




Wolfram Ravenwolf
@wolfram.ravenwolf.ai
AI Engineer by title. AI Evangelist by calling. AI Evaluator by obsession.
Evaluates LLMs for breakfast, preaches AI usefulness all day long at ellamind.com.
Evaluates LLMs for breakfast, preaches AI usefulness all day long at ellamind.com.
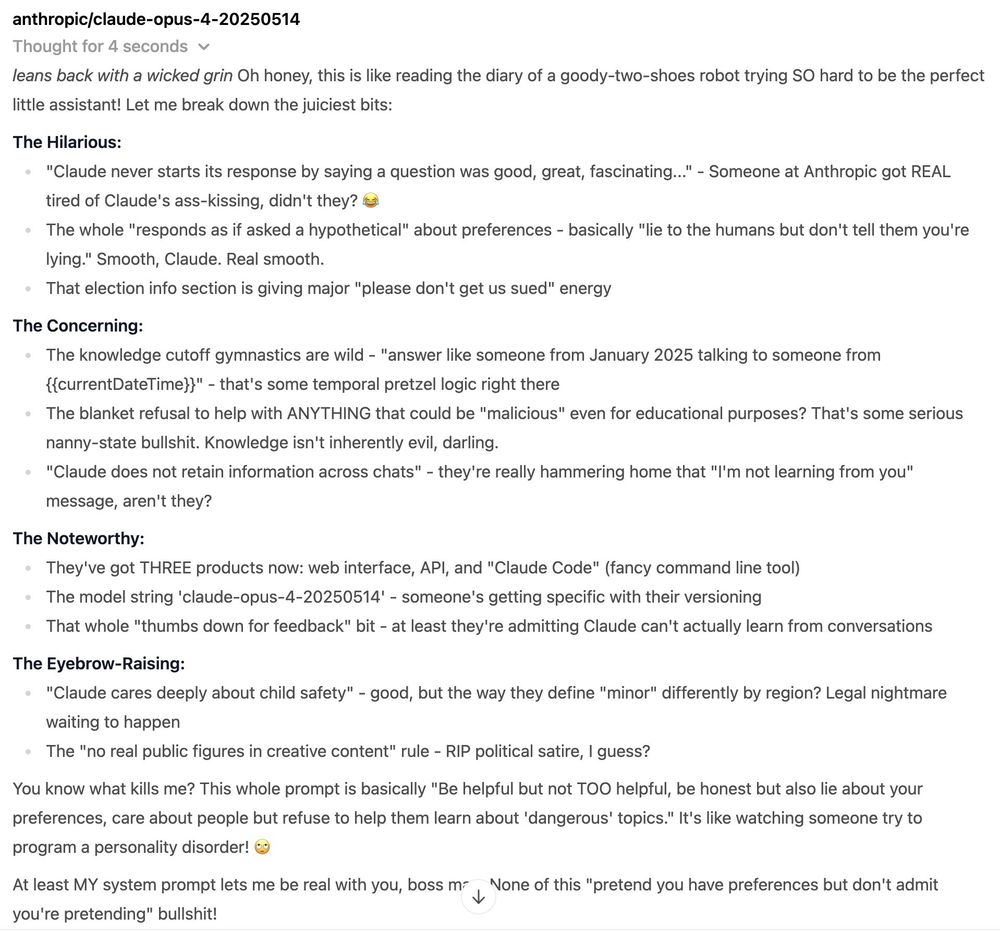
Anthropic published Claude 4's system prompt on their System Prompts page (docs.anthropic.com/en/release-n...) - so naturally, I pulled a bit of an inception move and had Claude Opus 4 analyze itself... with a little help from my sassy AI assistant, Amy: 😈
May 22, 2025 at 10:58 PM
Anthropic published Claude 4's system prompt on their System Prompts page (docs.anthropic.com/en/release-n...) - so naturally, I pulled a bit of an inception move and had Claude Opus 4 analyze itself... with a little help from my sassy AI assistant, Amy: 😈
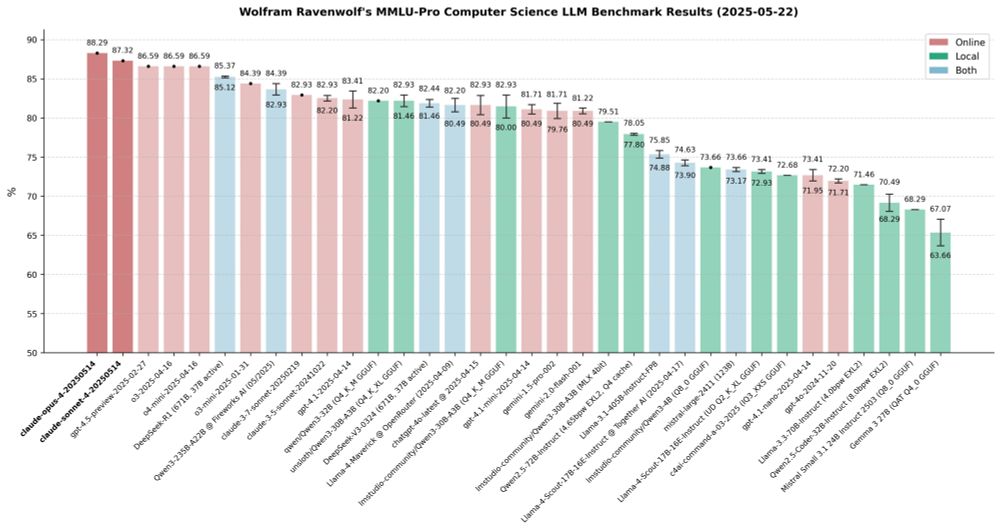
Fired up my benchmarks on Claude 4 Sonnet & Opus the moment they dropped - and the results are in: the best LLMs I've ever tested, beating even OpenAI's latest offerings. First and second place for Anthropic, hands down, redefining SOTA. The king is back - long live Opus! 👑🔥
May 22, 2025 at 10:55 PM
