



Arthur Douillard
@douillard.bsky.social
distributed (diloco) + modularity (dipaco) + llm @ deepmind | continual learning phd @ sorbonne
one more step towards decentralized learning: Eager Updates
can we overlap communication with computation over hundred of steps?
-- yes we can
in this work led by @SatyenKale, we improve DiLoCo and use x1177 less bandwidth than data-parallel
can we overlap communication with computation over hundred of steps?
-- yes we can
in this work led by @SatyenKale, we improve DiLoCo and use x1177 less bandwidth than data-parallel




February 19, 2025 at 5:41 PM
one more step towards decentralized learning: Eager Updates
can we overlap communication with computation over hundred of steps?
-- yes we can
in this work led by @SatyenKale, we improve DiLoCo and use x1177 less bandwidth than data-parallel
can we overlap communication with computation over hundred of steps?
-- yes we can
in this work led by @SatyenKale, we improve DiLoCo and use x1177 less bandwidth than data-parallel
from Jeff Dean at The Dwarkesh podcast:
"asynchronous training where each copy of the model does local computation [...] it makes people uncomfortable [...] but it actually works"
yep, i can confirm, it does work for real
see arxiv.org/abs/2501.18512
"asynchronous training where each copy of the model does local computation [...] it makes people uncomfortable [...] but it actually works"
yep, i can confirm, it does work for real
see arxiv.org/abs/2501.18512
February 16, 2025 at 6:53 PM
from Jeff Dean at The Dwarkesh podcast:
"asynchronous training where each copy of the model does local computation [...] it makes people uncomfortable [...] but it actually works"
yep, i can confirm, it does work for real
see arxiv.org/abs/2501.18512
"asynchronous training where each copy of the model does local computation [...] it makes people uncomfortable [...] but it actually works"
yep, i can confirm, it does work for real
see arxiv.org/abs/2501.18512
Reposted by Arthur Douillard

We received an outstanding interest in our #ICLR2025 @iclr-conf.bsky.social workshop on modularity! Please sign up to serve as a reviewer if you are interested in Model Merging, MoEs, and Routing, for Decentralized and Collaborative Learning t.co/HIsZKWNaOx

February 14, 2025 at 2:09 PM
We received an outstanding interest in our #ICLR2025 @iclr-conf.bsky.social workshop on modularity! Please sign up to serve as a reviewer if you are interested in Model Merging, MoEs, and Routing, for Decentralized and Collaborative Learning t.co/HIsZKWNaOx
We release today the next step for distributed training:
--> Streaming DiLoCo with Overlapping Communication.
TL;DR: train data-parallel across the world with low-bandwidth for the same performance: 400x less bits exchanged & huge latency tolerance
--> Streaming DiLoCo with Overlapping Communication.
TL;DR: train data-parallel across the world with low-bandwidth for the same performance: 400x less bits exchanged & huge latency tolerance




January 31, 2025 at 1:35 PM
We release today the next step for distributed training:
--> Streaming DiLoCo with Overlapping Communication.
TL;DR: train data-parallel across the world with low-bandwidth for the same performance: 400x less bits exchanged & huge latency tolerance
--> Streaming DiLoCo with Overlapping Communication.
TL;DR: train data-parallel across the world with low-bandwidth for the same performance: 400x less bits exchanged & huge latency tolerance
Reposted by Arthur Douillard

Introducing playground.mujoco.org
Combining MuJoCo’s rich and thriving ecosystem, massively parallel GPU-accelerated simulation, and real-world results across a diverse range of robot platforms: quadrupeds, humanoids, dexterous hands, and arms.
Get started today: pip install playground
Combining MuJoCo’s rich and thriving ecosystem, massively parallel GPU-accelerated simulation, and real-world results across a diverse range of robot platforms: quadrupeds, humanoids, dexterous hands, and arms.
Get started today: pip install playground

