


Person
@assembly.bsky.social
Here for signal, not noise. Decade+ in AI + ML. A few patents. A few inventions. Many lessons and failures along the way.
Reposted by Person

Lessons in laughter:
Dozens of you have shared this lovely video with me over the past couple days. And I just love that it illustrates two baby lessons in one. 🧵
Dozens of you have shared this lovely video with me over the past couple days. And I just love that it illustrates two baby lessons in one. 🧵
March 24, 2025 at 12:47 PM
Lessons in laughter:
Dozens of you have shared this lovely video with me over the past couple days. And I just love that it illustrates two baby lessons in one. 🧵
Dozens of you have shared this lovely video with me over the past couple days. And I just love that it illustrates two baby lessons in one. 🧵
Reposted by Person

StarVector
StarVector is a foundation model for generating Scalable Vector Graphics (SVG) code from images and text. It utilizes a Vision-Language Modeling architecture to understand both visual and textual inputs, enabling high-quality vectorization and text-guided SVG creation.
StarVector is a foundation model for generating Scalable Vector Graphics (SVG) code from images and text. It utilizes a Vision-Language Modeling architecture to understand both visual and textual inputs, enabling high-quality vectorization and text-guided SVG creation.
March 21, 2025 at 11:09 PM
StarVector
StarVector is a foundation model for generating Scalable Vector Graphics (SVG) code from images and text. It utilizes a Vision-Language Modeling architecture to understand both visual and textual inputs, enabling high-quality vectorization and text-guided SVG creation.
StarVector is a foundation model for generating Scalable Vector Graphics (SVG) code from images and text. It utilizes a Vision-Language Modeling architecture to understand both visual and textual inputs, enabling high-quality vectorization and text-guided SVG creation.
Reposted by Person

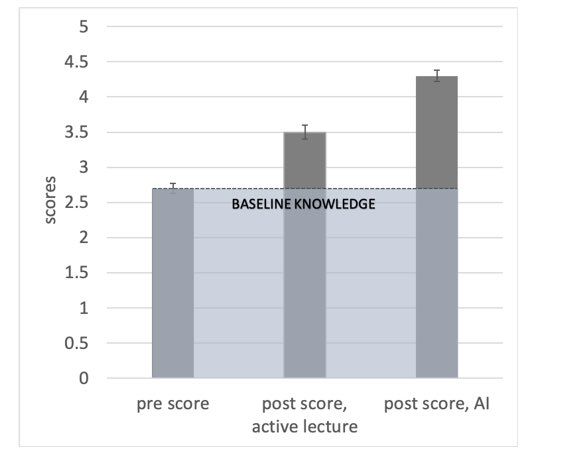
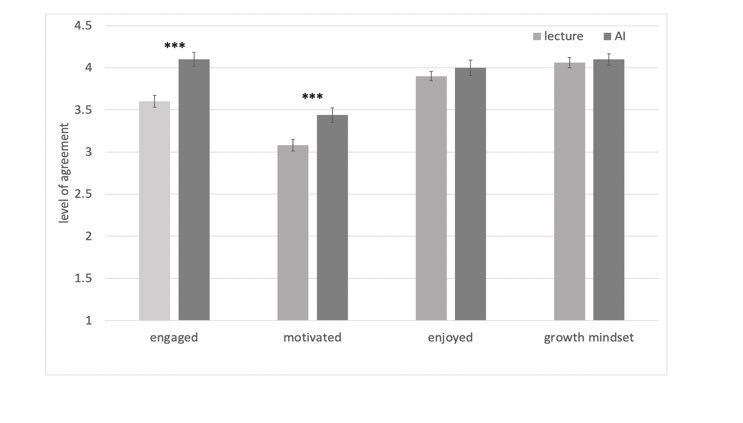
Evidence that a well prompted LLM can help learning from a (small, single-subject) randomized controlled trial at Harvard: “here we show that students learn more than twice as much in less time with an AI tutor compared to an active learning classroom, while also being more engaged and motivated.”