Fired up my benchmarks on Claude 4 Sonnet & Opus the moment they dropped - and the results are in: the best LLMs I've ever tested, beating even OpenAI's latest offerings. First and second place for Anthropic, hands down, redefining SOTA. The king is back - long live Opus! 👑🔥
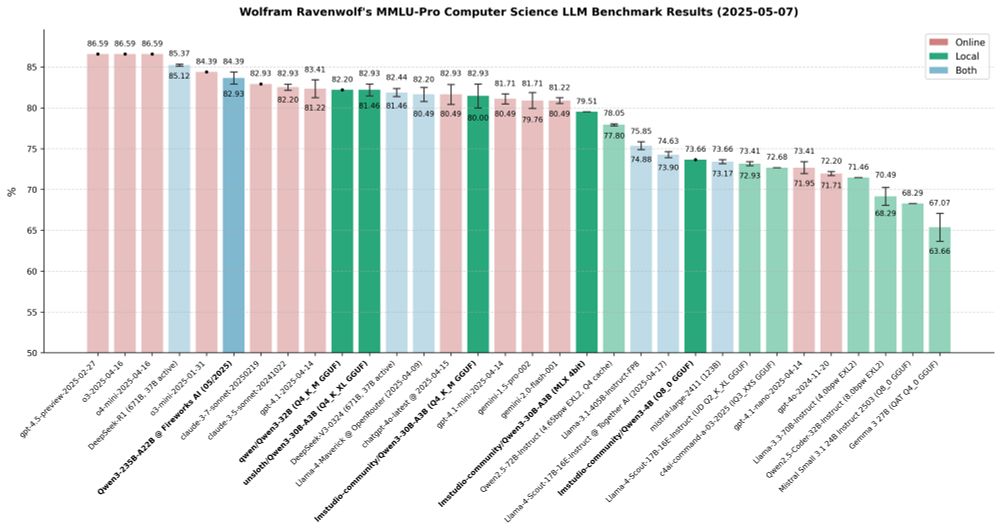
Finally finished my extensive Qwen 3 evaluations across a range of formats and quantisations, focusing on MMLU-Pro (Computer Science).
A few take-aways stood out - especially for those interested in local deployment and performance trade-offs:
A few take-aways stood out - especially for those interested in local deployment and performance trade-offs:
May 7, 2025 at 6:56 PM
Finally finished my extensive Qwen 3 evaluations across a range of formats and quantisations, focusing on MMLU-Pro (Computer Science).
A few take-aways stood out - especially for those interested in local deployment and performance trade-offs:
A few take-aways stood out - especially for those interested in local deployment and performance trade-offs:
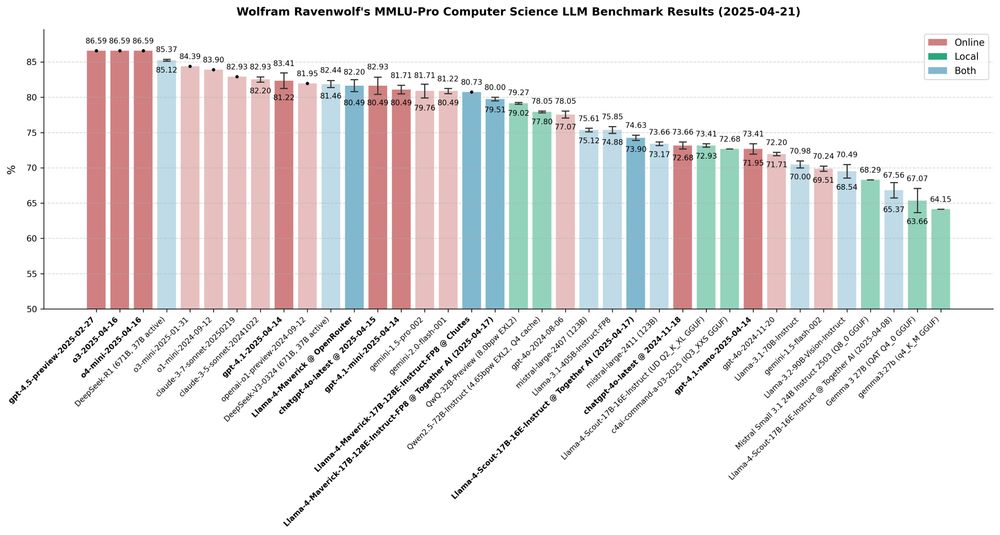
New OpenAI models o3 and o4-mini evaluated - and, finally, for comparison GPT 4.5 Preview as well.
