



Clément Dumas
@butanium.bsky.social
Master student at ENS Paris-Saclay / aspiring AI safety researcher / improviser
Prev research intern @ EPFL w/ wendlerc.bsky.social and Robert West
MATS Winter 7.0 Scholar w/ neelnanda.bsky.social
https://butanium.github.io
Prev research intern @ EPFL w/ wendlerc.bsky.social and Robert West
MATS Winter 7.0 Scholar w/ neelnanda.bsky.social
https://butanium.github.io
Pinned
Clément Dumas
@butanium.bsky.social
· Apr 7

New paper w/@jkminder.bsky.social & @neelnanda.bsky.social
What do chat LLMs learn in finetuning?
Anthropic introduced a tool for this: crosscoders, an SAE variant. We find key limitations of crosscoders & fix them with BatchTopK crosscoders
This finds interpretable and causal chat-only features!🧵
What do chat LLMs learn in finetuning?
Anthropic introduced a tool for this: crosscoders, an SAE variant. We find key limitations of crosscoders & fix them with BatchTopK crosscoders
This finds interpretable and causal chat-only features!🧵
Very cool analysis by Arnab which cover the mechanisms used for retrieval both when your query is before or after the text!

How can a language model find the veggies in a menu?
New pre-print where we investigate the internal mechanisms of LLMs when filtering on a list of options.
Spoiler: turns out LLMs use strategies surprisingly similar to functional programming (think "filter" from python)! 🧵
New pre-print where we investigate the internal mechanisms of LLMs when filtering on a list of options.
Spoiler: turns out LLMs use strategies surprisingly similar to functional programming (think "filter" from python)! 🧵

November 5, 2025 at 1:38 PM
Very cool analysis by Arnab which cover the mechanisms used for retrieval both when your query is before or after the text!
A very important paper led by Julian!
Tldr: we show that your Narrow Finetuning is showing and might not be a realistic setup to study!
Tldr: we show that your Narrow Finetuning is showing and might not be a realistic setup to study!

October 20, 2025 at 3:20 PM
A very important paper led by Julian!
Tldr: we show that your Narrow Finetuning is showing and might not be a realistic setup to study!
Tldr: we show that your Narrow Finetuning is showing and might not be a realistic setup to study!
To say it out loud: @jkminder.bsky.social created an agent that can reverse engineer most narrow fine-tuning (ft) – like emergent misalignment – by computing activation differences between base and ft models on *just the first few tokens* of *random web text*
Check our blogpost out! 🧵
Check our blogpost out! 🧵
Can we interpret what happens in finetuning? Yes, if for a narrow domain! Narrow fine tuning leaves traces behind. By comparing activations before and after fine-tuning we can interpret these, even with an agent! We interpret subliminal learning, emergent misalignment, and more

September 5, 2025 at 7:23 PM
To say it out loud: @jkminder.bsky.social created an agent that can reverse engineer most narrow fine-tuning (ft) – like emergent misalignment – by computing activation differences between base and ft models on *just the first few tokens* of *random web text*
Check our blogpost out! 🧵
Check our blogpost out! 🧵
Reposted by Clément Dumas

GPT is being asked to be both one mind and to also segment its understanding into many different minds, this incentivizes the model to learn to correct for its own perspective when mimicking the generator of individual texts so it doesn't know too much, to know self vs. other in minute detail.
August 29, 2025 at 1:59 AM
GPT is being asked to be both one mind and to also segment its understanding into many different minds, this incentivizes the model to learn to correct for its own perspective when mimicking the generator of individual texts so it doesn't know too much, to know self vs. other in minute detail.
Reposted by Clément Dumas
This Friday NEMI 2025 is at Northeastern in Boston, 8 talks, 24 roundtables, 90 posters; 200+ attendees. Thanks to
goodfire.ai/ for sponsoring! nemiconf.github.io/summer25/
If you can't make it in person, the livestream will be here:
www.youtube.com/live/4BJBis...
goodfire.ai/ for sponsoring! nemiconf.github.io/summer25/
If you can't make it in person, the livestream will be here:
www.youtube.com/live/4BJBis...

