add a small MLP + classifier which predict a temperature per token
* They train the MLP with a variant of DPO (arxiv.org/abs/2305.18290) with the temperatures as latent
* low temp for math, high for creative tasks
* Add a small MLP + classifier which predict a temperature per token
* They train the MLP with a variant of DPO (arxiv.org/abs/2305.18290) with the temperatures as latent
* low temp for math, high for creative tasks

November 25, 2024 at 11:06 AM
Adaptive Decoding via Latent Preference Optimization: arxiv.org/abs/2411.09661
* Add a small MLP + classifier which predict a temperature per token
* They train the MLP with a variant of DPO (arxiv.org/abs/2305.18290) with the temperatures as latent
* low temp for math, high for creative tasks
* Add a small MLP + classifier which predict a temperature per token
* They train the MLP with a variant of DPO (arxiv.org/abs/2305.18290) with the temperatures as latent
* low temp for math, high for creative tasks
Reposted by Edd

I wrote this code to follow the same people someone else is following. I figured that would fix my feed esp if someone is having a good experience I can just "have what they are having"
gist.github.com/hamelsmu/fb9...
gist.github.com/hamelsmu/fb9...

"I'll have what they are having" for bluesky. The motiviation is to mimic who someone else is following who reports they are having a good experience on bluesky!
"I'll have what they are having" for bluesky. The motiviation is to mimic who someone else is following who reports they are having a good experience on bluesky! - follow_theirs.py
gist.github.com
November 24, 2024 at 3:37 PM
I wrote this code to follow the same people someone else is following. I figured that would fix my feed esp if someone is having a good experience I can just "have what they are having"
gist.github.com/hamelsmu/fb9...
gist.github.com/hamelsmu/fb9...
Reposted by Edd
now that people are paying attention again, here is your periodic reminder. Always run in bf16. always apply ROPE and attention softmax at float32 (as shown here)
github.com/xjdr-alt/ent...
github.com/xjdr-alt/ent...

November 24, 2024 at 5:23 PM
now that people are paying attention again, here is your periodic reminder. Always run in bf16. always apply ROPE and attention softmax at float32 (as shown here)
github.com/xjdr-alt/ent...
github.com/xjdr-alt/ent...
Reposted by Edd

ADAM's been tuned but SOAP and PSGD just using default params, you love to see it.

November 24, 2024 at 11:36 PM
ADAM's been tuned but SOAP and PSGD just using default params, you love to see it.