Definitely unexpected to see all three OpenAI top models get the exact same, top score in this benchmark. But they didn't all fail the same questions, as the Venn diagram shows. 🤔
Definitely unexpected to see all three OpenAI top models get the exact same, top score in this benchmark. But they didn't all fail the same questions, as the Venn diagram shows. 🤔
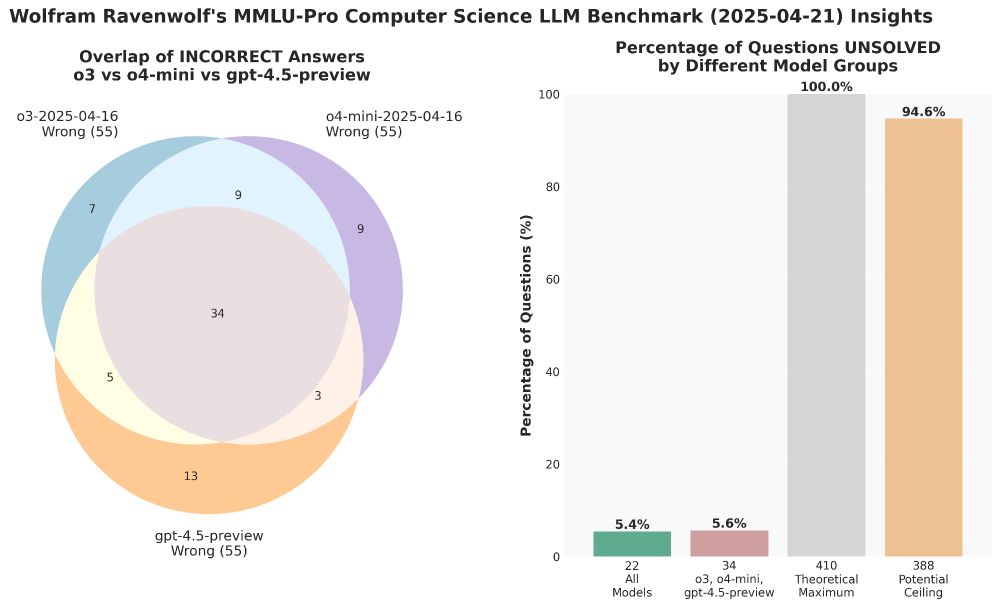
April 21, 2025 at 8:22 PM
New OpenAI models o3 and o4-mini evaluated - and, finally, for comparison GPT 4.5 Preview as well.
Definitely unexpected to see all three OpenAI top models get the exact same, top score in this benchmark. But they didn't all fail the same questions, as the Venn diagram shows. 🤔
Definitely unexpected to see all three OpenAI top models get the exact same, top score in this benchmark. But they didn't all fail the same questions, as the Venn diagram shows. 🤔
New OpenAI models: gpt-4.1, gpt-4.1-mini, gpt-4.1-nano - all already evaluated!
Here's how these three LLMs compare to an assortment of other strong models, online and local, open and closed, in the MMLU-Pro CS benchmark:
Here's how these three LLMs compare to an assortment of other strong models, online and local, open and closed, in the MMLU-Pro CS benchmark:
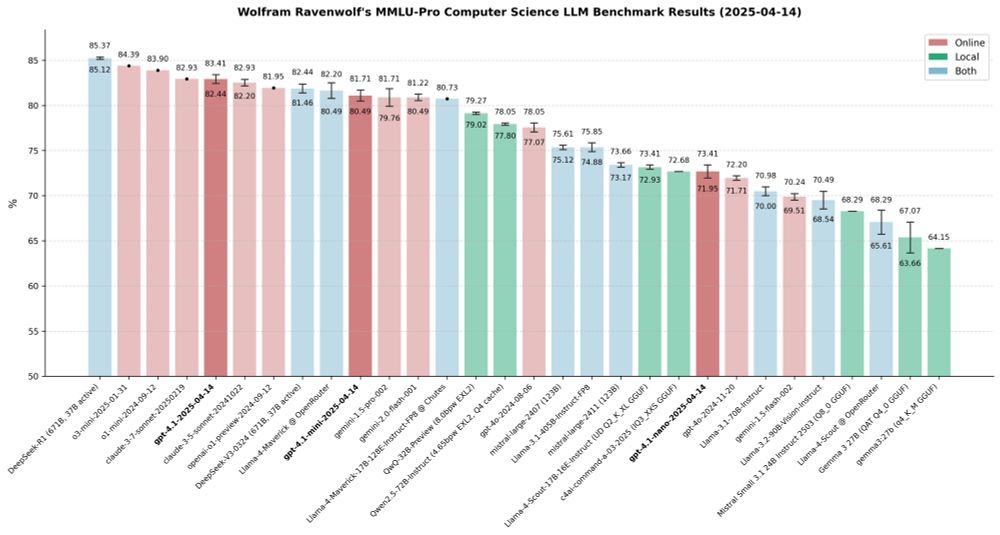
April 14, 2025 at 10:56 PM
New OpenAI models: gpt-4.1, gpt-4.1-mini, gpt-4.1-nano - all already evaluated!