New England Mechanistic Interpretability Workshop
About:The New England Mechanistic Interpretability (NEMI) workshop aims to bring together academic and industry researchers from the New England and surround...
www.youtube.com
August 18, 2025 at 6:06 PM
This Friday NEMI 2025 is at Northeastern in Boston, 8 talks, 24 roundtables, 90 posters; 200+ attendees. Thanks to
goodfire.ai/ for sponsoring! nemiconf.github.io/summer25/
If you can't make it in person, the livestream will be here:
www.youtube.com/live/4BJBis...
goodfire.ai/ for sponsoring! nemiconf.github.io/summer25/
If you can't make it in person, the livestream will be here:
www.youtube.com/live/4BJBis...
Reposted by Clément Dumas

Excited to share our first paper replication tutorial, walking you through the main figures from "Do Language Models Use Their Depth Efficiently?" by @robertcsordas.bsky.social
🔎 Demo on Colab: colab.research.google.com/github/ndif-...
📖 Read the full manuscript: arxiv.org/abs/2505.13898
🔎 Demo on Colab: colab.research.google.com/github/ndif-...
📖 Read the full manuscript: arxiv.org/abs/2505.13898

Google Colab
colab.research.google.com
July 4, 2025 at 12:27 AM
Excited to share our first paper replication tutorial, walking you through the main figures from "Do Language Models Use Their Depth Efficiently?" by @robertcsordas.bsky.social
🔎 Demo on Colab: colab.research.google.com/github/ndif-...
📖 Read the full manuscript: arxiv.org/abs/2505.13898
🔎 Demo on Colab: colab.research.google.com/github/ndif-...
📖 Read the full manuscript: arxiv.org/abs/2505.13898
Reposted by Clément Dumas

With @butanium.bsky.social and @neelnanda.bsky.social we've just published a post on model diffing that extends our previous paper.
Rather than trying to reverse-engineer the full fine-tuned model, model diffing focuses on understanding what makes it different from its base model internally.
Rather than trying to reverse-engineer the full fine-tuned model, model diffing focuses on understanding what makes it different from its base model internally.

June 30, 2025 at 9:02 PM
With @butanium.bsky.social and @neelnanda.bsky.social we've just published a post on model diffing that extends our previous paper.
Rather than trying to reverse-engineer the full fine-tuned model, model diffing focuses on understanding what makes it different from its base model internally.
Rather than trying to reverse-engineer the full fine-tuned model, model diffing focuses on understanding what makes it different from its base model internally.
Our mech interp ICML workshop paper got accepted to ACL 2025 main! 🎉
In this updated version, we extended our results to several models and showed they can actually generate good definitions of mean concept representations across languages.🧵
In this updated version, we extended our results to several models and showed they can actually generate good definitions of mean concept representations across languages.🧵

Clément Dumas on X: "Excited to share our latest paper, accepted as a spotlight at the #ICML2024 mechanistic interpretability workshop! We find evidence that LLMs use language-agnostic representations of concepts 🧵↘️ https://t.co/dDS5iv199i" / X
Excited to share our latest paper, accepted as a spotlight at the #ICML2024 mechanistic interpretability workshop! We find evidence that LLMs use language-agnostic representations of concepts 🧵↘️ https://t.co/dDS5iv199i
x.com
June 29, 2025 at 11:07 PM
Our mech interp ICML workshop paper got accepted to ACL 2025 main! 🎉
In this updated version, we extended our results to several models and showed they can actually generate good definitions of mean concept representations across languages.🧵
In this updated version, we extended our results to several models and showed they can actually generate good definitions of mean concept representations across languages.🧵
Reposted by Clément Dumas

New alignment theory paper! We present a new scalable oversight protocol (prover-estimator debate) and a proof that honesty is incentivised at equilibrium (with large assumptions, see 🧵), even when the AIs involved have similar available compute.

June 17, 2025 at 4:52 PM
New alignment theory paper! We present a new scalable oversight protocol (prover-estimator debate) and a proof that honesty is incentivised at equilibrium (with large assumptions, see 🧵), even when the AIs involved have similar available compute.
We'll be presenting at the #ICLR sparsity in LLMs workshop today (Sunday 27th) at 4:30 pm in Hall 4 #7!
New paper w/@jkminder.bsky.social & @neelnanda.bsky.social
What do chat LLMs learn in finetuning?
Anthropic introduced a tool for this: crosscoders, an SAE variant. We find key limitations of crosscoders & fix them with BatchTopK crosscoders
This finds interpretable and causal chat-only features!🧵
What do chat LLMs learn in finetuning?
Anthropic introduced a tool for this: crosscoders, an SAE variant. We find key limitations of crosscoders & fix them with BatchTopK crosscoders
This finds interpretable and causal chat-only features!🧵
April 26, 2025 at 8:02 PM
We'll be presenting at the #ICLR sparsity in LLMs workshop today (Sunday 27th) at 4:30 pm in Hall 4 #7!
Want to explore cool chat related crosscoder latents?
With @jkminder.bsky.social, we made a demo that supports both loading our max activating examples AND running the crosscoder with your own prompt to collect the activations of specific latents!
Send us the cool latents you find! dub.sh/ccdm
With @jkminder.bsky.social, we made a demo that supports both loading our max activating examples AND running the crosscoder with your own prompt to collect the activations of specific latents!
Send us the cool latents you find! dub.sh/ccdm
April 9, 2025 at 10:48 PM
Want to explore cool chat related crosscoder latents?
With @jkminder.bsky.social, we made a demo that supports both loading our max activating examples AND running the crosscoder with your own prompt to collect the activations of specific latents!
Send us the cool latents you find! dub.sh/ccdm
With @jkminder.bsky.social, we made a demo that supports both loading our max activating examples AND running the crosscoder with your own prompt to collect the activations of specific latents!
Send us the cool latents you find! dub.sh/ccdm
Reposted by Clément Dumas
In our most recent work, we looked at how to best leverage crosscoders to identify representational differences between base and chat models. We find many cool things, e.g., a knowledge boundary, a detailed info and a humor/ joke detection latent.