March 21, 2025 at 5:47 PM
Evidence that a well prompted LLM can help learning from a (small, single-subject) randomized controlled trial at Harvard: “here we show that students learn more than twice as much in less time with an AI tutor compared to an active learning classroom, while also being more engaged and motivated.”
Reposted by Person

Cool to see results extended! Last year, we identified a breakthrough in masked LM training where specialized syntactic heads emerge. We didn't think the same moment would be visible in decoder-only models, but Aoyama & @wegotlieb.bsky.social have found one, also marking a decline in "humanlikeness"

Language Models Grow Less Humanlike beyond Phase Transition
LMs' alignment with human reading behavior (i.e. psychometric predictive power; PPP) is known to improve during pretraining up to a tipping point, beyond which it either plateaus or degrades. Various ...
arxiv.org
March 21, 2025 at 6:10 PM
Cool to see results extended! Last year, we identified a breakthrough in masked LM training where specialized syntactic heads emerge. We didn't think the same moment would be visible in decoder-only models, but Aoyama & @wegotlieb.bsky.social have found one, also marking a decline in "humanlikeness"
Sounds a bit like a fusion of System 2 thinking with a kind of working / short term memory?

Anthropic says that a "think" tool dramatically improves agents' abilities
unlike "extended thinking", the think tool is meant to incorporate new information, e.g. from other tools
most notable: their use of pass^k (all of k) instead of pass@k (one of k)
www.anthropic.com/engineering/...
unlike "extended thinking", the think tool is meant to incorporate new information, e.g. from other tools
most notable: their use of pass^k (all of k) instead of pass@k (one of k)
www.anthropic.com/engineering/...

March 22, 2025 at 10:06 AM
Sounds a bit like a fusion of System 2 thinking with a kind of working / short term memory?
Extrapolating @soniakmurthy.bsky.social findings: Individual differences in LLMs are low, which limits their diversity of thought. To me this suggests LLMs also have lower diversity of problem solving, creativity, etc. How to fix?

(1/9) Excited to share my recent work on "Alignment reduces LM's conceptual diversity" with @tomerullman.bsky.social and @jennhu.bsky.social, to appear at #NAACL2025! 🐟
We want models that match our values...but could this hurt their diversity of thought?
Preprint: arxiv.org/abs/2411.04427
We want models that match our values...but could this hurt their diversity of thought?
Preprint: arxiv.org/abs/2411.04427

February 11, 2025 at 12:19 PM
Extrapolating @soniakmurthy.bsky.social findings: Individual differences in LLMs are low, which limits their diversity of thought. To me this suggests LLMs also have lower diversity of problem solving, creativity, etc. How to fix?
Good to see evidence validating OR rejecting the potential benefits of LLMs. Fair to say we should expect LLMs to enhance reasoning in many other jobs and skills.

🧪 A new study has found that doctors using GPT-4 spend more time per case, engaging in deeper analysis and broader thinking—enhancing reasoning and improving decision accuracy. 🩺💻 🧠

Can AI Make Doctors Think Deeper?
AI isn't replacing doctors. It's helping them think more deeply.
www.psychologytoday.com
February 10, 2025 at 3:04 PM
Good to see evidence validating OR rejecting the potential benefits of LLMs. Fair to say we should expect LLMs to enhance reasoning in many other jobs and skills.
Reposted by Person

one of the most intriguing projects i've been involved in: automated scientific discovery in an area (human/animal RL) I've been working on forever. can an LLM do the job of my grad students? if it is backed up by super smart scientists incl @pcastr.bsky.social @neurokim.bsky.social & kevin miller

Can LLMs be used to discover interpretable models of human and animal behavior?🤔
Turns out: yes!
Thrilled to share our latest preprint where we used FunSearch to automatically discover symbolic cognitive models of behavior.
1/12
Turns out: yes!
Thrilled to share our latest preprint where we used FunSearch to automatically discover symbolic cognitive models of behavior.
1/12

February 10, 2025 at 1:50 PM
one of the most intriguing projects i've been involved in: automated scientific discovery in an area (human/animal RL) I've been working on forever. can an LLM do the job of my grad students? if it is backed up by super smart scientists incl @pcastr.bsky.social @neurokim.bsky.social & kevin miller
Reposted by Person

Rings appear to be entangled.