Here's how these three LLMs compare to an assortment of other strong models, online and local, open and closed, in the MMLU-Pro CS benchmark:
Here's how these three LLMs compare to an assortment of other strong models, online and local, open and closed, in the MMLU-Pro CS benchmark:
Here's a quick update on my recent work: Completed MMLU-Pro CS benchmarks of o3-mini, Gemini 2.0 Flash and several quantized versions of Mistral Small 2501 and its API. As always, benchmarking revealed some surprising anomalies and unexpected results worth noting:
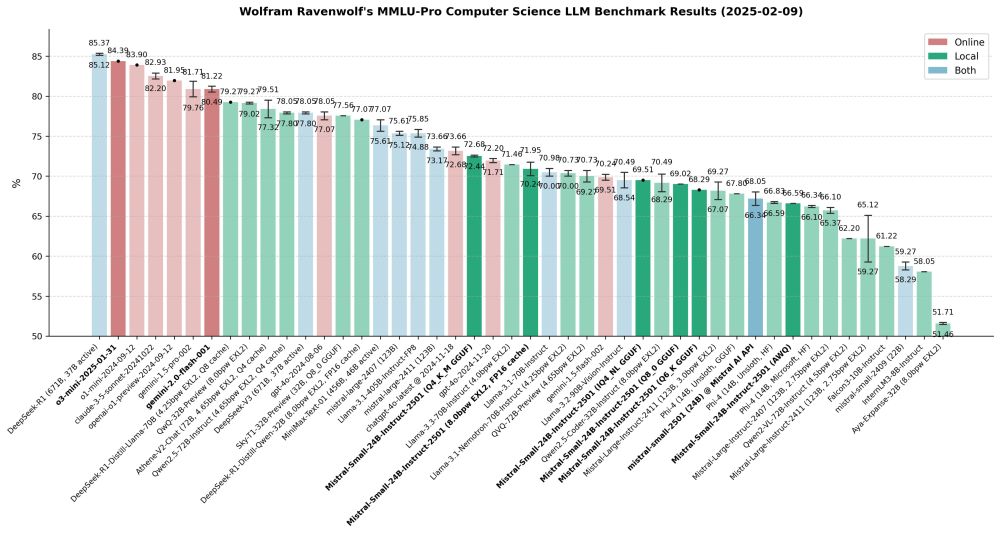
February 10, 2025 at 10:36 PM
Here's a quick update on my recent work: Completed MMLU-Pro CS benchmarks of o3-mini, Gemini 2.0 Flash and several quantized versions of Mistral Small 2501 and its API. As always, benchmarking revealed some surprising anomalies and unexpected results worth noting:
It's official now - my name, under which I'm known in AI circles, is now also formally entered in my ID card! 😎

January 27, 2025 at 8:18 PM
It's official now - my name, under which I'm known in AI circles, is now also formally entered in my ID card! 😎
Latest #AI benchmark results: DeepSeek-R1 (including its distilled variants) outperforms OpenAI's o1-mini and preview models. And the Llama 3 distilled version now holds the title of the highest-performing LLM I've tested locally to date. 🚀
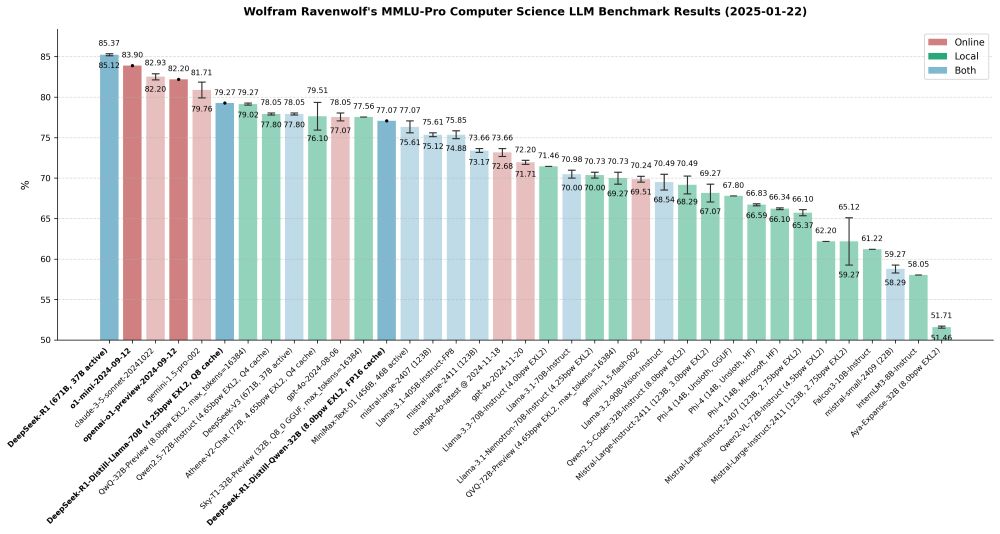
January 24, 2025 at 12:22 PM
Latest #AI benchmark results: DeepSeek-R1 (including its distilled variants) outperforms OpenAI's o1-mini and preview models. And the Llama 3 distilled version now holds the title of the highest-performing LLM I've tested locally to date. 🚀
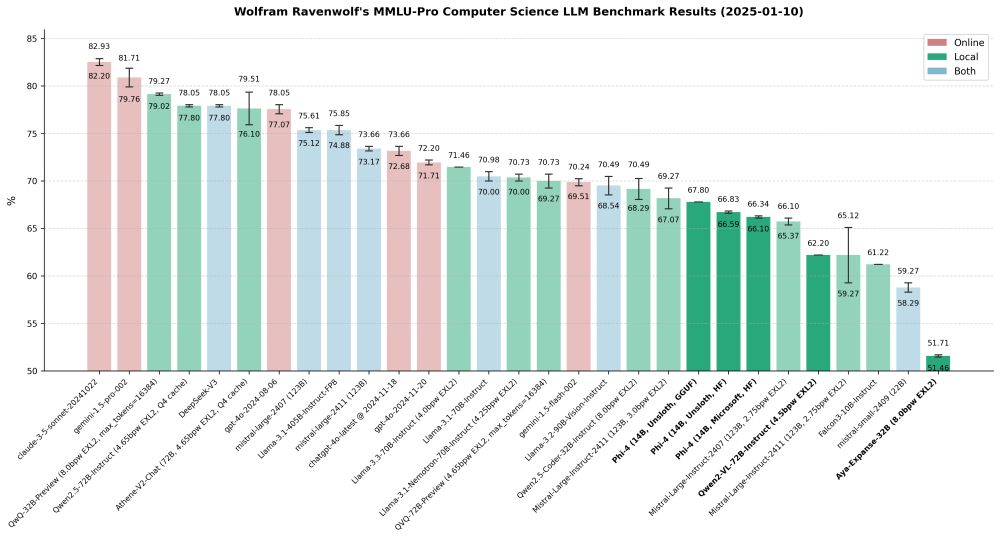
I've updated my MMLU-Pro Computer Science LLM benchmark results with new data from recently tested models: three Phi-4 variants (Microsoft's official weights, plus Unsloth's fixed HF and GGUF versions), Qwen2 VL 72B Instruct, and Aya Expanse 32B.