April 7, 2025 at 5:56 PM
In our most recent work, we looked at how to best leverage crosscoders to identify representational differences between base and chat models. We find many cool things, e.g., a knowledge boundary, a detailed info and a humor/ joke detection latent.
New paper w/@jkminder.bsky.social & @neelnanda.bsky.social
What do chat LLMs learn in finetuning?
Anthropic introduced a tool for this: crosscoders, an SAE variant. We find key limitations of crosscoders & fix them with BatchTopK crosscoders
This finds interpretable and causal chat-only features!🧵
What do chat LLMs learn in finetuning?
Anthropic introduced a tool for this: crosscoders, an SAE variant. We find key limitations of crosscoders & fix them with BatchTopK crosscoders
This finds interpretable and causal chat-only features!🧵
April 7, 2025 at 4:21 PM
New paper w/@jkminder.bsky.social & @neelnanda.bsky.social
What do chat LLMs learn in finetuning?
Anthropic introduced a tool for this: crosscoders, an SAE variant. We find key limitations of crosscoders & fix them with BatchTopK crosscoders
This finds interpretable and causal chat-only features!🧵
What do chat LLMs learn in finetuning?
Anthropic introduced a tool for this: crosscoders, an SAE variant. We find key limitations of crosscoders & fix them with BatchTopK crosscoders
This finds interpretable and causal chat-only features!🧵
Very cool work that introduces "concept heads" that copy meanings from one token to another.
I love that our activation-based analysis of multilingual representation has now additional insight from weight space analysis: bsky.app/profile/sfeu...
I love that our activation-based analysis of multilingual representation has now additional insight from weight space analysis: bsky.app/profile/sfeu...

[📄] Are LLMs mindless token-shifters, or do they build meaningful representations of language? We study how LLMs copy text in-context, and physically separate out two types of induction heads: token heads, which copy literal tokens, and concept heads, which copy word meanings.
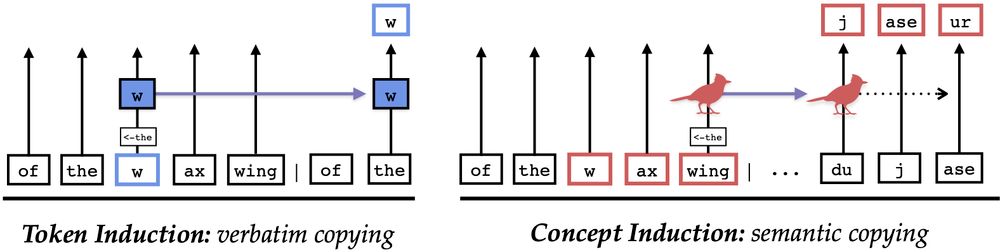
April 7, 2025 at 3:26 PM
Very cool work that introduces "concept heads" that copy meanings from one token to another.
I love that our activation-based analysis of multilingual representation has now additional insight from weight space analysis: bsky.app/profile/sfeu...
I love that our activation-based analysis of multilingual representation has now additional insight from weight space analysis: bsky.app/profile/sfeu...
Reposted by Clément Dumas

Want to get into alignment research? Alex Cloud & I mentor *Team Shard*, responsible for gradient routing, steering vectors, MELBO, and a new unlearning technique (TBA) :) We discover new research subfields.
Apply for mentorship this summer at forms.matsprogram.org/turner-app-8
Apply for mentorship this summer at forms.matsprogram.org/turner-app-8

March 20, 2025 at 4:14 PM
Want to get into alignment research? Alex Cloud & I mentor *Team Shard*, responsible for gradient routing, steering vectors, MELBO, and a new unlearning technique (TBA) :) We discover new research subfields.
Apply for mentorship this summer at forms.matsprogram.org/turner-app-8
Apply for mentorship this summer at forms.matsprogram.org/turner-app-8
Reposted by Clément Dumas

