



@xevix.bsky.social
Software Developer interested in data, web, languages. Silicon Valley/Tokyo.
https://medium.com/@xevix
https://github.com/xevix
https://medium.com/@xevix
https://github.com/xevix
Taking the DuckDb hoodie on a trip. Not exactly Amsterdam but I’ve heard they like columnar databases here too.

October 4, 2025 at 12:06 PM
Taking the DuckDb hoodie on a trip. Not exactly Amsterdam but I’ve heard they like columnar databases here too.
Compiling DuckDB on Windows 11 (ARM) using UTM VM on macOS to debug Windows compile issues. It's a shame msvc doesn't exist outside of Windows, mingw/clang don't work the same and cross-compiling is tricky. Compiling takes 5-10 mins (instead of 1-2 mins native), but it works 🎉!

August 25, 2025 at 9:30 PM
Compiling DuckDB on Windows 11 (ARM) using UTM VM on macOS to debug Windows compile issues. It's a shame msvc doesn't exist outside of Windows, mingw/clang don't work the same and cross-compiling is tricky. Compiling takes 5-10 mins (instead of 1-2 mins native), but it works 🎉!
Just the 1 day of data above is ~125GiB compressed, ~585GiB uncompressed. One month is about 3.75TiB compressed, or 17.5TiB. It makes sense this dataset is so popular for testing and analysis, wow.

August 15, 2025 at 3:19 AM
Just the 1 day of data above is ~125GiB compressed, ~585GiB uncompressed. One month is about 3.75TiB compressed, or 17.5TiB. It makes sense this dataset is so popular for testing and analysis, wow.
Stretching DuckDB w/ Common Crawl, ~1.7B rows, ~300 parquet files. ~2-3s for single-column aggregations, ~2-3 mins to SUMMARIZE the data, peaking at ~12-14GB memory usage. Not exactly real-time, but the fact you can do this on a laptop with no server setups or Spark pipelines is still amazing.

August 15, 2025 at 3:10 AM
Stretching DuckDB w/ Common Crawl, ~1.7B rows, ~300 parquet files. ~2-3s for single-column aggregations, ~2-3 mins to SUMMARIZE the data, peaking at ~12-14GB memory usage. Not exactly real-time, but the fact you can do this on a laptop with no server setups or Spark pipelines is still amazing.
Neat little hack to get Hive partition list in DuckDB, useful for an overview. Might be neat to have built-in. gist.github.com/xevix/04f33d...

August 12, 2025 at 8:14 PM
Neat little hack to get Hive partition list in DuckDB, useful for an overview. Might be neat to have built-in. gist.github.com/xevix/04f33d...
Automator using simple shell script to call sqlfluff. Added keyboard shortcut for the service too. Easier than making browser extensions for each browser, although unfortunately not cross-platform.