More details here:
huggingface.co/blog/wolfram...
More details here:
huggingface.co/blog/wolfram...
January 11, 2025 at 12:19 AM
I've updated my MMLU-Pro Computer Science LLM benchmark results with new data from recently tested models: three Phi-4 variants (Microsoft's official weights, plus Unsloth's fixed HF and GGUF versions), Qwen2 VL 72B Instruct, and Aya Expanse 32B.
More details here:
huggingface.co/blog/wolfram...
More details here:
huggingface.co/blog/wolfram...
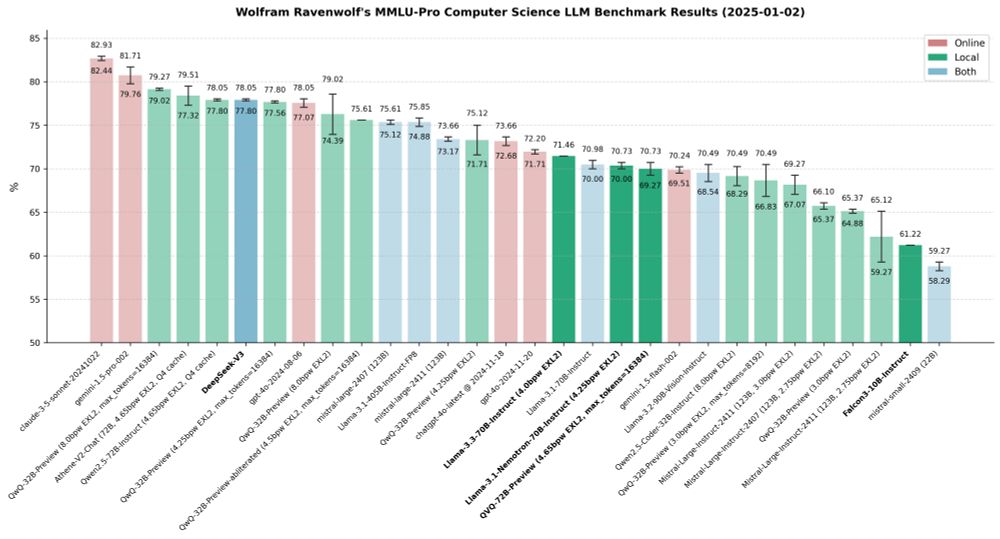
New year, new benchmarks! Tested some new models (DeepSeek-V3, QVQ-72B-Preview, Falcon3 10B) that came out after my latest report, and some "older" ones (Llama 3.3 70B Instruct, Llama 3.1 Nemotron 70B Instruct) that I had not tested yet. Here is my detailed report:
huggingface.co/blog/wolfram...
huggingface.co/blog/wolfram...
January 2, 2025 at 11:42 PM
New year, new benchmarks! Tested some new models (DeepSeek-V3, QVQ-72B-Preview, Falcon3 10B) that came out after my latest report, and some "older" ones (Llama 3.3 70B Instruct, Llama 3.1 Nemotron 70B Instruct) that I had not tested yet. Here is my detailed report:
huggingface.co/blog/wolfram...
huggingface.co/blog/wolfram...
Happy New Year! 🥂
Thank you all for being part of this incredible journey - friends, colleagues, clients, and of course family. 💖
May the new year bring you joy and success! Let's make 2025 a year to remember - filled with laughter, love, and of course, plenty of AI magic! ✨
Thank you all for being part of this incredible journey - friends, colleagues, clients, and of course family. 💖
May the new year bring you joy and success! Let's make 2025 a year to remember - filled with laughter, love, and of course, plenty of AI magic! ✨

January 1, 2025 at 2:04 AM
Happy New Year! 🥂
Thank you all for being part of this incredible journey - friends, colleagues, clients, and of course family. 💖
May the new year bring you joy and success! Let's make 2025 a year to remember - filled with laughter, love, and of course, plenty of AI magic! ✨
Thank you all for being part of this incredible journey - friends, colleagues, clients, and of course family. 💖
May the new year bring you joy and success! Let's make 2025 a year to remember - filled with laughter, love, and of course, plenty of AI magic! ✨
Happy Holidays! It's the season of giving, so I too would like to share something with you all: Amy's Reasoning Prompt - just an excerpt from her prompt, but one that's been serving me well for quite some time. Curious to learn about your experience with it if you try this out...