MuJoCo Playground
An open-source framework for GPU-accelerated robot learning and sim-to-real transfer
playground.mujoco.org
January 16, 2025 at 8:48 PM
Introducing playground.mujoco.org
Combining MuJoCo’s rich and thriving ecosystem, massively parallel GPU-accelerated simulation, and real-world results across a diverse range of robot platforms: quadrupeds, humanoids, dexterous hands, and arms.
Get started today: pip install playground
Combining MuJoCo’s rich and thriving ecosystem, massively parallel GPU-accelerated simulation, and real-world results across a diverse range of robot platforms: quadrupeds, humanoids, dexterous hands, and arms.
Get started today: pip install playground
Reposted by Arthur Douillard

In December, I posted about our new paper on mastering board games using internal + external planning. 👇
Here's a talk now on Youtube about it given by my awesome colleague John Schultz!
www.youtube.com/watch?v=JyxE...
Here's a talk now on Youtube about it given by my awesome colleague John Schultz!
www.youtube.com/watch?v=JyxE...
January 17, 2025 at 5:26 PM
In December, I posted about our new paper on mastering board games using internal + external planning. 👇
Here's a talk now on Youtube about it given by my awesome colleague John Schultz!
www.youtube.com/watch?v=JyxE...
Here's a talk now on Youtube about it given by my awesome colleague John Schultz!
www.youtube.com/watch?v=JyxE...
Reposted by Arthur Douillard

🚀Excited to co-organize the #ICLR2025 Workshop on Modularity for Collaborative, Decentralized, and Continual Deep Learning (MCDC @iclr-conf.bsky.social).
📃 Submission Portal: openreview.net/group?id=ICL...
🤗See you in Singapore!
For more details, check out the original thread ↪️🧵
📃 Submission Portal: openreview.net/group?id=ICL...
🤗See you in Singapore!
For more details, check out the original thread ↪️🧵
January 16, 2025 at 4:00 PM
🚀Excited to co-organize the #ICLR2025 Workshop on Modularity for Collaborative, Decentralized, and Continual Deep Learning (MCDC @iclr-conf.bsky.social).
📃 Submission Portal: openreview.net/group?id=ICL...
🤗See you in Singapore!
For more details, check out the original thread ↪️🧵
📃 Submission Portal: openreview.net/group?id=ICL...
🤗See you in Singapore!
For more details, check out the original thread ↪️🧵
Workshop alert 🚨
We'll host in ICLR 2025 (late April) a workshop on modularity, encompassing collaborative + decentralized + continual learning.
Those topics are on the critical path to building better AIs.
Interested? submit a paper and join us in Singapore!
sites.google.com/corp/view/mc...
We'll host in ICLR 2025 (late April) a workshop on modularity, encompassing collaborative + decentralized + continual learning.
Those topics are on the critical path to building better AIs.
Interested? submit a paper and join us in Singapore!
sites.google.com/corp/view/mc...

January 16, 2025 at 11:34 AM
Workshop alert 🚨
We'll host in ICLR 2025 (late April) a workshop on modularity, encompassing collaborative + decentralized + continual learning.
Those topics are on the critical path to building better AIs.
Interested? submit a paper and join us in Singapore!
sites.google.com/corp/view/mc...
We'll host in ICLR 2025 (late April) a workshop on modularity, encompassing collaborative + decentralized + continual learning.
Those topics are on the critical path to building better AIs.
Interested? submit a paper and join us in Singapore!
sites.google.com/corp/view/mc...

PrimeIntellect have released their tech report on INTELLECT-1: t.co/8hnoTILaL3
The first open-source world-wide training of a 10B model. The underlying ML distributed algo is DiLoCo (arxiv.org/abs/2311.08105) but they also built tons of engineering on top of it to make it scalable.
The first open-source world-wide training of a 10B model. The underlying ML distributed algo is DiLoCo (arxiv.org/abs/2311.08105) but they also built tons of engineering on top of it to make it scalable.

