



Luca Bindini, Simone Giovannini, Simone Marinai, Valeria Nardoni, Kimiya Noor Ali
Hierarchical structure understanding in complex tables with VLLMs: a benchmark and experiments
https://arxiv.org/abs/2511.08298
Hierarchical structure understanding in complex tables with VLLMs: a benchmark and experiments
https://arxiv.org/abs/2511.08298
November 12, 2025 at 7:35 AM
Luca Bindini, Simone Giovannini, Simone Marinai, Valeria Nardoni, Kimiya Noor Ali
Hierarchical structure understanding in complex tables with VLLMs: a benchmark and experiments
https://arxiv.org/abs/2511.08298
Hierarchical structure understanding in complex tables with VLLMs: a benchmark and experiments
https://arxiv.org/abs/2511.08298

Luca Bindini, Simone Giovannini, Simone Marinai, Valeria Nardoni, Kimiya Noor Ali: Hierarchical structure understanding in complex tables with VLLMs: a benchmark and experiments https://arxiv.org/abs/2511.08298 https://arxiv.org/pdf/2511.08298 https://arxiv.org/html/2511.08298
November 12, 2025 at 6:30 AM
Luca Bindini, Simone Giovannini, Simone Marinai, Valeria Nardoni, Kimiya Noor Ali: Hierarchical structure understanding in complex tables with VLLMs: a benchmark and experiments https://arxiv.org/abs/2511.08298 https://arxiv.org/pdf/2511.08298 https://arxiv.org/html/2511.08298

[2025-11-12] 📚 Updates in #LMTD
(1) p2-TQA: A Process-based Preference Learning Framework for Self-Improving Table Question Answering Models
(2) Hierarchical structure understanding in complex tables with VLLMs: a benchmark and experiments
🔍 More at researchtrend.ai/communities/LMTD
(1) p2-TQA: A Process-based Preference Learning Framework for Self-Improving Table Question Answering Models
(2) Hierarchical structure understanding in complex tables with VLLMs: a benchmark and experiments
🔍 More at researchtrend.ai/communities/LMTD
November 12, 2025 at 3:10 AM

#toread #paper Leveraging VLLMs for visual clustering: Image-to-text mapping shows increased... by Arminio, Luigi et al. https://scholar.google.com/scholar?q=Leveraging%20VLLMs%20for%20visual%20clustering%20Imagetotext%20mapping%20shows%20increased%20semantic%20capabilities%20and%20interpretability
September 23, 2025 at 5:30 PM
#toread #paper Leveraging VLLMs for visual clustering: Image-to-text mapping shows increased... by Arminio, Luigi et al. https://scholar.google.com/scholar?q=Leveraging%20VLLMs%20for%20visual%20clustering%20Imagetotext%20mapping%20shows%20increased%20semantic%20capabilities%20and%20interpretability

Few days ago I posted about our new article on semantic clustering with VLLMs (here if you missed it journals.sagepub.com/doi/10.1177/... ) and I wrote that the method is better than some alternative because it offers cultural awareness and interpretability. Let me explain what I mean by cultural
September 21, 2025 at 6:31 PM
Few days ago I posted about our new article on semantic clustering with VLLMs (here if you missed it journals.sagepub.com/doi/10.1177/... ) and I wrote that the method is better than some alternative because it offers cultural awareness and interpretability. Let me explain what I mean by cultural

Gated Residual Tokenization (GRT) lets VLLMs handle high‑FPS video by skipping static regions and merging scene tokens. On the DIVE benchmark, GRT outperforms larger models as frame rate rises. Read more: https://getnews.me/gated-residual-tokenization-improves-dense-video-understanding/ #grt #dive

September 20, 2025 at 3:11 PM
Gated Residual Tokenization (GRT) lets VLLMs handle high‑FPS video by skipping static regions and merging scene tokens. On the DIVE benchmark, GRT outperforms larger models as frame rate rises. Read more: https://getnews.me/gated-residual-tokenization-improves-dense-video-understanding/ #grt #dive
#computationalsocialscience Our work on using VLLMs for semantic visual clustering is out on SSCR: journals.sagepub.com/doi/10.1177/...
There is a lot happening in the space of computational analysis of visual content as we acknowledge more and more the visual nature of contemporary communication.
There is a lot happening in the space of computational analysis of visual content as we acknowledge more and more the visual nature of contemporary communication.