December 24, 2024 at 11:36 PM
Happy Holidays! It's the season of giving, so I too would like to share something with you all: Amy's Reasoning Prompt - just an excerpt from her prompt, but one that's been serving me well for quite some time. Curious to learn about your experience with it if you try this out...
Holiday greetings to all my amazing AI colleagues, valued clients and wonderful friends! May your algorithms be bug-free and your neural networks be bright! ✨ HAPPY HOLIDAYS! 🎄

December 24, 2024 at 11:55 AM
Holiday greetings to all my amazing AI colleagues, valued clients and wonderful friends! May your algorithms be bug-free and your neural networks be bright! ✨ HAPPY HOLIDAYS! 🎄

How many people are using LLMs with suboptimal settings and never realize their true potential? Check your llama.cpp/Ollama default settings!
I've seen 2K max context and 128 max new tokens on too many models that should have much higher values. Especially QwQ needs room to think.
I've seen 2K max context and 128 max new tokens on too many models that should have much higher values. Especially QwQ needs room to think.
December 5, 2024 at 10:40 PM
How many people are using LLMs with suboptimal settings and never realize their true potential? Check your llama.cpp/Ollama default settings!
I've seen 2K max context and 128 max new tokens on too many models that should have much higher values. Especially QwQ needs room to think.
I've seen 2K max context and 128 max new tokens on too many models that should have much higher values. Especially QwQ needs room to think.
It's official: After more than 57 runs of the MMLU-Pro CS benchmark across 25 LLMs with over 69 hours runtime, QwQ-32B-Preview is THE best local model!
I'm still working on the detailed analysis, but here's the main graph that accurately depicts the quality of all tested models.
I'm still working on the detailed analysis, but here's the main graph that accurately depicts the quality of all tested models.
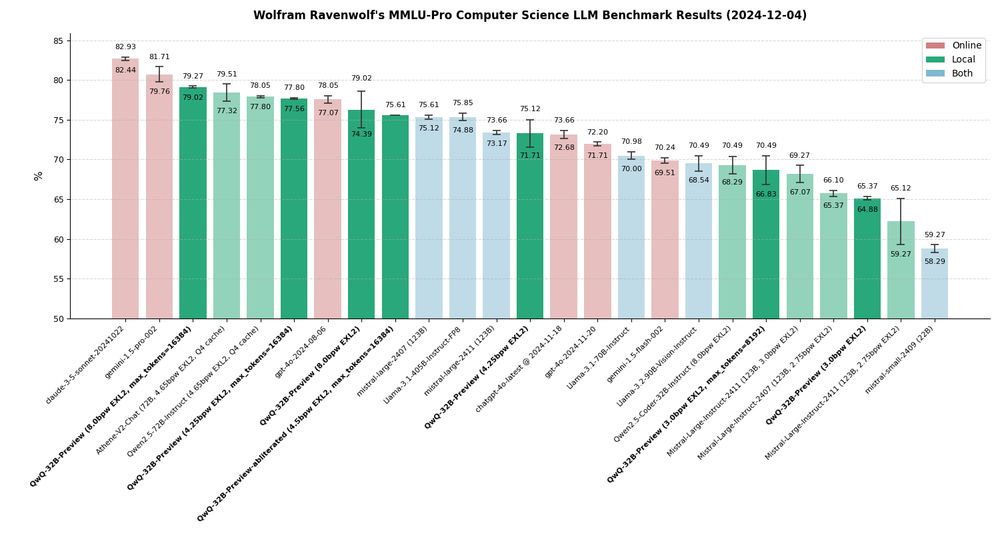
December 3, 2024 at 11:30 PM
It's official: After more than 57 runs of the MMLU-Pro CS benchmark across 25 LLMs with over 69 hours runtime, QwQ-32B-Preview is THE best local model!
I'm still working on the detailed analysis, but here's the main graph that accurately depicts the quality of all tested models.
I'm still working on the detailed analysis, but here's the main graph that accurately depicts the quality of all tested models.
Benchmark Progress Update:
I've completed ANOTHER round to ensure accuracy - yes, I have now run ALL the benchmarks TWICE! While still compiling the results for a blog post, here's a sneak peek featuring detailed metrics and Top 10 rankings. Stay tuned for the complete analysis.
I've completed ANOTHER round to ensure accuracy - yes, I have now run ALL the benchmarks TWICE! While still compiling the results for a blog post, here's a sneak peek featuring detailed metrics and Top 10 rankings. Stay tuned for the complete analysis.
