




Arthur Câmara
@abcamara.com
Applied #IR & #NLP Research @zeta-alpha.bsky.social, making search good.
CS PhD @tudelft. Former @naverlabseurope.bsky.social, @bloomberg.com
CNF✈️AMS
CS PhD @tudelft. Former @naverlabseurope.bsky.social, @bloomberg.com
CNF✈️AMS
Reposted by Arthur Câmara

Shipping a GenAI solution in production with a clear path to ROI is hard. In our latest post, we outline key challenges in Enterprise RAG, go beyond the basics with agents, and explore how automatic optimization can adapt these systems to domain-specific needs.
www.zeta-alpha.com/post/why-gen...
www.zeta-alpha.com/post/why-gen...

Why GenAI Pilots Fail: Common Challenges with Enterprise RAG
Retrieval-Augmented Generation (RAG) is powering the current wave of AI applications, from multimodal question answering and technical document summarization to streamlining knowledge-intensive work f...
www.zeta-alpha.com
September 18, 2025 at 12:11 PM
Shipping a GenAI solution in production with a clear path to ROI is hard. In our latest post, we outline key challenges in Enterprise RAG, go beyond the basics with agents, and explore how automatic optimization can adapt these systems to domain-specific needs.
www.zeta-alpha.com/post/why-gen...
www.zeta-alpha.com/post/why-gen...
Reposted by Arthur Câmara

How to automatically evaluate and optimize multi-agent setups for deep research? Excited to share that this week @abcamara.com and I will be giving two talks in Amsterdam on one of our favorite R&D topics.
- August 27th: @opensearch.org Meetup Amsterdam
- August 29th: AI Dev Event Amsterdam #AIDev
- August 27th: @opensearch.org Meetup Amsterdam
- August 29th: AI Dev Event Amsterdam #AIDev

August 25, 2025 at 12:21 PM
How to automatically evaluate and optimize multi-agent setups for deep research? Excited to share that this week @abcamara.com and I will be giving two talks in Amsterdam on one of our favorite R&D topics.
- August 27th: @opensearch.org Meetup Amsterdam
- August 29th: AI Dev Event Amsterdam #AIDev
- August 27th: @opensearch.org Meetup Amsterdam
- August 29th: AI Dev Event Amsterdam #AIDev
Reposted by Arthur Câmara

## Books will soon be obsolete in school
https://shkspr.mobi/blog/2025/08/books-will-soon-be-obsolete-in-school/
I recently had a chance to ask a question to one of the **top** AI people. At a Q&A session, I raised my hand and asked simply "What is your […]
[Original post on shkspr.mobi]
https://shkspr.mobi/blog/2025/08/books-will-soon-be-obsolete-in-school/
I recently had a chance to ask a question to one of the **top** AI people. At a Q&A session, I raised my hand and asked simply "What is your […]
[Original post on shkspr.mobi]

August 16, 2025 at 11:38 AM
## Books will soon be obsolete in school
https://shkspr.mobi/blog/2025/08/books-will-soon-be-obsolete-in-school/
I recently had a chance to ask a question to one of the **top** AI people. At a Q&A session, I raised my hand and asked simply "What is your […]
[Original post on shkspr.mobi]
https://shkspr.mobi/blog/2025/08/books-will-soon-be-obsolete-in-school/
I recently had a chance to ask a question to one of the **top** AI people. At a Q&A session, I raised my hand and asked simply "What is your […]
[Original post on shkspr.mobi]
Reposted by Arthur Câmara
AI agents are only as useful as the tools they can reliably access, and the latest release of our Agents SDK makes it easy to connect to MCP servers.
We've prepared a quick guide where we bootstrap a minimal MCP-powered chat agent with just a few lines of code:
www.zeta-alpha.com/post/build-m...
We've prepared a quick guide where we bootstrap a minimal MCP-powered chat agent with just a few lines of code:
www.zeta-alpha.com/post/build-m...