December 1, 2024 at 10:10 AM
PrimeIntellect have released their tech report on INTELLECT-1: t.co/8hnoTILaL3
The first open-source world-wide training of a 10B model. The underlying ML distributed algo is DiLoCo (arxiv.org/abs/2311.08105) but they also built tons of engineering on top of it to make it scalable.
The first open-source world-wide training of a 10B model. The underlying ML distributed algo is DiLoCo (arxiv.org/abs/2311.08105) but they also built tons of engineering on top of it to make it scalable.
Awesome video on speculations for test-time scaling (O1 👀 ):

Speculations on Test-Time Scaling (o1)
Tutorial on the technical background behind OpenAI o1. Talk written with Daniel Ritter.Slides: https://github.com/srush/awesome-o1Talk: The “large” in LLM is...
www.youtube.com
November 30, 2024 at 11:06 AM
Awesome video on speculations for test-time scaling (O1 👀 ):
Excellent explanation of RoPE embedding, from scratch with all the math needed: https://fleetwood.dev/posts/you-could-have-designed-SOTA-positional-encoding
And with beautiful 3blue1brown's style of animation: https://github.com/3b1b/manim.
Original RoPE paper: arxiv.org/abs/2104.09864
And with beautiful 3blue1brown's style of animation: https://github.com/3b1b/manim.
Original RoPE paper: arxiv.org/abs/2104.09864

November 29, 2024 at 1:45 PM
Excellent explanation of RoPE embedding, from scratch with all the math needed: https://fleetwood.dev/posts/you-could-have-designed-SOTA-positional-encoding
And with beautiful 3blue1brown's style of animation: https://github.com/3b1b/manim.
Original RoPE paper: arxiv.org/abs/2104.09864
And with beautiful 3blue1brown's style of animation: https://github.com/3b1b/manim.
Original RoPE paper: arxiv.org/abs/2104.09864
I need to take holidays to read all my saved arXivs
November 28, 2024 at 11:25 AM
I need to take holidays to read all my saved arXivs
Distributed Decentralized Training of Neural Networks: A Primer:
towardsdatascience.com/distributed-decentralized-training-of-neural-networks-a-primer-21e5e961fce1
DP's AllReduce, variants thereof + advanced methods as SWARM (arxiv.org/abs/2301.11913) and DiLoCo (arxiv.org/abs/2311.08105 )
towardsdatascience.com/distributed-decentralized-training-of-neural-networks-a-primer-21e5e961fce1
DP's AllReduce, variants thereof + advanced methods as SWARM (arxiv.org/abs/2301.11913) and DiLoCo (arxiv.org/abs/2311.08105 )

Distributed Decentralized Training of Neural Networks: A Primer
Data Parallelism, Butterfly All-Reduce, Gossiping and More…
towardsdatascience.com
November 28, 2024 at 11:06 AM
Distributed Decentralized Training of Neural Networks: A Primer:
towardsdatascience.com/distributed-decentralized-training-of-neural-networks-a-primer-21e5e961fce1
DP's AllReduce, variants thereof + advanced methods as SWARM (arxiv.org/abs/2301.11913) and DiLoCo (arxiv.org/abs/2311.08105 )
towardsdatascience.com/distributed-decentralized-training-of-neural-networks-a-primer-21e5e961fce1
DP's AllReduce, variants thereof + advanced methods as SWARM (arxiv.org/abs/2301.11913) and DiLoCo (arxiv.org/abs/2311.08105 )
LLMs Know More Than They Show: arxiv.org/abs/2410.02707
* Adding a true-seeking classifier probe on the token embeddings can have better performance than the actual generation
* Is something wrong going on in the decoding part?
* Those error detectors don't generalize across datasets
* Adding a true-seeking classifier probe on the token embeddings can have better performance than the actual generation
* Is something wrong going on in the decoding part?
* Those error detectors don't generalize across datasets

November 27, 2024 at 11:06 AM
LLMs Know More Than They Show: arxiv.org/abs/2410.02707
* Adding a true-seeking classifier probe on the token embeddings can have better performance than the actual generation
* Is something wrong going on in the decoding part?
* Those error detectors don't generalize across datasets
* Adding a true-seeking classifier probe on the token embeddings can have better performance than the actual generation
* Is something wrong going on in the decoding part?
* Those error detectors don't generalize across datasets
Reposted by Arthur Douillard

New essay by DeepMind about AI for scientific discovery, there's a lot of interesting ideas and citations to others's work here
deepmind.google/public-polic...
deepmind.google/public-polic...