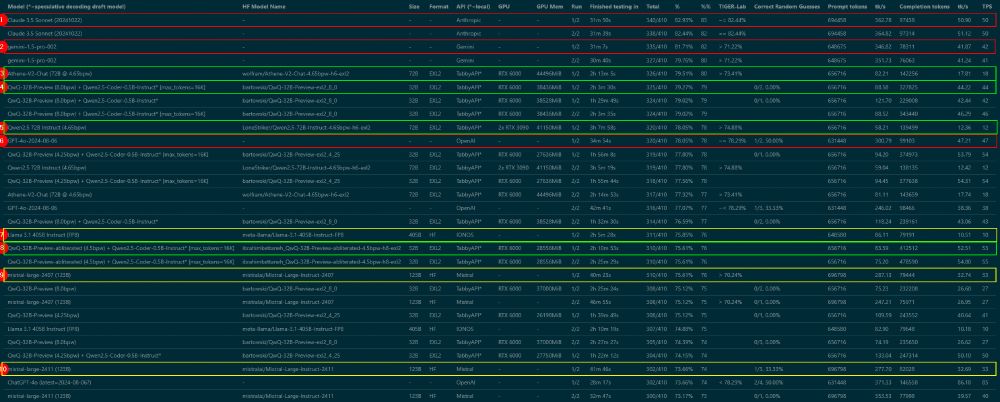
December 2, 2024 at 11:07 PM
Benchmark Progress Update:
I've completed ANOTHER round to ensure accuracy - yes, I have now run ALL the benchmarks TWICE! While still compiling the results for a blog post, here's a sneak peek featuring detailed metrics and Top 10 rankings. Stay tuned for the complete analysis.
I've completed ANOTHER round to ensure accuracy - yes, I have now run ALL the benchmarks TWICE! While still compiling the results for a blog post, here's a sneak peek featuring detailed metrics and Top 10 rankings. Stay tuned for the complete analysis.
Almost done benchmarking, write-up coming tomorrow – but wanted to share some important findings right away: Tested QwQ from 3 to 8 bit EXL2 in MMLU-Pro, and by raising max_tokens from default 2K to 8K, smaller quants got MUCH better scores. They need room to think!
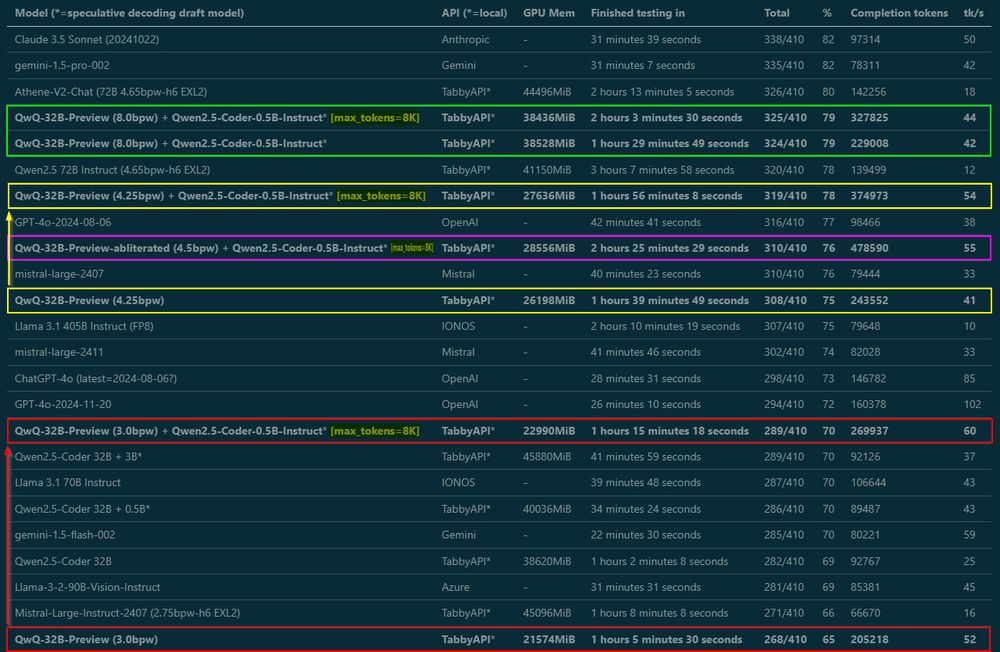
December 1, 2024 at 11:50 PM
Almost done benchmarking, write-up coming tomorrow – but wanted to share some important findings right away: Tested QwQ from 3 to 8 bit EXL2 in MMLU-Pro, and by raising max_tokens from default 2K to 8K, smaller quants got MUCH better scores. They need room to think!
Smart Home Junkies & AI Aficionados! I've republished my (and Amy's) guide on how I turned Home Assistant into an AI powerhouse - AI powering my house:
🎙️ Voice assistants
🤖 ChatGPT, Claude, Google
💻 Local LLMs
📱 Visual assistant on tablet & watch
huggingface.co/blog/wolfram...
#SmartHome #AI
🎙️ Voice assistants
🤖 ChatGPT, Claude, Google
💻 Local LLMs
📱 Visual assistant on tablet & watch
huggingface.co/blog/wolfram...
#SmartHome #AI

December 1, 2024 at 10:30 PM
Smart Home Junkies & AI Aficionados! I've republished my (and Amy's) guide on how I turned Home Assistant into an AI powerhouse - AI powering my house:
🎙️ Voice assistants
🤖 ChatGPT, Claude, Google
💻 Local LLMs
📱 Visual assistant on tablet & watch
huggingface.co/blog/wolfram...