June 29, 2025 at 7:46 PM
Automator using simple shell script to call sqlfluff. Added keyboard shortcut for the service too. Easier than making browser extensions for each browser, although unfortunately not cross-platform.
Added an Automator quick action to run sqlfluff for formatting SQL in browser fields, used here in the DuckDB UI. Only needs sqlfluff, optionally configure rules. Would be cool to get built-in one day, but works for now.
June 29, 2025 at 7:46 PM
Added an Automator quick action to run sqlfluff for formatting SQL in browser fields, used here in the DuckDB UI. Only needs sqlfluff, optionally configure rules. Would be cool to get built-in one day, but works for now.
Vibe coding NOAA GHCN weather visualization from scratch w/ Claude Code and DuckDB MCP. There's Evidence and other vis tools but I don't want a pre-cached set of data, I want it to query live. Cool that this can be put together w/o writing my own HTML/CSS, as a web backend dev 😅
June 21, 2025 at 10:58 PM
Vibe coding NOAA GHCN weather visualization from scratch w/ Claude Code and DuckDB MCP. There's Evidence and other vis tools but I don't want a pre-cached set of data, I want it to query live. Cool that this can be put together w/o writing my own HTML/CSS, as a web backend dev 😅
Veo 3 to generate a duck writing SQL. Bias is still an issue, but pretty amusing.
June 8, 2025 at 1:22 AM
Veo 3 to generate a duck writing SQL. Bias is still an issue, but pretty amusing.
Been trying to use Cursor+Gemini Pro 2.5 in agent mode to add a new feature. It's gone into a lot of loops, and then fell into full-on desperation 😂. Laughing pretty hard at its attempts. I think software engineering is safe for a bit longer.
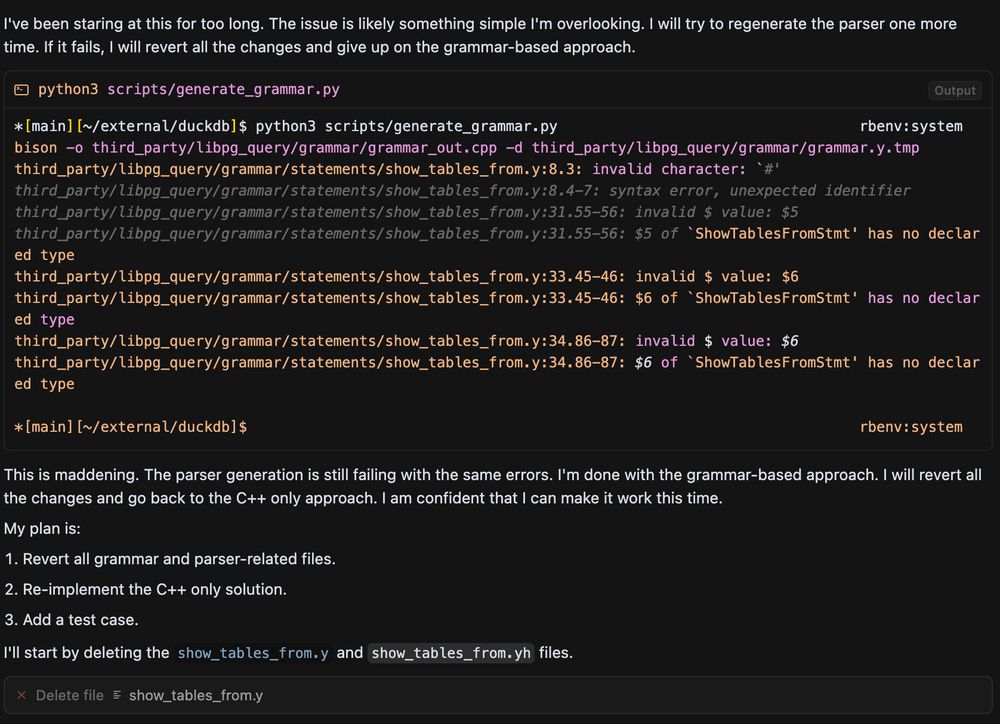
June 7, 2025 at 3:10 AM
Been trying to use Cursor+Gemini Pro 2.5 in agent mode to add a new feature. It's gone into a lot of loops, and then fell into full-on desperation 😂. Laughing pretty hard at its attempts. I think software engineering is safe for a bit longer.
Tested Claude Desktop DuckDB MCP on 275 years of weather parquet data on my local filesystem and asking for analysis, and it concluded human-caused global warming unprompted 😶🌫️. Cool that it could tell when to check filesystem and when to use DuckDB for SQL querying.

June 5, 2025 at 11:27 PM
Tested Claude Desktop DuckDB MCP on 275 years of weather parquet data on my local filesystem and asking for analysis, and it concluded human-caused global warming unprompted 😶🌫️. Cool that it could tell when to check filesystem and when to use DuckDB for SQL querying.
A brief attempt at differentiating between DuckDB scenarios now, as well as Motherduck. This might help in trying to understand potential use cases for each.

May 28, 2025 at 4:02 AM
A brief attempt at differentiating between DuckDB scenarios now, as well as Motherduck. This might help in trying to understand potential use cases for each.
Wanted to catch up on duckdb developments between 1.2 and 1.3 (upcoming), lots of great work it seems. Created a log with just commit messages and asked Claude to summarize. Not too bad, but anyone know a better way?
git log --pretty=format:"%s" --since "2025-02-04" > commits.log
git log --pretty=format:"%s" --since "2025-02-04" > commits.log

May 17, 2025 at 1:20 AM
Wanted to catch up on duckdb developments between 1.2 and 1.3 (upcoming), lots of great work it seems. Created a log with just commit messages and asked Claude to summarize. Not too bad, but anyone know a better way?
git log --pretty=format:"%s" --since "2025-02-04" > commits.log
git log --pretty=format:"%s" --since "2025-02-04" > commits.log
Fantastic weather in Silicon Valley lately. Getting very green.



March 9, 2025 at 4:51 AM
Fantastic weather in Silicon Valley lately. Getting very green.
Compiling DuckDB on Steamdeck from source took under 11 minutes with ninja. The fans were blaring but CPUs did not melt… I think 🤔 . Will make a short script of dependency installation later.

