



Xiuying Wei
@xiuyingwei.bsky.social
PhD student @the Caglar Gulcehre Lab for AI Research (CLAIRE) @EPFL. Efficiency, foundation models. https://wimh966.github.io/
We also explored other different aspects of RAT, including parameter allocation, positional encodings, and especially the use of NoPE for length generalization ability, and even the retrieval ability with the RULER benchmark. 🧵7/9

July 12, 2025 at 10:02 AM
We also explored other different aspects of RAT, including parameter allocation, positional encodings, and especially the use of NoPE for length generalization ability, and even the retrieval ability with the RULER benchmark. 🧵7/9
Accuracy: We trained 1.3B models and evaluated them on six short-context reasoning tasks, 14 long-context tasks from LongBench, and four SFT tasks. By interleaving RAT’s efficient long-range modeling with strong local interactions, we got top throughput and accuracy. 🧵6/9

July 12, 2025 at 10:02 AM
Accuracy: We trained 1.3B models and evaluated them on six short-context reasoning tasks, 14 long-context tasks from LongBench, and four SFT tasks. By interleaving RAT’s efficient long-range modeling with strong local interactions, we got top throughput and accuracy. 🧵6/9
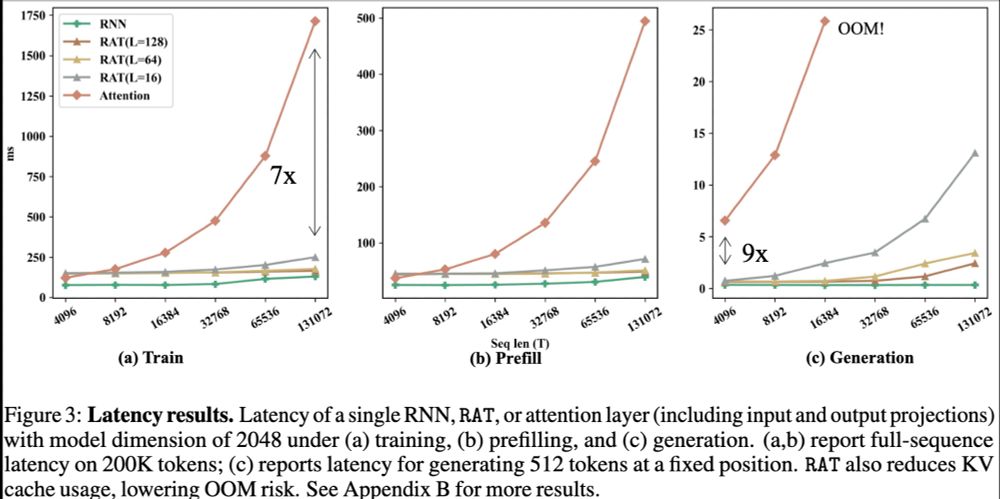
Efficiency: Compared to the Attention, RAT has FLOPs and KV Cache reduced by chunk size L, thus enabling much faster training and generation speed. 🧵5/9
July 12, 2025 at 10:01 AM
Efficiency: Compared to the Attention, RAT has FLOPs and KV Cache reduced by chunk size L, thus enabling much faster training and generation speed. 🧵5/9
In detail, gated recurrence first updates keys/values in each chunk. Softmax attention then queries final keys/values across all past chunks plus the current one. RAT is easy to implement—no custom CUDA/Triton, just PyTorch higher-order ops like flex attention. 🧵3/9

July 12, 2025 at 10:01 AM
In detail, gated recurrence first updates keys/values in each chunk. Softmax attention then queries final keys/values across all past chunks plus the current one. RAT is easy to implement—no custom CUDA/Triton, just PyTorch higher-order ops like flex attention. 🧵3/9
RAT splits long sequences into chunks. Inside each chunk, recurrence models local dependencies, softmax attention then operates on compressed chunk-level representations. By adjusting chunk size L, RAT moves between attention (L=1) and recurrence (L=T). 🧵2/9

July 12, 2025 at 10:00 AM
RAT splits long sequences into chunks. Inside each chunk, recurrence models local dependencies, softmax attention then operates on compressed chunk-level representations. By adjusting chunk size L, RAT moves between attention (L=1) and recurrence (L=T). 🧵2/9
⚡️🧠 Excited to share our recent work on long-context efficiency! We propose a new layer called RAT—fast and lightweight like RNNs, yet powerful like Attention. 🐭✨ This is the joint effort with Anunay Yadav, @razvan-pascanu.bsky.social @caglarai.bsky.social !

July 12, 2025 at 9:59 AM
⚡️🧠 Excited to share our recent work on long-context efficiency! We propose a new layer called RAT—fast and lightweight like RNNs, yet powerful like Attention. 🐭✨ This is the joint effort with Anunay Yadav, @razvan-pascanu.bsky.social @caglarai.bsky.social !