August 8, 2025 at 2:13 PM
AI agents are only as useful as the tools they can reliably access, and the latest release of our Agents SDK makes it easy to connect to MCP servers.
We've prepared a quick guide where we bootstrap a minimal MCP-powered chat agent with just a few lines of code:
www.zeta-alpha.com/post/build-m...
We've prepared a quick guide where we bootstrap a minimal MCP-powered chat agent with just a few lines of code:
www.zeta-alpha.com/post/build-m...
Just officially finished(?) Blue Price, or at least as far as the community is aware of its end.
My life goal is to make someone else play it without touching Google, and make them rely on me for tips and guidance. Is that how DMs feel like?
My life goal is to make someone else play it without touching Google, and make them rely on me for tips and guidance. Is that how DMs feel like?
July 13, 2025 at 7:54 AM
Just officially finished(?) Blue Price, or at least as far as the community is aware of its end.
My life goal is to make someone else play it without touching Google, and make them rely on me for tips and guidance. Is that how DMs feel like?
My life goal is to make someone else play it without touching Google, and make them rely on me for tips and guidance. Is that how DMs feel like?
Same story with the no-code movement of some time ago. Specifying precisely what you want (call it prompting, call it no-code) is just… programming.
AI tools will reduce the need for software engineers the same way that no-code tools reduced this.
Being able to specify what software you want to build, how it should be structured, and how *exactly* it should work is... programming. And getting into the weeds, when needed.
Being able to specify what software you want to build, how it should be structured, and how *exactly* it should work is... programming. And getting into the weeds, when needed.
July 7, 2025 at 8:43 PM
Same story with the no-code movement of some time ago. Specifying precisely what you want (call it prompting, call it no-code) is just… programming.
Reposted by Arthur Câmara

AI tools will reduce the need for software engineers the same way that no-code tools reduced this.
Being able to specify what software you want to build, how it should be structured, and how *exactly* it should work is... programming. And getting into the weeds, when needed.
Being able to specify what software you want to build, how it should be structured, and how *exactly* it should work is... programming. And getting into the weeds, when needed.
July 7, 2025 at 7:09 PM
AI tools will reduce the need for software engineers the same way that no-code tools reduced this.
Being able to specify what software you want to build, how it should be structured, and how *exactly* it should work is... programming. And getting into the weeds, when needed.
Being able to specify what software you want to build, how it should be structured, and how *exactly* it should work is... programming. And getting into the weeds, when needed.
Next week I will be going on a 15-days trip to Brazil for two weddings. It’s the first time since high school that I will spend that long without working (or at least trying). And the first time in 5 years I will spend that long without wife and kids.
I think I will die of boredom.
I think I will die of boredom.
May 31, 2025 at 7:38 AM
Next week I will be going on a 15-days trip to Brazil for two weddings. It’s the first time since high school that I will spend that long without working (or at least trying). And the first time in 5 years I will spend that long without wife and kids.
I think I will die of boredom.
I think I will die of boredom.
Every time I open my Steam wishlist and see In The Valley of Gods I cry a bit inside.
May 31, 2025 at 7:29 AM
Every time I open my Steam wishlist and see In The Valley of Gods I cry a bit inside.
After ~20h of Blue Prince, I think I will need an Obsidian canvas to keep track of everything. My notebook is just not quite cutting it
April 30, 2025 at 10:19 AM
After ~20h of Blue Prince, I think I will need an Obsidian canvas to keep track of everything. My notebook is just not quite cutting it
Reposted by Arthur Câmara
📢 Zeta Alpha is going to OpenSearchCon Europe 2025 📢
We are excited to be contributing back to the OpenSearch community, sharing insights from our work in Enterprise AI, Neural Search, and Retrieval-Augmented Generation (RAG). Learn more about our talks at the conference below: 🧵
We are excited to be contributing back to the OpenSearch community, sharing insights from our work in Enterprise AI, Neural Search, and Retrieval-Augmented Generation (RAG). Learn more about our talks at the conference below: 🧵
April 24, 2025 at 3:39 PM
📢 Zeta Alpha is going to OpenSearchCon Europe 2025 📢
We are excited to be contributing back to the OpenSearch community, sharing insights from our work in Enterprise AI, Neural Search, and Retrieval-Augmented Generation (RAG). Learn more about our talks at the conference below: 🧵
We are excited to be contributing back to the OpenSearch community, sharing insights from our work in Enterprise AI, Neural Search, and Retrieval-Augmented Generation (RAG). Learn more about our talks at the conference below: 🧵
It’s incredible how often you can track IR back to Yahoo Labs.
April 24, 2025 at 7:44 AM
It’s incredible how often you can track IR back to Yahoo Labs.
Reposted by Arthur Câmara
Join us for our monthly Trends in AI webinar on Thursday, April 3rd, at 8 AM PST / 5 PM CEST! This edition comes live from Hannover Messe, the world's leading industrial tech trade fair, and online in Amsterdam, San Francisco, and everywhere else in the world.
Sign up on Luma with the link below:
Sign up on Luma with the link below:

Trends in AI: April 2025 - by Zeta Alpha · Zoom · Luma
Join us for the Zeta Alpha Trends in AI webinar on Thursday, April 3rd, at 8 AM PST / 5 PM CEST (time to be confirmed). This edition comes live from Hannover…
lu.ma
April 1, 2025 at 4:03 PM
Join us for our monthly Trends in AI webinar on Thursday, April 3rd, at 8 AM PST / 5 PM CEST! This edition comes live from Hannover Messe, the world's leading industrial tech trade fair, and online in Amsterdam, San Francisco, and everywhere else in the world.
Sign up on Luma with the link below:
Sign up on Luma with the link below:
I spent the last three weeks chasing down some weird memory leaks in our code. Took me too long to discover memray. Thanks, @pablogsal.com for the days of headache saved.
March 20, 2025 at 3:45 PM
I spent the last three weeks chasing down some weird memory leaks in our code. Took me too long to discover memray. Thanks, @pablogsal.com for the days of headache saved.
Reposted by Arthur Câmara
Agents are all the rage - and for good reason. While the concept of agents has been around for decades in traditional software engineering, recent AI breakthroughs have brought them back into the spotlight.
March 11, 2025 at 11:25 AM
Agents are all the rage - and for good reason. While the concept of agents has been around for decades in traditional software engineering, recent AI breakthroughs have brought them back into the spotlight.
Reposted by Arthur Câmara
One of the advantages of Europe is its wonderful high speed train system. So this morning I hopped on the Eurostar to Paris, where I am proud to represent @zeta-alpha.bsky.social at the Hello Tomorrow 2025 Global Summit on the AI side of the Dutch Deep Tech delegation.

March 12, 2025 at 9:52 AM
One of the advantages of Europe is its wonderful high speed train system. So this morning I hopped on the Eurostar to Paris, where I am proud to represent @zeta-alpha.bsky.social at the Hello Tomorrow 2025 Global Summit on the AI side of the Dutch Deep Tech delegation.
WHAT HAVE YOU DONE, NIST? One of the last bastions of old-style web UI in our IR community is dead!
(just kidding, the site looks so much better now)
(just kidding, the site looks so much better now)

March 11, 2025 at 8:45 AM
WHAT HAVE YOU DONE, NIST? One of the last bastions of old-style web UI in our IR community is dead!
(just kidding, the site looks so much better now)
(just kidding, the site looks so much better now)
Reposted by Arthur Câmara
Zeta Alpha recognized as a leading native AI enterprise search technology provider.
www.zeta-alpha.com/post/zeta-al...
www.zeta-alpha.com/post/zeta-al...

