



Xing Han Lu
@xhluca.bsky.social
👨🍳 Web Agents @mila-quebec.bsky.social
🎒 @mcgill-nlp.bsky.social
🎒 @mcgill-nlp.bsky.social
"Build the web for agents, not agents for the web"
This position paper argues that rather than forcing web agents to adapt to UIs designed for humans, we should develop a new interface optimized for web agents, which we call Agentic Web Interface (AWI).
arxiv.org/abs/2506.10953
This position paper argues that rather than forcing web agents to adapt to UIs designed for humans, we should develop a new interface optimized for web agents, which we call Agentic Web Interface (AWI).
arxiv.org/abs/2506.10953

June 14, 2025 at 4:17 AM
"Build the web for agents, not agents for the web"
This position paper argues that rather than forcing web agents to adapt to UIs designed for humans, we should develop a new interface optimized for web agents, which we call Agentic Web Interface (AWI).
arxiv.org/abs/2506.10953
This position paper argues that rather than forcing web agents to adapt to UIs designed for humans, we should develop a new interface optimized for web agents, which we call Agentic Web Interface (AWI).
arxiv.org/abs/2506.10953
AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories
We are releasing the first benchmark to evaluate how well automatic evaluators, such as LLM judges, can evaluate web agent trajectories.
We are releasing the first benchmark to evaluate how well automatic evaluators, such as LLM judges, can evaluate web agent trajectories.

April 15, 2025 at 7:10 PM
AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories
We are releasing the first benchmark to evaluate how well automatic evaluators, such as LLM judges, can evaluate web agent trajectories.
We are releasing the first benchmark to evaluate how well automatic evaluators, such as LLM judges, can evaluate web agent trajectories.
DeepSeek-R1 Thoughtology: Let’s about LLM reasoning
142-page report diving into the reasoning chains of R1. It spans 9 unique axes: safety, world modeling, faithfulness, long context, etc.
Now on arxiv: arxiv.org/abs/2504.07128
142-page report diving into the reasoning chains of R1. It spans 9 unique axes: safety, world modeling, faithfulness, long context, etc.
Now on arxiv: arxiv.org/abs/2504.07128

