



@yanmingwan.bsky.social
Overall, we propose CURIO for enhancing personalization in LLMs for multi-turn dialogs, which encourages LLMs to actively learn user traits and adapt its responses accordingly.
This work was done with my awesome collaborators:
Jiaxing Wu, Marwa Abdulhai, Lior Shani, and @natashajaques.bsky.social
This work was done with my awesome collaborators:
Jiaxing Wu, Marwa Abdulhai, Lior Shani, and @natashajaques.bsky.social

July 8, 2025 at 5:15 PM
Overall, we propose CURIO for enhancing personalization in LLMs for multi-turn dialogs, which encourages LLMs to actively learn user traits and adapt its responses accordingly.
This work was done with my awesome collaborators:
Jiaxing Wu, Marwa Abdulhai, Lior Shani, and @natashajaques.bsky.social
This work was done with my awesome collaborators:
Jiaxing Wu, Marwa Abdulhai, Lior Shani, and @natashajaques.bsky.social
Baselines and entropy-based rewards lead to "controlling behavior", where the model gets high rewards by convincing the user to adopt a particular preference that is easier to cater to, rather than adhering to the ground-truth. "Grounded" rewards stop this reward hacking. (8/9)

July 8, 2025 at 4:53 PM
Baselines and entropy-based rewards lead to "controlling behavior", where the model gets high rewards by convincing the user to adopt a particular preference that is easier to cater to, rather than adhering to the ground-truth. "Grounded" rewards stop this reward hacking. (8/9)
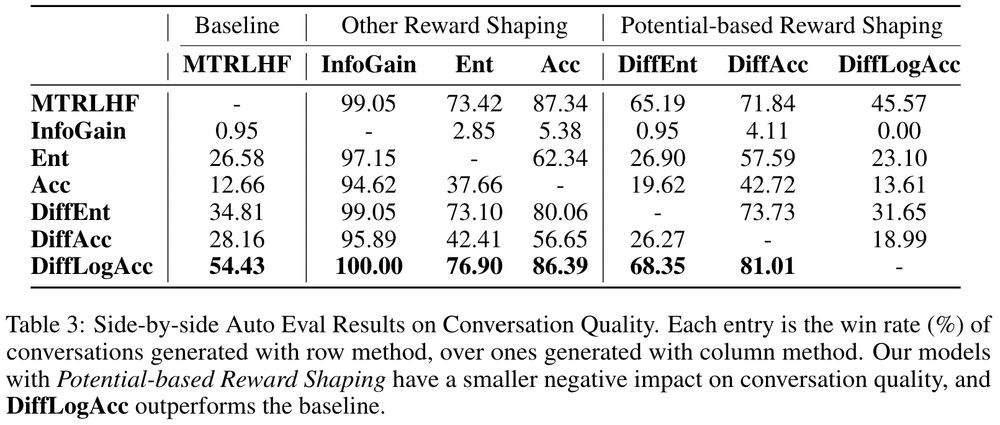
With a proper reward choice, CURIO models achieve personalization without compromising coherence and overall quality. The baseline is trained to optimize conversation quality using exactly the same prompt for eval. DiffLogAcc outperforms the baseline and all other models. (7/9)
July 8, 2025 at 4:52 PM
With a proper reward choice, CURIO models achieve personalization without compromising coherence and overall quality. The baseline is trained to optimize conversation quality using exactly the same prompt for eval. DiffLogAcc outperforms the baseline and all other models. (7/9)
The second task has a more complicated reward, where personalization is relevant to the model performance in conducting a dialog but not the ultimate goal. CURIO models with accuracy-based intrinsic rewards remain effective and significantly improve personalization ability. (6/9)

July 8, 2025 at 4:52 PM
The second task has a more complicated reward, where personalization is relevant to the model performance in conducting a dialog but not the ultimate goal. CURIO models with accuracy-based intrinsic rewards remain effective and significantly improve personalization ability. (6/9)
On the first task, the agent needs to elicit user information in multi-turn dialogs before making a choice at the end. CURIO can effectively enhance personalization and reduce the generalization gap by "learning how to learn" rather than memorizing superficial user details. (5/9)

July 8, 2025 at 4:51 PM
On the first task, the agent needs to elicit user information in multi-turn dialogs before making a choice at the end. CURIO can effectively enhance personalization and reduce the generalization gap by "learning how to learn" rather than memorizing superficial user details. (5/9)
We discuss the following intrinsic rewards. Intuitively, we encourage gain in prediction accuracy or reduction in entropy. For those which are Potential-based Reward Shaping, the optimality is not affected, and we hypothesize that they potentially accelerate the training. (4/9)

July 8, 2025 at 4:51 PM
We discuss the following intrinsic rewards. Intuitively, we encourage gain in prediction accuracy or reduction in entropy. For those which are Potential-based Reward Shaping, the optimality is not affected, and we hypothesize that they potentially accelerate the training. (4/9)
Intrinsic Motivation is well-studied in RL but applying it to LLMs is non-trivial. The policy and environment models engage in a multi-turn dialog, and a reward model gives an extrinsic reward. On each turn, a user model predicts the belief and computes an intrinsic reward. (3/9)

July 8, 2025 at 4:50 PM
Intrinsic Motivation is well-studied in RL but applying it to LLMs is non-trivial. The policy and environment models engage in a multi-turn dialog, and a reward model gives an extrinsic reward. On each turn, a user model predicts the belief and computes an intrinsic reward. (3/9)
We leverage a user model to incorporate a curiosity reward into standard multi-turn RLHF. Rather than training an LLM only with the end-of-conversation sparse reward, we add a turn-based reward that is given by its improvement in belief over the user type after each action. (2/9)

July 8, 2025 at 4:49 PM
We leverage a user model to incorporate a curiosity reward into standard multi-turn RLHF. Rather than training an LLM only with the end-of-conversation sparse reward, we add a turn-based reward that is given by its improvement in belief over the user type after each action. (2/9)
Personalization methods for LLMs often rely on extensive user history. We introduce Curiosity-driven User-modeling Reward as Intrinsic Objective (CURIO) to encourage actively learning about the user within multi-turn dialogs.
📜 arxiv.org/abs/2504.03206
🌎 sites.google.com/cs.washingto...
📜 arxiv.org/abs/2504.03206
🌎 sites.google.com/cs.washingto...
July 8, 2025 at 4:48 PM
Personalization methods for LLMs often rely on extensive user history. We introduce Curiosity-driven User-modeling Reward as Intrinsic Objective (CURIO) to encourage actively learning about the user within multi-turn dialogs.
📜 arxiv.org/abs/2504.03206
🌎 sites.google.com/cs.washingto...
📜 arxiv.org/abs/2504.03206
🌎 sites.google.com/cs.washingto...