February 9, 2025 at 1:25 AM
Rings appear to be entangled.
Reposted by Person
A few implications of tricks like this:
1) We are still VERY early in the development of Reasoners
2) There is high value in understanding how humans solve problems & applying that to AI
3) Higher possibility of further exponential growth in AI capabilities as techniques for thinking traces compound
1) We are still VERY early in the development of Reasoners
2) There is high value in understanding how humans solve problems & applying that to AI
3) Higher possibility of further exponential growth in AI capabilities as techniques for thinking traces compound
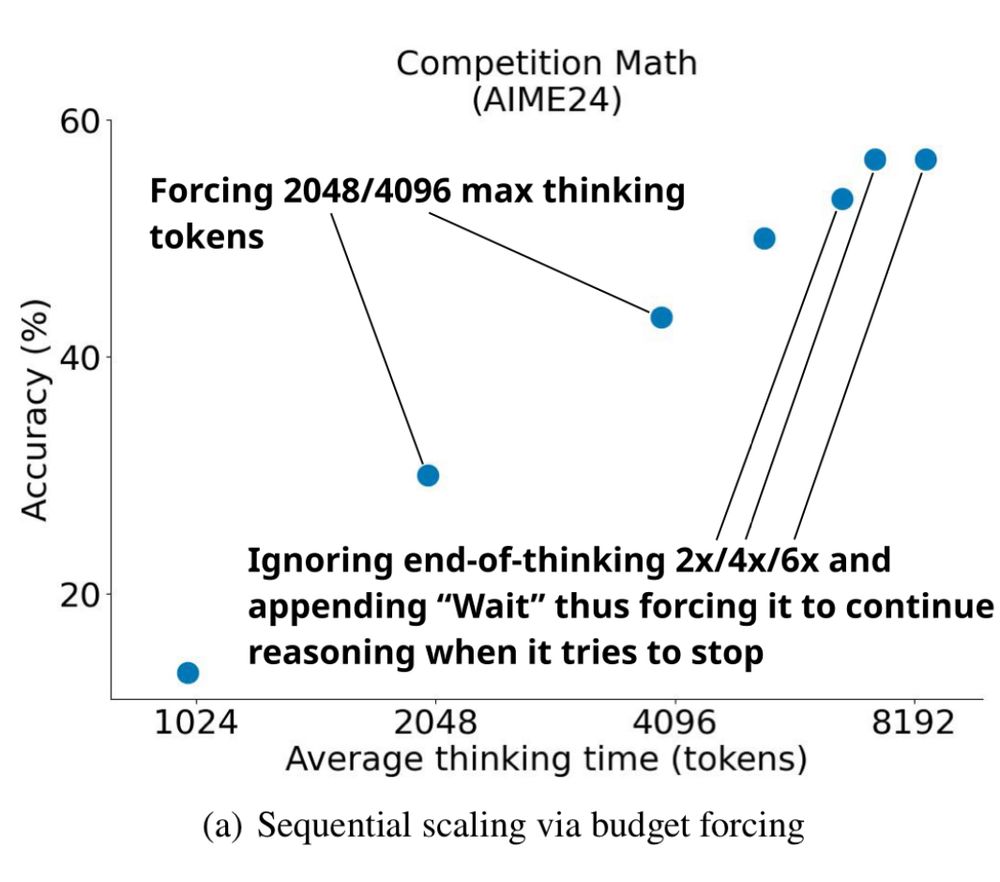
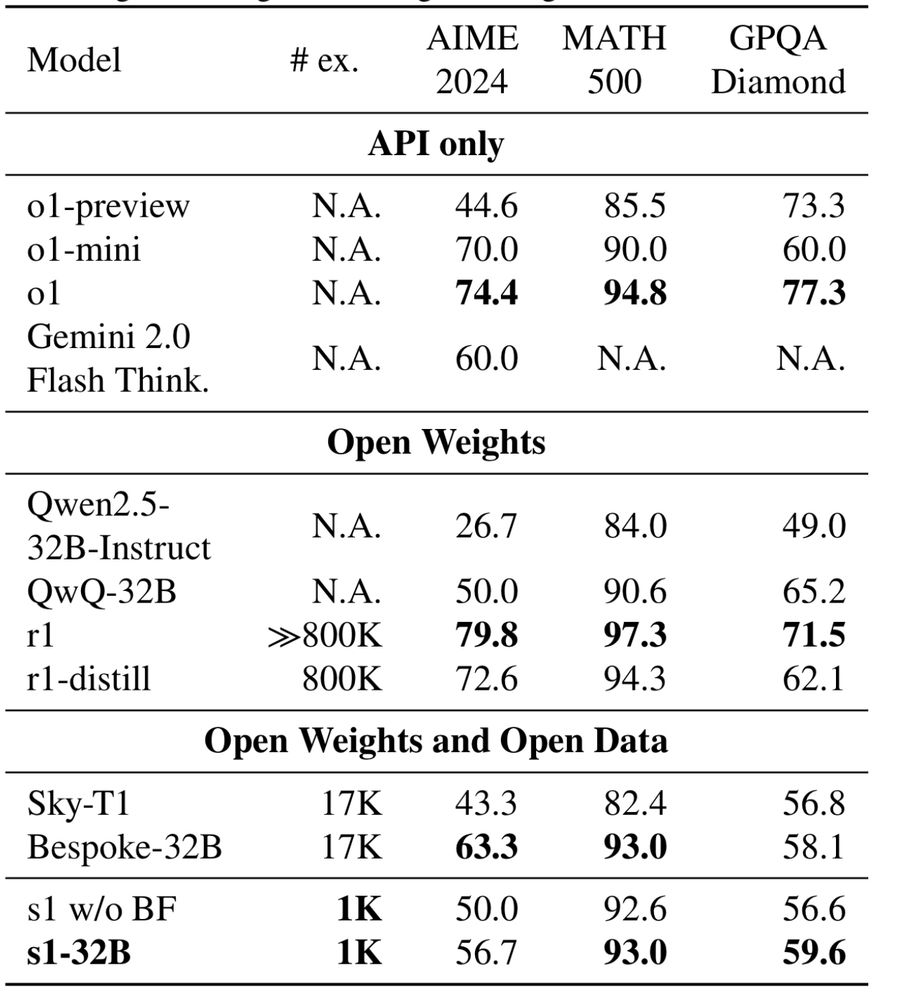
This paper is wild - a Stanford team shows the simplest way to make an open LLM into a reasoning model
They used just 1,000 carefully curated reasoning examples & a trick where if the model tries to stop thinking, they append "Wait" to force it to continue. Near o1 at math. arxiv.org/pdf/2501.19393
They used just 1,000 carefully curated reasoning examples & a trick where if the model tries to stop thinking, they append "Wait" to force it to continue. Near o1 at math. arxiv.org/pdf/2501.19393