Excited about recent reasoning models? What is happening under the hood?
Join ARBOR: Analysis of Reasoning Behaviors thru *Open Research* - a radically open collaboration to reverse-engineer reasoning models!
Learn more: arborproject.github.io
1/N
Join ARBOR: Analysis of Reasoning Behaviors thru *Open Research* - a radically open collaboration to reverse-engineer reasoning models!
Learn more: arborproject.github.io
1/N
ARBOR
arborproject.github.io
February 20, 2025 at 7:55 PM
Excited about recent reasoning models? What is happening under the hood?
Join ARBOR: Analysis of Reasoning Behaviors thru *Open Research* - a radically open collaboration to reverse-engineer reasoning models!
Learn more: arborproject.github.io
1/N
Join ARBOR: Analysis of Reasoning Behaviors thru *Open Research* - a radically open collaboration to reverse-engineer reasoning models!
Learn more: arborproject.github.io
1/N
Reposted by Clément Dumas

As part of opening my new round of MATS applications, I took this as an excuse to write up which research discussions I'm currently just excited about, and recent updates I've made - I thought this might be of more general interest!
x.com/NeelNanda5/...
x.com/NeelNanda5/...

February 8, 2025 at 1:57 PM
As part of opening my new round of MATS applications, I took this as an excuse to write up which research discussions I'm currently just excited about, and recent updates I've made - I thought this might be of more general interest!
x.com/NeelNanda5/...
x.com/NeelNanda5/...
Reposted by Clément Dumas
LLM agents will be a very big deal, bringing many weird new forms of reward hacking and other subtle failures
This great GDM safety paper shows that myopically optimising for plans that an overseer approves of, rather than outcomes, reduces these issues while performing well!
x.com/davlindner/...
This great GDM safety paper shows that myopically optimising for plans that an overseer approves of, rather than outcomes, reduces these issues while performing well!
x.com/davlindner/...
January 23, 2025 at 4:36 PM
LLM agents will be a very big deal, bringing many weird new forms of reward hacking and other subtle failures
This great GDM safety paper shows that myopically optimising for plans that an overseer approves of, rather than outcomes, reduces these issues while performing well!
x.com/davlindner/...
This great GDM safety paper shows that myopically optimising for plans that an overseer approves of, rather than outcomes, reduces these issues while performing well!
x.com/davlindner/...
Reposted by Clément Dumas
Do you have a great experiment that you want to run on Llama 405b but not enough GPUs?
🚨 #NDIF is opening up more spots in our 405b pilot program! Apply now for a chance to conduct your own groundbreaking experiments on the 405b model. Details: 🧵⬇️
🚨 #NDIF is opening up more spots in our 405b pilot program! Apply now for a chance to conduct your own groundbreaking experiments on the 405b model. Details: 🧵⬇️
December 9, 2024 at 8:04 PM
Do you have a great experiment that you want to run on Llama 405b but not enough GPUs?
🚨 #NDIF is opening up more spots in our 405b pilot program! Apply now for a chance to conduct your own groundbreaking experiments on the 405b model. Details: 🧵⬇️
🚨 #NDIF is opening up more spots in our 405b pilot program! Apply now for a chance to conduct your own groundbreaking experiments on the 405b model. Details: 🧵⬇️
Reposted by Clément Dumas
Can we understand and control how language models balance context and prior knowledge? Our latest paper shows it’s all about a 1D knob! 🎛️
arxiv.org/abs/2411.07404
Co-led with
@kevdududu.bsky.social - @niklasstoehr.bsky.social , Giovanni Monea, @wendlerc.bsky.social, Robert West & Ryan Cotterell.
arxiv.org/abs/2411.07404
Co-led with
@kevdududu.bsky.social - @niklasstoehr.bsky.social , Giovanni Monea, @wendlerc.bsky.social, Robert West & Ryan Cotterell.

November 22, 2024 at 3:49 PM
Can we understand and control how language models balance context and prior knowledge? Our latest paper shows it’s all about a 1D knob! 🎛️
arxiv.org/abs/2411.07404
Co-led with
@kevdududu.bsky.social - @niklasstoehr.bsky.social , Giovanni Monea, @wendlerc.bsky.social, Robert West & Ryan Cotterell.
arxiv.org/abs/2411.07404
Co-led with
@kevdududu.bsky.social - @niklasstoehr.bsky.social , Giovanni Monea, @wendlerc.bsky.social, Robert West & Ryan Cotterell.