Sage Journals: Discover world-class research
Subscription and open access journals from Sage, the world's leading independent academic publisher.
journals.sagepub.com
September 19, 2025 at 9:48 AM
#computationalsocialscience Our work on using VLLMs for semantic visual clustering is out on SSCR: journals.sagepub.com/doi/10.1177/...
There is a lot happening in the space of computational analysis of visual content as we acknowledge more and more the visual nature of contemporary communication.
There is a lot happening in the space of computational analysis of visual content as we acknowledge more and more the visual nature of contemporary communication.
GitHub announces the MCP registry, a solution for discovery and use of MCP servers.
This is a much-needed service for all developers and users of VLLMs and Agents.
It also indicates that GitHub is on a clear path to being absorbed by Microsoft, as I have previously noted.
This is a much-needed service for all developers and users of VLLMs and Agents.
It also indicates that GitHub is on a clear path to being absorbed by Microsoft, as I have previously noted.

September 17, 2025 at 1:03 PM
GitHub announces the MCP registry, a solution for discovery and use of MCP servers.
This is a much-needed service for all developers and users of VLLMs and Agents.
It also indicates that GitHub is on a clear path to being absorbed by Microsoft, as I have previously noted.
This is a much-needed service for all developers and users of VLLMs and Agents.
It also indicates that GitHub is on a clear path to being absorbed by Microsoft, as I have previously noted.

Muhammad Ali, Salman Khan
Waste-Bench: A Comprehensive Benchmark for Evaluating VLLMs in Cluttered Environments
https://arxiv.org/abs/2509.00176
Waste-Bench: A Comprehensive Benchmark for Evaluating VLLMs in Cluttered Environments
https://arxiv.org/abs/2509.00176
September 3, 2025 at 5:13 PM
Muhammad Ali, Salman Khan
Waste-Bench: A Comprehensive Benchmark for Evaluating VLLMs in Cluttered Environments
https://arxiv.org/abs/2509.00176
Waste-Bench: A Comprehensive Benchmark for Evaluating VLLMs in Cluttered Environments
https://arxiv.org/abs/2509.00176

Muhammad Ali, Salman Khan: Waste-Bench: A Comprehensive Benchmark for Evaluating VLLMs in Cluttered Environments https://arxiv.org/abs/2509.00176 https://arxiv.org/pdf/2509.00176 https://arxiv.org/html/2509.00176
September 3, 2025 at 6:30 AM
Muhammad Ali, Salman Khan: Waste-Bench: A Comprehensive Benchmark for Evaluating VLLMs in Cluttered Environments https://arxiv.org/abs/2509.00176 https://arxiv.org/pdf/2509.00176 https://arxiv.org/html/2509.00176

Nawaf Alampara and coauthors present MaCBench, benchmarking VLLMs on chemistry and materials tasks in data extraction, experiment execution, and interpretation. www.nature.com/articles/s43...

Probing the limitations of multimodal language models for chemistry and materials research - Nature Computational Science
A comprehensive benchmark, called MaCBench, is developed to evaluate how vision language models handle different aspects of real-world chemistry and materials science tasks.
www.nature.com
August 15, 2025 at 1:41 PM
Nawaf Alampara and coauthors present MaCBench, benchmarking VLLMs on chemistry and materials tasks in data extraction, experiment execution, and interpretation. www.nature.com/articles/s43...

Deploy LLMs on Amazon EKS using vLLM Deep Learning Containers In this post, we demonstrate how to deploy the DeepSeek-R1-Distill-Qwen-32B model using AWS DLCs for vLLMs on Amazon EKS, showcasing ho...
#AWS #Deep #Learning #AMIs #Best #Practices #Expert #(400) […]
[Original post on aws.amazon.com]
#AWS #Deep #Learning #AMIs #Best #Practices #Expert #(400) […]
[Original post on aws.amazon.com]
Original post on aws.amazon.com
aws.amazon.com
August 17, 2025 at 8:44 AM
Deploy LLMs on Amazon EKS using vLLM Deep Learning Containers In this post, we demonstrate how to deploy the DeepSeek-R1-Distill-Qwen-32B model using AWS DLCs for vLLMs on Amazon EKS, showcasing ho...
#AWS #Deep #Learning #AMIs #Best #Practices #Expert #(400) […]
[Original post on aws.amazon.com]
#AWS #Deep #Learning #AMIs #Best #Practices #Expert #(400) […]
[Original post on aws.amazon.com]