February 7, 2025 at 3:23 PM
A few implications of tricks like this:
1) We are still VERY early in the development of Reasoners
2) There is high value in understanding how humans solve problems & applying that to AI
3) Higher possibility of further exponential growth in AI capabilities as techniques for thinking traces compound
1) We are still VERY early in the development of Reasoners
2) There is high value in understanding how humans solve problems & applying that to AI
3) Higher possibility of further exponential growth in AI capabilities as techniques for thinking traces compound
Reposted by Person

Making LLMs run efficiently can feel scary, but scaling isn’t magic, it’s math! We wanted to demystify the “systems view” of LLMs and wrote a little textbook called “How To Scale Your Model” which we’re releasing today. 1/n
February 4, 2025 at 6:54 PM
Making LLMs run efficiently can feel scary, but scaling isn’t magic, it’s math! We wanted to demystify the “systems view” of LLMs and wrote a little textbook called “How To Scale Your Model” which we’re releasing today. 1/n
Not so much a Python cheatsheet as mini-booklet. Covers everything from decorators to Panda to Pygame. Useful.

Whenever I’m coding in Python, having a good cheatsheet handy is a lifesaver! 🐍🛠️
Check out this Comprehensive Python Cheatsheet by Jure Šorn,
Check out this Comprehensive Python Cheatsheet by Jure Šorn,

Whenever I’m coding in Python, having a good cheatsheet handy is a lifesaver! 🐍🛠️
It’s a goldmine of Python tips, tricks, and code snippets, whether you’re a beginner or a seasoned developer, this resource covers everything from basic lists and tuples to advanced concepts, making it an essential tool for any Pythonista!
amplt.de
February 2, 2025 at 12:30 PM
Not so much a Python cheatsheet as mini-booklet. Covers everything from decorators to Panda to Pygame. Useful.
Reposted by Person

I went through my RL bookmarks, because it seems like finally the rest of the world has caught up to my world, I rediscovered this gem 💎 mpatacchiola.github.io/blog/2016/12... although I suspect nobody wants to learn RL this way now 😜
Dissecting Reinforcement Learning-Part.1
Explaining the basic ideas behind reinforcement learning. In particular, Markov Decision Process, Bellman equation, Value iteration and Policy Iteration algorithms, policy iteration through linear alg...
mpatacchiola.github.io
January 28, 2025 at 4:50 AM
I went through my RL bookmarks, because it seems like finally the rest of the world has caught up to my world, I rediscovered this gem 💎 mpatacchiola.github.io/blog/2016/12... although I suspect nobody wants to learn RL this way now 😜
Reposted by Person
Reposted by Person
A vision researcher’s guide to some RL stuff: PPO & GRPO by Yuge (Jimmy) Shi
This is a deep dive into Proximal Policy Optimization (PPO), which is one of the most popular algorithm used in RLHF for LLMs, as well as Group Relative Policy Optimization (GRPO) proposed by the DeepSeek folks.
This is a deep dive into Proximal Policy Optimization (PPO), which is one of the most popular algorithm used in RLHF for LLMs, as well as Group Relative Policy Optimization (GRPO) proposed by the DeepSeek folks.
January 31, 2025 at 5:56 AM
A vision researcher’s guide to some RL stuff: PPO & GRPO by Yuge (Jimmy) Shi
This is a deep dive into Proximal Policy Optimization (PPO), which is one of the most popular algorithm used in RLHF for LLMs, as well as Group Relative Policy Optimization (GRPO) proposed by the DeepSeek folks.
This is a deep dive into Proximal Policy Optimization (PPO), which is one of the most popular algorithm used in RLHF for LLMs, as well as Group Relative Policy Optimization (GRPO) proposed by the DeepSeek folks.
Fascinating - skimmed the paper and added to my deeper reading list. They've released data and implementation at github.com/Poirazi-Lab/...
January 30, 2025 at 9:32 AM
Fascinating - skimmed the paper and added to my deeper reading list. They've released data and implementation at github.com/Poirazi-Lab/...
Alternatives to backpropagation (how artifical neural networks learn) always catch my attention. Adding this to my reading list.

