



Zhaochong An
@zhaochongan.bsky.social
PhD student at University of Copenhagen🇩🇰
Member of @belongielab.org, ELLIS @ellis.eu, and Pioneer Centre for AI🤖
Computer Vision | Multimodality
MSc CS at ETH Zurich
🔗: zhaochongan.github.io/
Member of @belongielab.org, ELLIS @ellis.eu, and Pioneer Centre for AI🤖
Computer Vision | Multimodality
MSc CS at ETH Zurich
🔗: zhaochongan.github.io/
I will present our #ICLR2025 Spotlight paper MM-FSS this week in Singapore!
Curious how MULTIMODALITY can enhance FEW-SHOT 3D SEGMENTATION WITHOUT any additional cost? Come chat with us at the poster session — always happy to connect!🤝
🗓️ Fri 25 Apr, 3 - 5:30 pm
📍 Hall 3 + Hall 2B #504
More follow
Curious how MULTIMODALITY can enhance FEW-SHOT 3D SEGMENTATION WITHOUT any additional cost? Come chat with us at the poster session — always happy to connect!🤝
🗓️ Fri 25 Apr, 3 - 5:30 pm
📍 Hall 3 + Hall 2B #504
More follow

April 23, 2025 at 2:39 AM
I will present our #ICLR2025 Spotlight paper MM-FSS this week in Singapore!
Curious how MULTIMODALITY can enhance FEW-SHOT 3D SEGMENTATION WITHOUT any additional cost? Come chat with us at the poster session — always happy to connect!🤝
🗓️ Fri 25 Apr, 3 - 5:30 pm
📍 Hall 3 + Hall 2B #504
More follow
Curious how MULTIMODALITY can enhance FEW-SHOT 3D SEGMENTATION WITHOUT any additional cost? Come chat with us at the poster session — always happy to connect!🤝
🗓️ Fri 25 Apr, 3 - 5:30 pm
📍 Hall 3 + Hall 2B #504
More follow
6/ The result? New SOTA few-shot performance that opens up exciting possibilities for multimodal adaptations in robotics, personalization, virtual reality, and more! ☀️

February 11, 2025 at 5:53 PM
6/ The result? New SOTA few-shot performance that opens up exciting possibilities for multimodal adaptations in robotics, personalization, virtual reality, and more! ☀️
5/ By fusing these modalities, MM-FSS generalizes to novel classes more effectively—even when the 3D-only connection between support and query is weak. 🚀

February 11, 2025 at 5:52 PM
5/ By fusing these modalities, MM-FSS generalizes to novel classes more effectively—even when the 3D-only connection between support and query is weak. 🚀
4/ On the model side, our multimodal fusion designs harness cross-modal complementary knowledge to boost novel class learning, and test-time cross-modality calibration mitigates training bias.

February 11, 2025 at 5:52 PM
4/ On the model side, our multimodal fusion designs harness cross-modal complementary knowledge to boost novel class learning, and test-time cross-modality calibration mitigates training bias.
3/ That’s where MM-FSS comes in! We introduce two commonly overlooked modalities:
💠 2D images (leveraged implicitly during pretraining)
💠 Text (using class names)
—all at no extra cost beyond the 3D-only setup. ✨
💠 2D images (leveraged implicitly during pretraining)
💠 Text (using class names)
—all at no extra cost beyond the 3D-only setup. ✨