Congrats to team members Prof Flora Salim, Breeze Chen & Wilson Wongso from ADM+S and other team members Xiaoqian Hu & Yue Tan from UNSW who placed 3rd in the highly competitive KDD Cup 2025 Meta CRAG-MM Challenge @florasalim.bsky.social
#KDD2025 #WearableAI #VLLMs admscentre.org/4mu7lFx
#KDD2025 #WearableAI #VLLMs admscentre.org/4mu7lFx

Award-winning tech enhances information retrieval in wearable AI devices - ADM+S Centre
A team of researchers from ADM+S at UNSW has been awarded third place for single-source augmentation in the highly competitive KDD Cup 2025 Meta CRAG-MM Challenge, ranking alongside top institutions s...
admscentre.org
August 5, 2025 at 11:27 PM
Congrats to team members Prof Flora Salim, Breeze Chen & Wilson Wongso from ADM+S and other team members Xiaoqian Hu & Yue Tan from UNSW who placed 3rd in the highly competitive KDD Cup 2025 Meta CRAG-MM Challenge @florasalim.bsky.social
#KDD2025 #WearableAI #VLLMs admscentre.org/4mu7lFx
#KDD2025 #WearableAI #VLLMs admscentre.org/4mu7lFx

Diving into vLLMs today.
No idea what is best in class at the moment.
I want to distill unstructured key info out of videos up to 5 minutes long.
OSS-wise Qwen2.5-VL seems neat.
Their GH looks very unmaintained :)
Sonnet? Gemini? GPT???
Any advice?
Plz
No idea what is best in class at the moment.
I want to distill unstructured key info out of videos up to 5 minutes long.
OSS-wise Qwen2.5-VL seems neat.
Their GH looks very unmaintained :)
Sonnet? Gemini? GPT???
Any advice?
Plz
July 24, 2025 at 7:42 AM
Diving into vLLMs today.
No idea what is best in class at the moment.
I want to distill unstructured key info out of videos up to 5 minutes long.
OSS-wise Qwen2.5-VL seems neat.
Their GH looks very unmaintained :)
Sonnet? Gemini? GPT???
Any advice?
Plz
No idea what is best in class at the moment.
I want to distill unstructured key info out of videos up to 5 minutes long.
OSS-wise Qwen2.5-VL seems neat.
Their GH looks very unmaintained :)
Sonnet? Gemini? GPT???
Any advice?
Plz
I was reminded the other day that I’ve spent the last 11 years working on independent video ML research focused on creativity & story telling, and shipping products & experiences in that time.
Mpeg7 fingerprinting, Deep belief, tensorflow, PyTorch, CoreML, vLLMs.
First POC:
vimeo.com/148001471
Mpeg7 fingerprinting, Deep belief, tensorflow, PyTorch, CoreML, vLLMs.
First POC:
vimeo.com/148001471