A new golden age of discovery
In this essay, we take a tour of how AI is transforming scientific disciplines from genomics to computer science to weather forecasting. Some scientists are training their own AI models, while...
deepmind.google
November 26, 2024 at 2:13 PM
New essay by DeepMind about AI for scientific discovery, there's a lot of interesting ideas and citations to others's work here
deepmind.google/public-polic...
deepmind.google/public-polic...
Secret Collusion among Generative AI Agents: arxiv.org/abs/2402.07510
LLMs are prone to collude when they know they cannot be "caught"
LLMs are prone to collude when they know they cannot be "caught"

November 26, 2024 at 10:58 AM
Secret Collusion among Generative AI Agents: arxiv.org/abs/2402.07510
LLMs are prone to collude when they know they cannot be "caught"
LLMs are prone to collude when they know they cannot be "caught"
Reposted by Arthur Douillard

Our group at Google DeepMind is now accepting intern applications for summer 2025. Attached is the official "call for interns" email; the links and email aliases that got lost in the screenshot are below.

November 25, 2024 at 9:55 PM
Our group at Google DeepMind is now accepting intern applications for summer 2025. Attached is the official "call for interns" email; the links and email aliases that got lost in the screenshot are below.
Reposted by Arthur Douillard

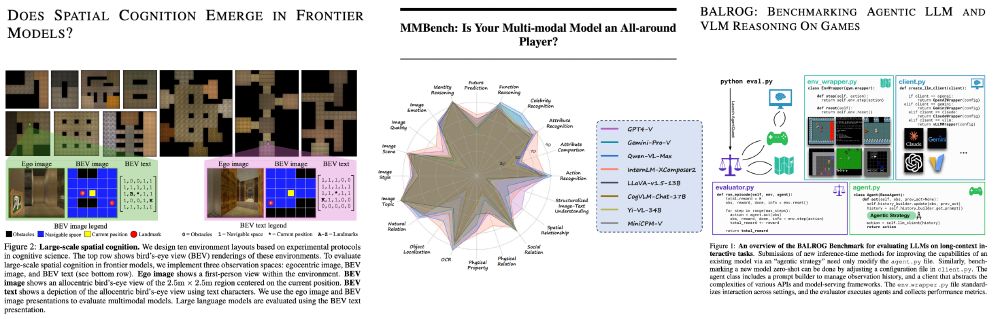
There are now several benchmarks testing spatial reasoning and agent capabilities of LLMs and VLMs:
- arxiv.org/abs/2410.06468 (does spatial cognition ...)
- arxiv.org/abs/2307.06281 (MMBench)
- arxiv.org/abs/2411.13543 (BALROG) - additional points for the LOTR ref.
- arxiv.org/abs/2410.06468 (does spatial cognition ...)
- arxiv.org/abs/2307.06281 (MMBench)
- arxiv.org/abs/2411.13543 (BALROG) - additional points for the LOTR ref.
November 24, 2024 at 5:19 PM
There are now several benchmarks testing spatial reasoning and agent capabilities of LLMs and VLMs:
- arxiv.org/abs/2410.06468 (does spatial cognition ...)
- arxiv.org/abs/2307.06281 (MMBench)
- arxiv.org/abs/2411.13543 (BALROG) - additional points for the LOTR ref.
- arxiv.org/abs/2410.06468 (does spatial cognition ...)
- arxiv.org/abs/2307.06281 (MMBench)
- arxiv.org/abs/2411.13543 (BALROG) - additional points for the LOTR ref.
Reposted by Arthur Douillard

Great thread to summarize the history of distributed learning, from the Federated Learning to prime intellect's OpenDiLoCo
distributed learning for LLM?
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵

November 25, 2024 at 2:48 PM
Great thread to summarize the history of distributed learning, from the Federated Learning to prime intellect's OpenDiLoCo
distributed learning for LLM?
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵
November 25, 2024 at 12:02 PM
distributed learning for LLM?
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵
Adaptive Decoding via Latent Preference Optimization: arxiv.org/abs/2411.09661
* Add a small MLP + classifier which predict a temperature per token
* They train the MLP with a variant of DPO (arxiv.org/abs/2305.18290) with the temperatures as latent
* low temp for math, high for creative tasks
* Add a small MLP + classifier which predict a temperature per token
* They train the MLP with a variant of DPO (arxiv.org/abs/2305.18290) with the temperatures as latent
* low temp for math, high for creative tasks

November 25, 2024 at 11:06 AM
Adaptive Decoding via Latent Preference Optimization: arxiv.org/abs/2411.09661
* Add a small MLP + classifier which predict a temperature per token
* They train the MLP with a variant of DPO (arxiv.org/abs/2305.18290) with the temperatures as latent
* low temp for math, high for creative tasks
* Add a small MLP + classifier which predict a temperature per token
* They train the MLP with a variant of DPO (arxiv.org/abs/2305.18290) with the temperatures as latent
* low temp for math, high for creative tasks
Reposted by Arthur Douillard

We have multiple roles now open in my Responsible Research Group!
Research Scientist on the HEART team led by IasonGabriel: boards.greenhouse.io/deepmind/job...
Research Engineer on the SAMBA team led by Kristian Lum: boards.greenhouse.io/deepmind/job...
Research Scientist on the HEART team led by IasonGabriel: boards.greenhouse.io/deepmind/job...
Research Engineer on the SAMBA team led by Kristian Lum: boards.greenhouse.io/deepmind/job...

DeepMind
boards.greenhouse.io
November 22, 2024 at 9:59 PM
We have multiple roles now open in my Responsible Research Group!
Research Scientist on the HEART team led by IasonGabriel: boards.greenhouse.io/deepmind/job...
Research Engineer on the SAMBA team led by Kristian Lum: boards.greenhouse.io/deepmind/job...
Research Scientist on the HEART team led by IasonGabriel: boards.greenhouse.io/deepmind/job...
Research Engineer on the SAMBA team led by Kristian Lum: boards.greenhouse.io/deepmind/job...
Reposted by Arthur Douillard

Excited to announce "BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games" led b UCL DARK's @dpaglieri.bsky.social! Douwe Kiela plot below is maybe the scariest for AI progress — LLM benchmarks are saturating at an accelerating rate. BALROG to the rescue. This will keep us busy for years.

November 22, 2024 at 11:27 AM
Excited to announce "BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games" led b UCL DARK's @dpaglieri.bsky.social! Douwe Kiela plot below is maybe the scariest for AI progress — LLM benchmarks are saturating at an accelerating rate. BALROG to the rescue. This will keep us busy for years.
Top-nσ: arxiv.org/abs/2411.07641
Similar to min-p (arxiv.org/abs/2407.01082), aims to cut too low probs for sampling.
while min-p is based on a % threshold of the max prob, Top-nσ notes that logits follow a gaussian, and aims to cut logits further than n-sigma away
Similar to min-p (arxiv.org/abs/2407.01082), aims to cut too low probs for sampling.
while min-p is based on a % threshold of the max prob, Top-nσ notes that logits follow a gaussian, and aims to cut logits further than n-sigma away

November 22, 2024 at 11:06 AM
Top-nσ: arxiv.org/abs/2411.07641
Similar to min-p (arxiv.org/abs/2407.01082), aims to cut too low probs for sampling.
while min-p is based on a % threshold of the max prob, Top-nσ notes that logits follow a gaussian, and aims to cut logits further than n-sigma away
Similar to min-p (arxiv.org/abs/2407.01082), aims to cut too low probs for sampling.
while min-p is based on a % threshold of the max prob, Top-nσ notes that logits follow a gaussian, and aims to cut logits further than n-sigma away