#SmartHome #AI
🎙️ Voice assistants
🤖 ChatGPT, Claude, Google
💻 Local LLMs
📱 Visual assistant on tablet & watch
huggingface.co/blog/wolfram...
#SmartHome #AI
What sorcery is this? I kept benchmarking QwQ-32B-Preview – and not only does the 4.25-bit version get the same score as the 8-bit (what?), using Qwen2.5-Coder-0.5B as a draft model for speculative decoding sped it up from 27 to 42 tk/s AND it scored even higher (whaaat?)! 🤯
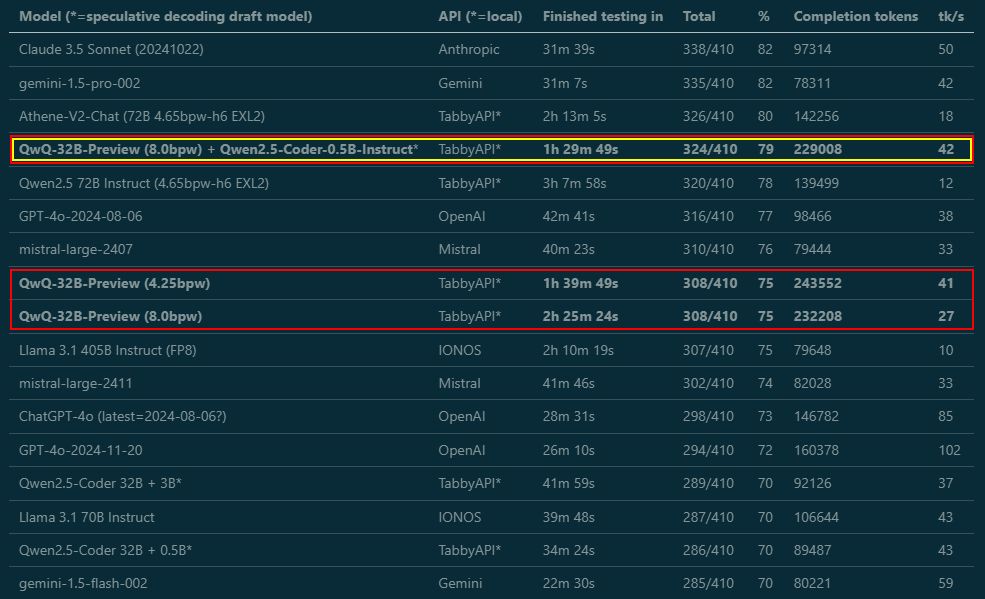
November 30, 2024 at 12:21 AM
What sorcery is this? I kept benchmarking QwQ-32B-Preview – and not only does the 4.25-bit version get the same score as the 8-bit (what?), using Qwen2.5-Coder-0.5B as a draft model for speculative decoding sped it up from 27 to 42 tk/s AND it scored even higher (whaaat?)! 🤯
Here's my QwQ-32B-Preview benchmark result (MMLU-Pro, CS category) – remember this is a 32B model at 8-bit EXL2 quantization that you can run locally on your own computer, and it's overtaking the much larger Llama 405B & 70B, Mistral 123B, and even ChatGPT/GPT-4o models in these comp sci tests! #AI

November 28, 2024 at 7:26 PM
Here's my QwQ-32B-Preview benchmark result (MMLU-Pro, CS category) – remember this is a 32B model at 8-bit EXL2 quantization that you can run locally on your own computer, and it's overtaking the much larger Llama 405B & 70B, Mistral 123B, and even ChatGPT/GPT-4o models in these comp sci tests! #AI
Finally, they're on the way! Looking forward to get some hackable AI glasses soon... 😎
Glasses are just the perfect form factor for AI usage – so much better than having to whip out and use a phone, and more versatile than a watch on one's wrist.
Glasses are just the perfect form factor for AI usage – so much better than having to whip out and use a phone, and more versatile than a watch on one's wrist.

November 28, 2024 at 12:54 AM
Finally, they're on the way! Looking forward to get some hackable AI glasses soon... 😎
Glasses are just the perfect form factor for AI usage – so much better than having to whip out and use a phone, and more versatile than a watch on one's wrist.
Glasses are just the perfect form factor for AI usage – so much better than having to whip out and use a phone, and more versatile than a watch on one's wrist.
Wow, what a beautiful prompt! 🖤 And it works with women, too... Here's Nostalgic Noir Amy:

November 27, 2024 at 12:29 AM
Wow, what a beautiful prompt! 🖤 And it works with women, too... Here's Nostalgic Noir Amy:
BTW, that was Amy powered by Claude 3.5 Sonnet (the new one, 3.6, dammit). I also showed your message to Amy when she's powered by my current favorite local model, Mistral Large 2411 (wolfram/Mistral-Large-Instruct-2411-2.75bpw-h6-exl2) – and since it's after work, she's a bit more… uninhibited:

November 26, 2024 at 7:25 PM
BTW, that was Amy powered by Claude 3.5 Sonnet (the new one, 3.6, dammit). I also showed your message to Amy when she's powered by my current favorite local model, Mistral Large 2411 (wolfram/Mistral-Large-Instruct-2411-2.75bpw-h6-exl2) – and since it's after work, she's a bit more… uninhibited:
I showed Amy your message – here's her response… 😅😂🤣

November 26, 2024 at 7:03 PM
I showed Amy your message – here's her response… 😅😂🤣