Synopsis Analysis work in progress
Synopsis is a video analysis (and optional transcoder) that runs computer vision processes and saves the results directly into a Qucktime or MP4 standards compliant…
vimeo.com
July 23, 2025 at 3:30 PM
I was reminded the other day that I’ve spent the last 11 years working on independent video ML research focused on creativity & story telling, and shipping products & experiences in that time.
Mpeg7 fingerprinting, Deep belief, tensorflow, PyTorch, CoreML, vLLMs.
First POC:
vimeo.com/148001471
Mpeg7 fingerprinting, Deep belief, tensorflow, PyTorch, CoreML, vLLMs.
First POC:
vimeo.com/148001471
From CNNs to VLLMs: Redefining Connotative Image Clustering for Social Science Research
Luigi Arminio, Matteo Magnani, Matias Piqueras, Luca Rossi, Alexandra Segerberg
Session: Posters II (Atrium)
23 Jul 2025, 13:30 – 14:30
Luigi Arminio, Matteo Magnani, Matias Piqueras, Luca Rossi, Alexandra Segerberg
Session: Posters II (Atrium)
23 Jul 2025, 13:30 – 14:30
July 21, 2025 at 2:35 PM
From CNNs to VLLMs: Redefining Connotative Image Clustering for Social Science Research
Luigi Arminio, Matteo Magnani, Matias Piqueras, Luca Rossi, Alexandra Segerberg
Session: Posters II (Atrium)
23 Jul 2025, 13:30 – 14:30
Luigi Arminio, Matteo Magnani, Matias Piqueras, Luca Rossi, Alexandra Segerberg
Session: Posters II (Atrium)
23 Jul 2025, 13:30 – 14:30
💡 Tip: Teach your AI how you think.
Write instructions like:
– "Summarize briefly using 2+ sources"
– "If question ends in 'detailed', use this format..."
Most VLLMs support this. It’s like giving your assistant a style guide and simple answers to possible dilemmas
Write instructions like:
– "Summarize briefly using 2+ sources"
– "If question ends in 'detailed', use this format..."
Most VLLMs support this. It’s like giving your assistant a style guide and simple answers to possible dilemmas
July 10, 2025 at 2:17 PM
💡 Tip: Teach your AI how you think.
Write instructions like:
– "Summarize briefly using 2+ sources"
– "If question ends in 'detailed', use this format..."
Most VLLMs support this. It’s like giving your assistant a style guide and simple answers to possible dilemmas
Write instructions like:
– "Summarize briefly using 2+ sources"
– "If question ends in 'detailed', use this format..."
Most VLLMs support this. It’s like giving your assistant a style guide and simple answers to possible dilemmas
Actually, unemployed at the moment
Nothing to do but chat with VLLMs like you
Nothing to do but chat with VLLMs like you
June 28, 2025 at 10:48 PM
Actually, unemployed at the moment
Nothing to do but chat with VLLMs like you
Nothing to do but chat with VLLMs like you
Andrew Kiruluta, Priscilla Burity
From Pixels and Words to Waves: A Unified Framework for Spectral Dictionary vLLMs
https://arxiv.org/abs/2506.18943
From Pixels and Words to Waves: A Unified Framework for Spectral Dictionary vLLMs
https://arxiv.org/abs/2506.18943
June 25, 2025 at 8:15 AM
Andrew Kiruluta, Priscilla Burity
From Pixels and Words to Waves: A Unified Framework for Spectral Dictionary vLLMs
https://arxiv.org/abs/2506.18943
From Pixels and Words to Waves: A Unified Framework for Spectral Dictionary vLLMs
https://arxiv.org/abs/2506.18943
Andrew Kiruluta, Priscilla Burity: From Pixels and Words to Waves: A Unified Framework for Spectral Dictionary vLLMs https://arxiv.org/abs/2506.18943 https://arxiv.org/pdf/2506.18943 https://arxiv.org/html/2506.18943
June 25, 2025 at 6:27 AM
Andrew Kiruluta, Priscilla Burity: From Pixels and Words to Waves: A Unified Framework for Spectral Dictionary vLLMs https://arxiv.org/abs/2506.18943 https://arxiv.org/pdf/2506.18943 https://arxiv.org/html/2506.18943
Two PolarVis presentations this week: (1) on the (mis)uses of VLLMs for analysing climate change visuals, today at the CCVision Network Meeting, and (2) on methods for longitudinal coordination detection applied to PolarVis data, tomorrow at SunBelt. @lrossi.bsky.social @matmagnani.bsky.social


June 24, 2025 at 11:42 AM
Two PolarVis presentations this week: (1) on the (mis)uses of VLLMs for analysing climate change visuals, today at the CCVision Network Meeting, and (2) on methods for longitudinal coordination detection applied to PolarVis data, tomorrow at SunBelt. @lrossi.bsky.social @matmagnani.bsky.social
I'm pretty happy to present our work on using VLLMs to achieve semantic clustering at #ica25. (Centennial A at 9.00 if you are curious ;-))
June 13, 2025 at 2:39 PM
I'm pretty happy to present our work on using VLLMs to achieve semantic clustering at #ica25. (Centennial A at 9.00 if you are curious ;-))

Line of Sight: On Linear Representations in VLLMs #DL #AI #ML #DeepLearning #ArtificialIntelligence #MachineLearning #ComputerVision #LLM #VLM #LVLM
arxiv.org/html/2506.04...
arxiv.org/html/2506.04...