Zeta Alpha recognized as a leading native AI enterprise search technology provider.
Zeta Alpha recognized as a leading native enterprise AI search technology provider.
www.zeta-alpha.com
January 23, 2025 at 10:33 AM
Zeta Alpha recognized as a leading native AI enterprise search technology provider.
www.zeta-alpha.com/post/zeta-al...
www.zeta-alpha.com/post/zeta-al...
I feel personally attacked by this

Write your training loops with care, as if your ML model hated you and wanted you to fail.
January 13, 2025 at 10:22 AM
I feel personally attacked by this
I will never understand why Typer can’t handle pydantic as an argument type. Everything is there. And the developer uses pydantic heavily on his other projects.
November 28, 2024 at 1:03 PM
I will never understand why Typer can’t handle pydantic as an argument type. Everything is there. And the developer uses pydantic heavily on his other projects.
I’ve said on the other network, but I’ve been bullish on listwise methods for a while (When I was at Naver, I wrote a paper about this, but it wasn’t accepted).
Biggest drawback is the lack of large scale training datasets with multiple relevant judgments per query.
Biggest drawback is the lack of large scale training datasets with multiple relevant judgments per query.

Mat is not on 🦋—posting on his behalf!
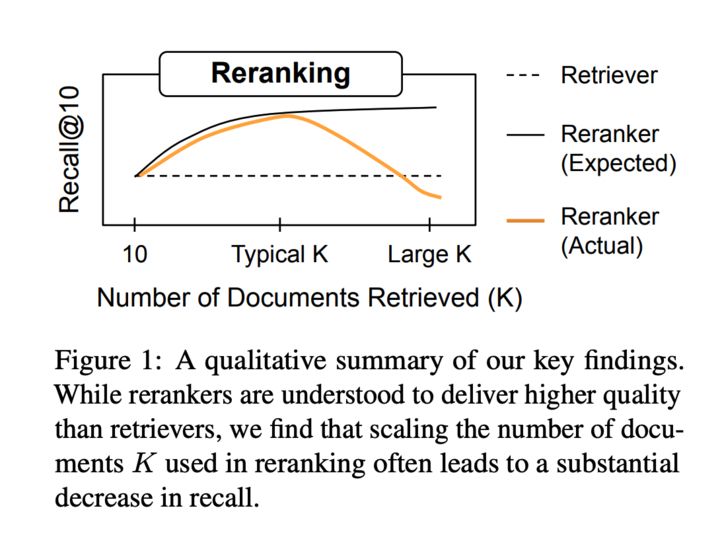
It's time to revisit common assumptions in IR! Embeddings have improved drastically, but mainstream IR evals have stagnated since MSMARCO + BEIR.
We ask: on private or tricky IR tasks, are rerankers better? Surely, reranking many docs is best?
It's time to revisit common assumptions in IR! Embeddings have improved drastically, but mainstream IR evals have stagnated since MSMARCO + BEIR.
We ask: on private or tricky IR tasks, are rerankers better? Surely, reranking many docs is best?
November 21, 2024 at 8:04 AM
I’ve said on the other network, but I’ve been bullish on listwise methods for a while (When I was at Naver, I wrote a paper about this, but it wasn’t accepted).
Biggest drawback is the lack of large scale training datasets with multiple relevant judgments per query.
Biggest drawback is the lack of large scale training datasets with multiple relevant judgments per query.
Astro Bot is so good that I would be more than happy to pay whathever they ask for a DLC with a new galaxy.
November 16, 2024 at 11:21 AM
Astro Bot is so good that I would be more than happy to pay whathever they ask for a DLC with a new galaxy.
A kid with an ear infection is a surefire way to ruin your work week.
November 10, 2024 at 9:23 PM
A kid with an ear infection is a surefire way to ruin your work week.
Better start learning Russian.
November 6, 2024 at 7:36 AM
Better start learning Russian.
Using Astro bot to teach my kid about the really important stuff. (Video game history)

November 2, 2024 at 8:34 AM
Using Astro bot to teach my kid about the really important stuff. (Video game history)