February 11, 2025 at 5:51 PM
3/ That’s where MM-FSS comes in! We introduce two commonly overlooked modalities:
💠 2D images (leveraged implicitly during pretraining)
💠 Text (using class names)
—all at no extra cost beyond the 3D-only setup. ✨
💠 2D images (leveraged implicitly during pretraining)
💠 Text (using class names)
—all at no extra cost beyond the 3D-only setup. ✨
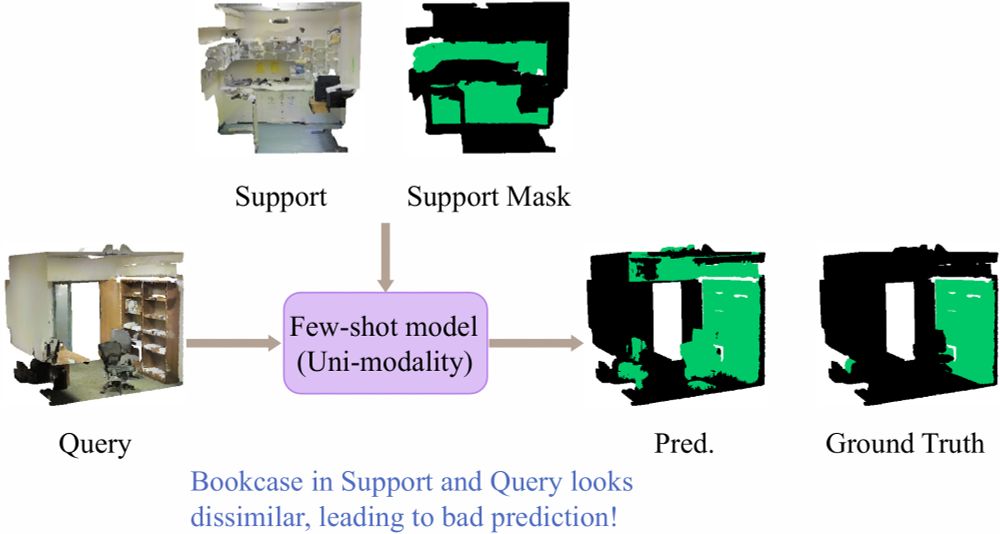
2/ Previous methods rely solely on a single modality—few-shot 3D support samples—to learn novel class knowledge.
However, when support and query objects look very different, performance can suffer, limiting effective few-shot adaptation. 🙁
However, when support and query objects look very different, performance can suffer, limiting effective few-shot adaptation. 🙁
February 11, 2025 at 5:51 PM
2/ Previous methods rely solely on a single modality—few-shot 3D support samples—to learn novel class knowledge.
However, when support and query objects look very different, performance can suffer, limiting effective few-shot adaptation. 🙁
However, when support and query objects look very different, performance can suffer, limiting effective few-shot adaptation. 🙁
1/ Our previous work, COSeg, showed that explicitly modeling support–query relationships via correlation optimization can achieve SOTA 3D few-shot segmentation.
With MM-FSS, we take it even further!
Ref: COSeg arxiv.org/pdf/2410.22489
With MM-FSS, we take it even further!
Ref: COSeg arxiv.org/pdf/2410.22489

February 11, 2025 at 5:50 PM
1/ Our previous work, COSeg, showed that explicitly modeling support–query relationships via correlation optimization can achieve SOTA 3D few-shot segmentation.
With MM-FSS, we take it even further!
Ref: COSeg arxiv.org/pdf/2410.22489
With MM-FSS, we take it even further!
Ref: COSeg arxiv.org/pdf/2410.22489
Thrilled to announce "Multimodality Helps Few-shot 3D Point Cloud Semantic Segmentation" is accepted as a Spotlight (5%) at #ICLR2025!
Our model MM-FSS leverages 3D, 2D, & text modalities for robust few-shot 3D segmentation—all without extra labeling cost. 🤩
arxiv.org/pdf/2410.22489
More details👇
Our model MM-FSS leverages 3D, 2D, & text modalities for robust few-shot 3D segmentation—all without extra labeling cost. 🤩
arxiv.org/pdf/2410.22489
More details👇
February 11, 2025 at 5:49 PM
Thrilled to announce "Multimodality Helps Few-shot 3D Point Cloud Semantic Segmentation" is accepted as a Spotlight (5%) at #ICLR2025!
Our model MM-FSS leverages 3D, 2D, & text modalities for robust few-shot 3D segmentation—all without extra labeling cost. 🤩
arxiv.org/pdf/2410.22489
More details👇
Our model MM-FSS leverages 3D, 2D, & text modalities for robust few-shot 3D segmentation—all without extra labeling cost. 🤩
arxiv.org/pdf/2410.22489
More details👇