



Yoav Gur Arieh
@yoav.ml
Pinned
Yoav Gur Arieh
@yoav.ml
· Oct 8
🧠 To reason over text and track entities, we find that language models use three types of 'pointers'!
They were thought to rely only on a positional one—but when many entities appear, that system breaks down.
Our new paper shows what these pointers are and how they interact 👇
They were thought to rely only on a positional one—but when many entities appear, that system breaks down.
Our new paper shows what these pointers are and how they interact 👇
I think I found the latent direction in Gemma (an SAE feature) that represents the pandemic era...
Interpreted by projecting the vector to vocabulary space, yielding a list of tokens associated with it
Interpreted by projecting the vector to vocabulary space, yielding a list of tokens associated with it

October 29, 2025 at 9:15 PM
I think I found the latent direction in Gemma (an SAE feature) that represents the pandemic era...
Interpreted by projecting the vector to vocabulary space, yielding a list of tokens associated with it
Interpreted by projecting the vector to vocabulary space, yielding a list of tokens associated with it
Two weeks ago I posted about our recent paper, which shows that to bind entities, LMs use three mechanisms: positional, lexical and reflexive.
We were curious how these mechanisms develop throughout training, so we evaluated their existence across OLMo checkpoints 👇
We were curious how these mechanisms develop throughout training, so we evaluated their existence across OLMo checkpoints 👇
October 21, 2025 at 7:40 PM
Two weeks ago I posted about our recent paper, which shows that to bind entities, LMs use three mechanisms: positional, lexical and reflexive.
We were curious how these mechanisms develop throughout training, so we evaluated their existence across OLMo checkpoints 👇
We were curious how these mechanisms develop throughout training, so we evaluated their existence across OLMo checkpoints 👇
🧠 To reason over text and track entities, we find that language models use three types of 'pointers'!
They were thought to rely only on a positional one—but when many entities appear, that system breaks down.
Our new paper shows what these pointers are and how they interact 👇
They were thought to rely only on a positional one—but when many entities appear, that system breaks down.
Our new paper shows what these pointers are and how they interact 👇
October 8, 2025 at 2:56 PM
🧠 To reason over text and track entities, we find that language models use three types of 'pointers'!
They were thought to rely only on a positional one—but when many entities appear, that system breaks down.
Our new paper shows what these pointers are and how they interact 👇
They were thought to rely only on a positional one—but when many entities appear, that system breaks down.
Our new paper shows what these pointers are and how they interact 👇
New Paper Alert! Can we precisely erase conceptual knowledge from LLM parameters?
Most methods are shallow, coarse, or overreach, adversely affecting related or general knowledge.
We introduce🪝𝐏𝐈𝐒𝐂𝐄𝐒 — a general framework for Precise In-parameter Concept EraSure. 🧵 1/
Most methods are shallow, coarse, or overreach, adversely affecting related or general knowledge.
We introduce🪝𝐏𝐈𝐒𝐂𝐄𝐒 — a general framework for Precise In-parameter Concept EraSure. 🧵 1/

May 29, 2025 at 4:22 PM
New Paper Alert! Can we precisely erase conceptual knowledge from LLM parameters?
Most methods are shallow, coarse, or overreach, adversely affecting related or general knowledge.
We introduce🪝𝐏𝐈𝐒𝐂𝐄𝐒 — a general framework for Precise In-parameter Concept EraSure. 🧵 1/
Most methods are shallow, coarse, or overreach, adversely affecting related or general knowledge.
We introduce🪝𝐏𝐈𝐒𝐂𝐄𝐒 — a general framework for Precise In-parameter Concept EraSure. 🧵 1/
Reposted by Yoav Gur Arieh