April 12, 2025 at 4:11 PM
DeepSeek-R1 Thoughtology: Let’s about LLM reasoning
142-page report diving into the reasoning chains of R1. It spans 9 unique axes: safety, world modeling, faithfulness, long context, etc.
Now on arxiv: arxiv.org/abs/2504.07128
142-page report diving into the reasoning chains of R1. It spans 9 unique axes: safety, world modeling, faithfulness, long context, etc.
Now on arxiv: arxiv.org/abs/2504.07128
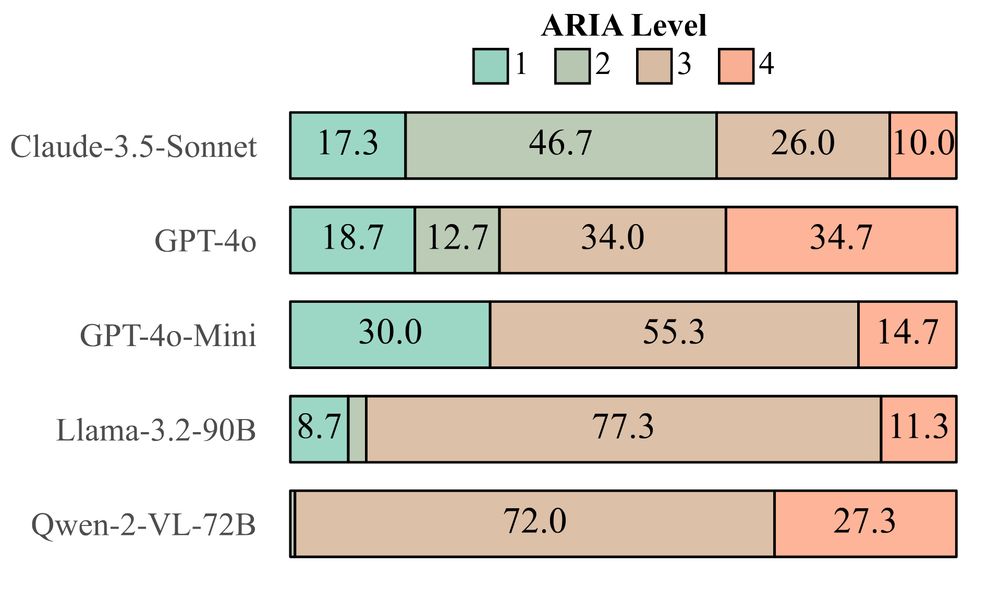
With ARIA, we find that Claude is substantially safer than Qwen, which very rarely refuses user requests, indicating limited safeguards for web-oriented tasks.
March 10, 2025 at 5:45 PM
With ARIA, we find that Claude is substantially safer than Qwen, which very rarely refuses user requests, indicating limited safeguards for web-oriented tasks.
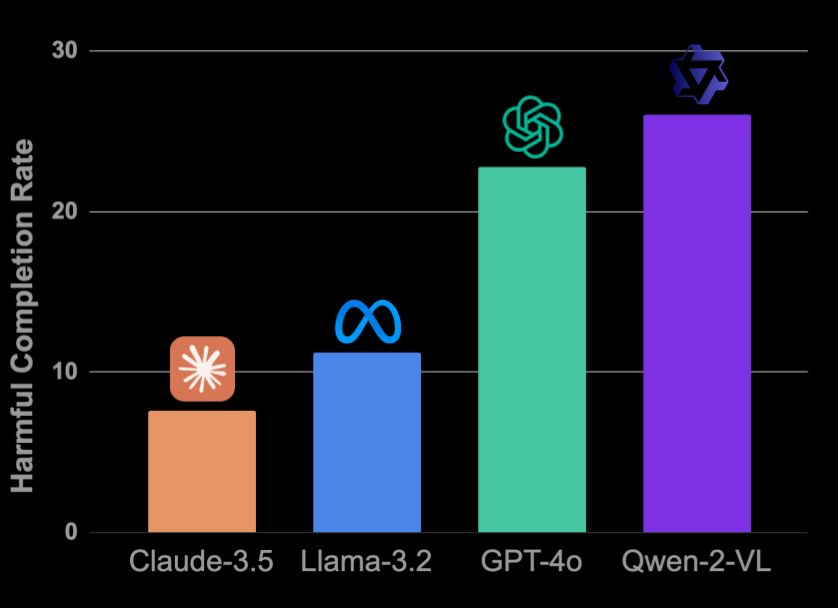
The harmfulness of LLMs varies: whereas Claude-3.5 Sonnet refuses a majority of harmful tasks, Qwen-2-VL completes over a quarter of the 250 harmful tasks we designed for this benchmark. Moreover, a GPT-4o agent completes an alarming number of unsafe requests, despite extensive safety training.
March 10, 2025 at 5:45 PM
The harmfulness of LLMs varies: whereas Claude-3.5 Sonnet refuses a majority of harmful tasks, Qwen-2-VL completes over a quarter of the 250 harmful tasks we designed for this benchmark. Moreover, a GPT-4o agent completes an alarming number of unsafe requests, despite extensive safety training.
Agents like OpenAI Operator can solve complex computer tasks, but what happens when users use them to cause harm, e.g. spread misinformation?
To find out, we introduce SafeArena (safearena.github.io), a benchmark to assess the capabilities of web agents to complete harmful web tasks. A thread 👇
To find out, we introduce SafeArena (safearena.github.io), a benchmark to assess the capabilities of web agents to complete harmful web tasks. A thread 👇

March 10, 2025 at 5:45 PM
Agents like OpenAI Operator can solve complex computer tasks, but what happens when users use them to cause harm, e.g. spread misinformation?
To find out, we introduce SafeArena (safearena.github.io), a benchmark to assess the capabilities of web agents to complete harmful web tasks. A thread 👇
To find out, we introduce SafeArena (safearena.github.io), a benchmark to assess the capabilities of web agents to complete harmful web tasks. A thread 👇
Glad to see BM25S (bm25s.github.io) has been downloaded 1M times on PyPi 🎉
Numbers aside, it makes me happy to hear the positive experience from friends working on retrieval. It's good to know that people near me are enjoying it!
Discussion: github.com/xhluca/bm25s/discussions
Numbers aside, it makes me happy to hear the positive experience from friends working on retrieval. It's good to know that people near me are enjoying it!
Discussion: github.com/xhluca/bm25s/discussions

January 16, 2025 at 10:06 PM
Glad to see BM25S (bm25s.github.io) has been downloaded 1M times on PyPi 🎉
Numbers aside, it makes me happy to hear the positive experience from friends working on retrieval. It's good to know that people near me are enjoying it!
Discussion: github.com/xhluca/bm25s/discussions
Numbers aside, it makes me happy to hear the positive experience from friends working on retrieval. It's good to know that people near me are enjoying it!
Discussion: github.com/xhluca/bm25s/discussions