I release a minimal (<150 lines) JAX implementation of "Gradients without Backpropagation" paper. It proposes a simple addition to forward AD to estimate unbiased gradients during single inference pass (quick project, might be further optimized)
https://github.com/YigitDemirag/forward-gradients
https://github.com/YigitDemirag/forward-gradients
github.com
January 30, 2025 at 9:25 AM
Alternatives to backpropagation (how artifical neural networks learn) always catch my attention. Adding this to my reading list.
Beautiful

Just a gorgeous #Purkinje neuron all by itself in the cerebellum. Only with #lightsheet #microscopy on a whole #cleared sample could you ever hope to catch a lone reporter expressing cell in it’s entirety. #science 🧪
January 29, 2025 at 3:53 PM
Beautiful
Reposted by Person

In case you missed it last week, we have a new paper about brain modularity: relating modular structures and modular functions. I'm so happy about these results that I've been reorienting my research programme to do more. Thread below with some extra speculations about where we might want to go next
What's the right way to think about modularity in the brain? This devilish 😈 question is a big part of my research now, and it started with this paper with @solarpunkgabs.bsky.social, finally published after the first preprint in 2021! 🤖🧠🧪
www.nature.com/articles/s41...
www.nature.com/articles/s41...
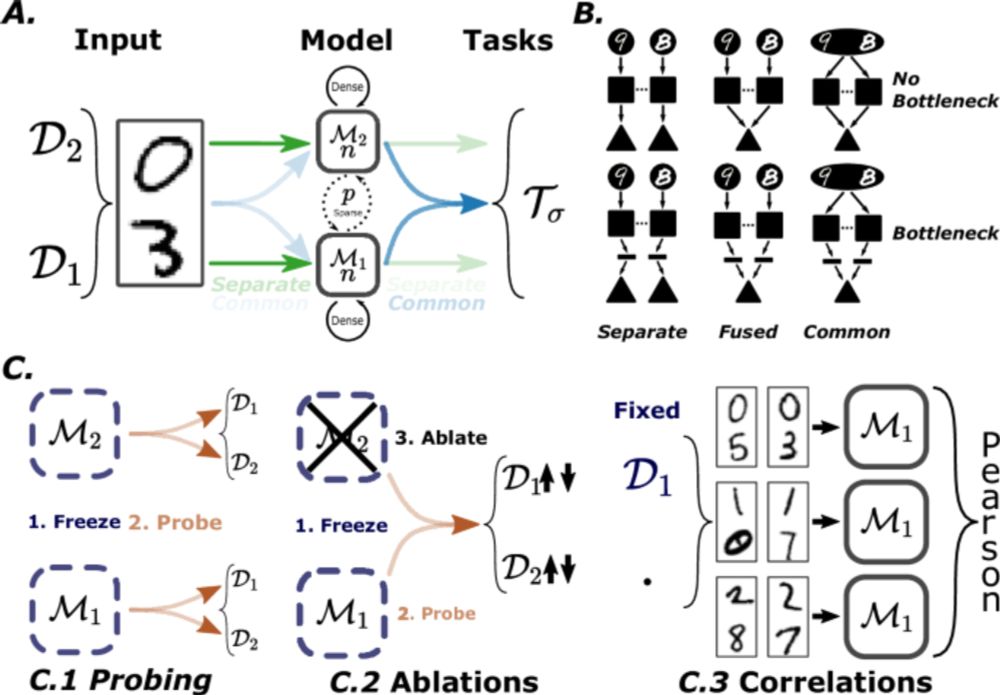
Dynamics of specialization in neural modules under resource constraints - Nature Communications
The extent to which structural modularity in neural networks ensures functional specialization remains unclear. Here the authors show that specialization can emerge in neural modules placed under reso...
www.nature.com
January 27, 2025 at 4:51 PM
In case you missed it last week, we have a new paper about brain modularity: relating modular structures and modular functions. I'm so happy about these results that I've been reorienting my research programme to do more. Thread below with some extra speculations about where we might want to go next