How can we interpret LLM features at scale? 🤔
Current pipelines use activating inputs, which is costly and ignores how features causally affect model outputs!
We propose efficient output-centric methods that better predict the steering effect of a feature.
New preprint led by @yoav.ml 🧵1/
Current pipelines use activating inputs, which is costly and ignores how features causally affect model outputs!
We propose efficient output-centric methods that better predict the steering effect of a feature.
New preprint led by @yoav.ml 🧵1/
January 28, 2025 at 7:34 PM
How can we interpret LLM features at scale? 🤔
Current pipelines use activating inputs, which is costly and ignores how features causally affect model outputs!
We propose efficient output-centric methods that better predict the steering effect of a feature.
New preprint led by @yoav.ml 🧵1/
Current pipelines use activating inputs, which is costly and ignores how features causally affect model outputs!
We propose efficient output-centric methods that better predict the steering effect of a feature.
New preprint led by @yoav.ml 🧵1/
Reposted by Yoav Gur Arieh
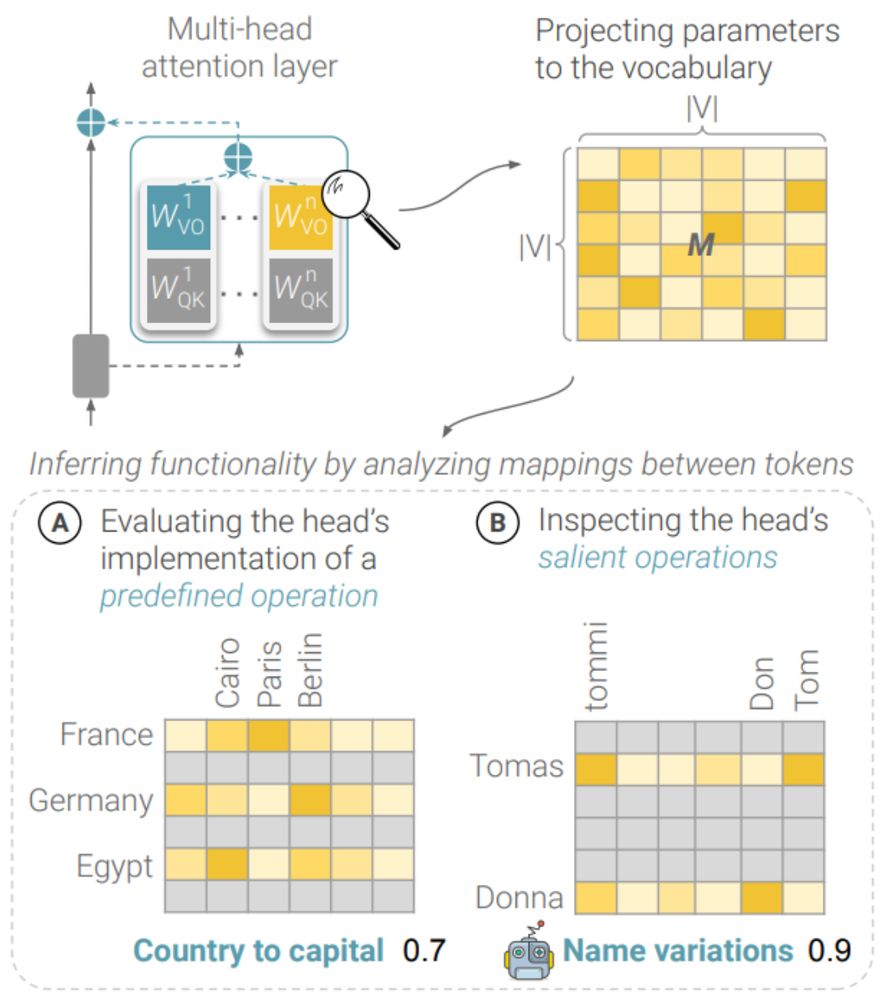
What's in an attention head? 🤯
We present an efficient framework – MAPS – for inferring the functionality of attention heads in LLMs ✨directly from their parameters✨
A new preprint with Amit Elhelo 🧵 (1/10)
We present an efficient framework – MAPS – for inferring the functionality of attention heads in LLMs ✨directly from their parameters✨
A new preprint with Amit Elhelo 🧵 (1/10)
December 18, 2024 at 5:55 PM
What's in an attention head? 🤯
We present an efficient framework – MAPS – for inferring the functionality of attention heads in LLMs ✨directly from their parameters✨
A new preprint with Amit Elhelo 🧵 (1/10)
We present an efficient framework – MAPS – for inferring the functionality of attention heads in LLMs ✨directly from their parameters✨
A new preprint with Amit Elhelo 🧵 (1/10)