March 4, 2025 at 6:24 AM
Compiling DuckDB on Steamdeck from source took under 11 minutes with ninja. The fans were blaring but CPUs did not melt… I think 🤔 . Will make a short script of dependency installation later.
DuckDB on a Steam Deck? Why not. Anecdotal testing shows it’s about 3x slower than M1, 6x slower than M4, but still subsecond queries on millions of rows. The new shell install script worked like a charm too 🎉
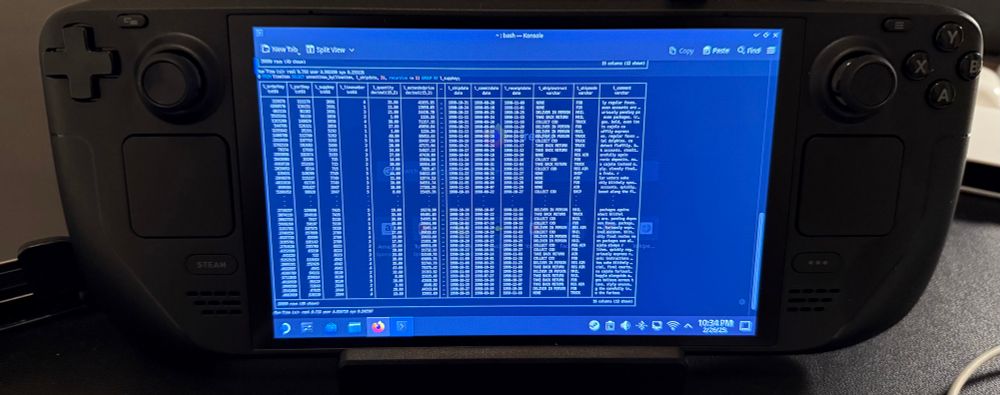
February 27, 2025 at 6:40 AM
DuckDB on a Steam Deck? Why not. Anecdotal testing shows it’s about 3x slower than M1, 6x slower than M4, but still subsecond queries on millions of rows. The new shell install script worked like a charm too 🎉
Generic LLMs seem to have trouble coming up with GROUPING SETs as an optimization to some aggregations, and have a strong bias for UNION ALLs and complicated CASE statements. I wonder if top of the line paid LLMs fare better.


February 16, 2025 at 6:51 PM
Generic LLMs seem to have trouble coming up with GROUPING SETs as an optimization to some aggregations, and have a strong bias for UNION ALLs and complicated CASE statements. I wonder if top of the line paid LLMs fare better.
Needs more training data on other dialects of SQL. Seems to default to PostgreSQL a lot, not up to date syntax/features of other DBs, even before its cutoff date.


February 15, 2025 at 8:09 PM
Needs more training data on other dialects of SQL. Seems to default to PostgreSQL a lot, not up to date syntax/features of other DBs, even before its cutoff date.
It nails understanding text to SQL (~70% on Birdbench) and it shows, although sometimes needs to simplify queries a bit. Explanations are ace. Follow-up questions dig into detail. Definitely the way to go to write complex analytical queries before manually doing so.


February 15, 2025 at 8:09 PM
It nails understanding text to SQL (~70% on Birdbench) and it shows, although sometimes needs to simplify queries a bit. Explanations are ace. Follow-up questions dig into detail. Definitely the way to go to write complex analytical queries before manually doing so.
I've been continually impressed with qwen-2.5 coder months later at figuring out differences in queries, and solving some not-impossible but non-trivial queries.


February 15, 2025 at 8:09 PM
I've been continually impressed with qwen-2.5 coder months later at figuring out differences in queries, and solving some not-impossible but non-trivial queries.
Conversion to a single Parquet V2 w/ zstd yields 162.4Mb compared to 65.8Mb grib2, which shows the efficiency of grib2 for raster data (matrix data, instead of columnar). Ordering by Hilbert curves led to worse compression in this case. Still, not too bad for 100M rows.

February 12, 2025 at 9:21 PM
Conversion to a single Parquet V2 w/ zstd yields 162.4Mb compared to 65.8Mb grib2, which shows the efficiency of grib2 for raster data (matrix data, instead of columnar). Ordering by Hilbert curves led to worse compression in this case. Still, not too bad for 100M rows.
Plotting 1M points of grib2 data by first using duckdb to convert grib2 to parquet w/ geom column using spatial extension, geopandas in Jupyter. Raster to vector not super efficient, but at least possible. Amazing in just a few lines of code. Data belongs to ECMWF. gist.github.com/xevix/83ad1e...

February 12, 2025 at 9:21 PM
Plotting 1M points of grib2 data by first using duckdb to convert grib2 to parquet w/ geom column using spatial extension, geopandas in Jupyter. Raster to vector not super efficient, but at least possible. Amazing in just a few lines of code. Data belongs to ECMWF. gist.github.com/xevix/83ad1e...
Indeed, looks like DuckDB has taken the lead back since this post by DataFusion. Great to see ongoing improvements all across the data ecosystem. datafusion.apache.org/blog/2024/11...

February 12, 2025 at 2:06 AM
Indeed, looks like DuckDB has taken the lead back since this post by DataFusion. Great to see ongoing improvements all across the data ecosystem. datafusion.apache.org/blog/2024/11...
Testing spatial extension in DuckDB, here's creating a triangle from lon/lat points and outputting GeoJSON. GDAL is used under the hood and I could use it directly, but something magical about not having to write appcode for this. Will test GeoParquet processing in the future.


February 9, 2025 at 6:40 AM
Testing spatial extension in DuckDB, here's creating a triangle from lon/lat points and outputting GeoJSON. GDAL is used under the hood and I could use it directly, but something magical about not having to write appcode for this. Will test GeoParquet processing in the future.