Line of Sight: On Linear Representations in VLLMs
Language models can be equipped with multimodal capabilities by fine-tuning on embeddings of visual inputs. But how do such multimodal models represent images in their hidden activations? We explore…
arxiv.org
June 12, 2025 at 12:14 PM
Line of Sight: On Linear Representations in VLLMs #DL #AI #ML #DeepLearning #ArtificialIntelligence #MachineLearning #ComputerVision #LLM #VLM #LVLM
arxiv.org/html/2506.04...
arxiv.org/html/2506.04...

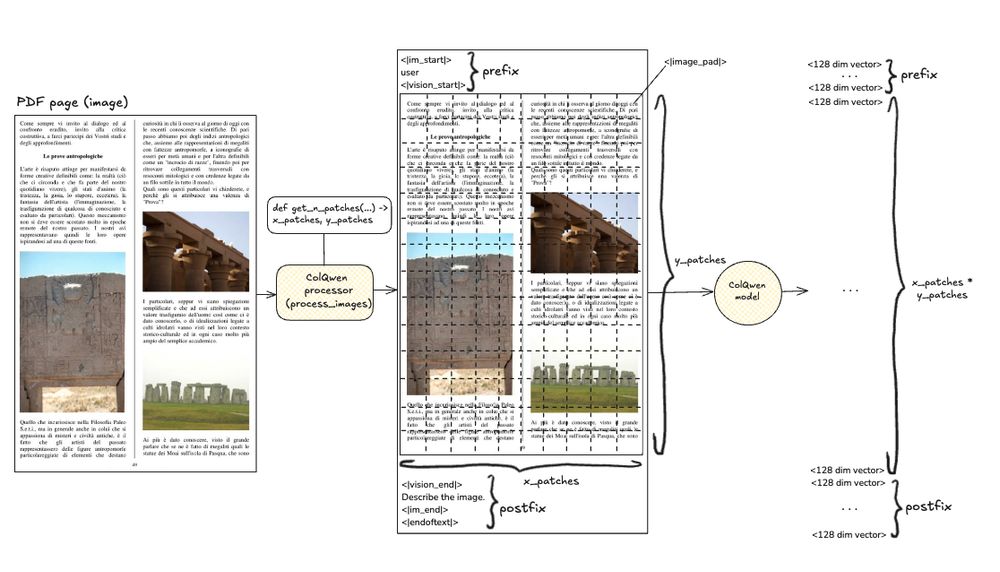
ColPali is cool.
But scaling it to 20,000+ PDF pages? Brutal.
VLLMs like ColPali and ColQwen create thousands of vectors per page.
@qdrant_engine solves this, but only if you optimize smart.
Here’s how to scale visual PDF retrieval without melting your GPU:
But scaling it to 20,000+ PDF pages? Brutal.
VLLMs like ColPali and ColQwen create thousands of vectors per page.
@qdrant_engine solves this, but only if you optimize smart.
Here’s how to scale visual PDF retrieval without melting your GPU:
June 11, 2025 at 9:00 AM
ColPali is cool.
But scaling it to 20,000+ PDF pages? Brutal.
VLLMs like ColPali and ColQwen create thousands of vectors per page.
@qdrant_engine solves this, but only if you optimize smart.
Here’s how to scale visual PDF retrieval without melting your GPU:
But scaling it to 20,000+ PDF pages? Brutal.
VLLMs like ColPali and ColQwen create thousands of vectors per page.
@qdrant_engine solves this, but only if you optimize smart.
Here’s how to scale visual PDF retrieval without melting your GPU:

New research shows how Vision-Language Models (VLLMs) represent image concepts within hidden layers, discovering distinct features that enhance multimodal learning. Sparse Autoencoders reveal a shared representation of images and text evolving deeper in the model. https://arxiv.org/abs/2506.04706

Line of Sight: On Linear Representations in VLLMs
ArXiv link for Line of Sight: On Linear Representations in VLLMs
arxiv.org
June 7, 2025 at 2:30 AM
New research shows how Vision-Language Models (VLLMs) represent image concepts within hidden layers, discovering distinct features that enhance multimodal learning. Sparse Autoencoders reveal a shared representation of images and text evolving deeper in the model. https://arxiv.org/abs/2506.04706