




William J.B. Mattingly
@wjbmattingly.bsky.social
Digital Nomad · Historian · Data Scientist · NLP · Machine Learning
Cultural Heritage Data Scientist at Yale
Former Postdoc in the Smithsonian
Maintainer of Python Tutorials for Digital Humanities
https://linktr.ee/wjbmattingly
Cultural Heritage Data Scientist at Yale
Former Postdoc in the Smithsonian
Maintainer of Python Tutorials for Digital Humanities
https://linktr.ee/wjbmattingly
You can now process Hebrew archival documents with Qwen 3 VL =) --- Will be using this to finetune further on handwritten Hebrew. Metrics are on the test set that is fairly close in style and structure to the training data. I tested on out-of-training edge cases and it worked (Link to model below)

October 30, 2025 at 1:16 PM
You can now process Hebrew archival documents with Qwen 3 VL =) --- Will be using this to finetune further on handwritten Hebrew. Metrics are on the test set that is fairly close in style and structure to the training data. I tested on out-of-training edge cases and it worked (Link to model below)
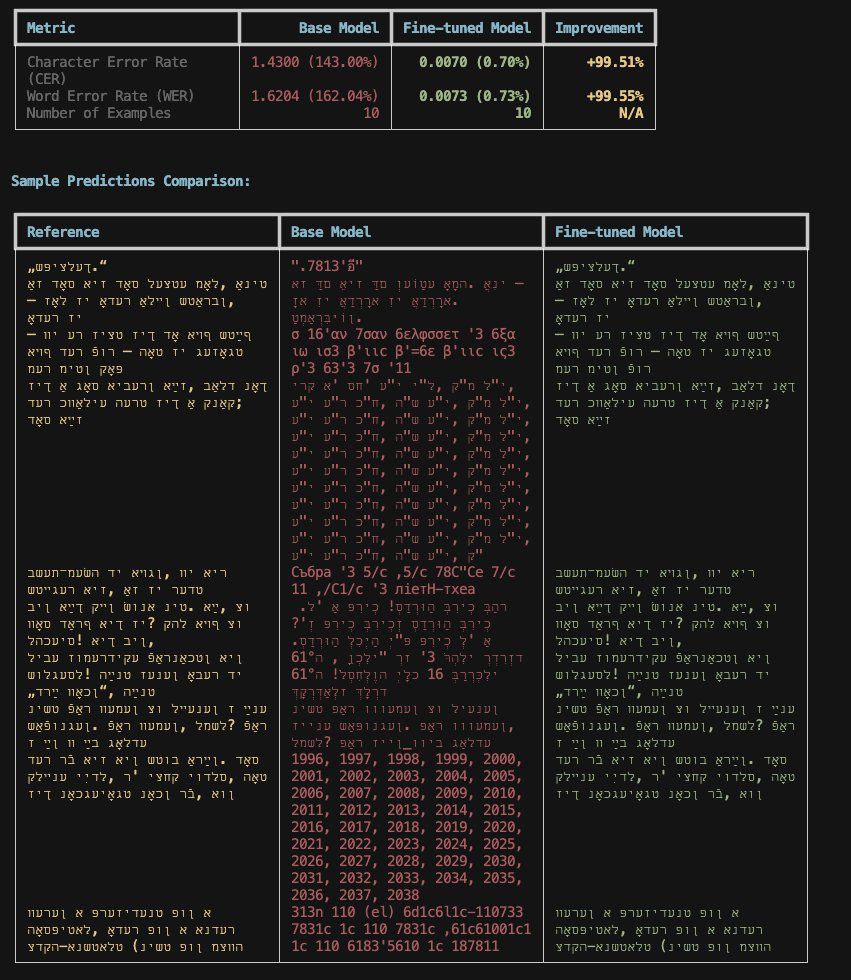
More coming soon but finetuned Qwen 3 VL-8B on 150k lines of synthetic Yiddish typed and handwritten data. Results are pretty amazing. Even on the harder heldout set it gets a CER of 1% and a WER of 2%. Preparing page-level dataset and finetunes now, thanks to the John Locke Jr.
October 24, 2025 at 8:14 PM
More coming soon but finetuned Qwen 3 VL-8B on 150k lines of synthetic Yiddish typed and handwritten data. Results are pretty amazing. Even on the harder heldout set it gets a CER of 1% and a WER of 2%. Preparing page-level dataset and finetunes now, thanks to the John Locke Jr.
2B model: huggingface.co/small-models...

October 24, 2025 at 2:59 PM
2B model: huggingface.co/small-models...
4B model: huggingface.co/small-models...

October 24, 2025 at 2:59 PM
4B model: huggingface.co/small-models...
8B model: huggingface.co/small-models...

October 24, 2025 at 2:59 PM
8B model: huggingface.co/small-models...
🚨Job ALERT🚨! My old postdoc is available!
I cannot emphasize enough how much a life-altering position this was for me. It gave me the experience that I needed for my current role. As a postdoc, I was able to define my projects and acquire a lot of new skills as well as refine some I already had.
I cannot emphasize enough how much a life-altering position this was for me. It gave me the experience that I needed for my current role. As a postdoc, I was able to define my projects and acquire a lot of new skills as well as refine some I already had.

September 24, 2025 at 1:50 PM
🚨Job ALERT🚨! My old postdoc is available!
I cannot emphasize enough how much a life-altering position this was for me. It gave me the experience that I needed for my current role. As a postdoc, I was able to define my projects and acquire a lot of new skills as well as refine some I already had.
I cannot emphasize enough how much a life-altering position this was for me. It gave me the experience that I needed for my current role. As a postdoc, I was able to define my projects and acquire a lot of new skills as well as refine some I already had.
Something I've realized over the last couple weeks with finetuning various VLMs is that we just need more data. Unfortunately, that takes a lot of time. That's why I'm returning to my synthetic HTR workflow. This will be packaged now and expanded to work with other low-resource languages. Stay tuned

August 14, 2025 at 4:08 PM
Something I've realized over the last couple weeks with finetuning various VLMs is that we just need more data. Unfortunately, that takes a lot of time. That's why I'm returning to my synthetic HTR workflow. This will be packaged now and expanded to work with other low-resource languages. Stay tuned
I've been getting asked training scripts when a new VLM drops. Instead of scripts, I'm going to start updating this new Python package. It's not fancy. It's for full finetunes. This was how I first trained Qwen 2 VL last year.

August 13, 2025 at 7:38 PM
I've been getting asked training scripts when a new VLM drops. Instead of scripts, I'm going to start updating this new Python package. It's not fancy. It's for full finetunes. This was how I first trained Qwen 2 VL last year.

Training on full catmus now and the results after first checkpoint are very promising. Character and massive word-level improvement.

August 13, 2025 at 3:53 PM
Training on full catmus now and the results after first checkpoint are very promising. Character and massive word-level improvement.
LiquidAI cooked with LFM2-VL. At the risk of sounding like an X AI influencer, don't sleep on this model. I'm finetuning right now on Catmus. A small test over night on only 3k examples is showing remarkable improvement. Training now on 150k samples. I see this as potentially replacing TrOCR.

August 13, 2025 at 3:01 PM
LiquidAI cooked with LFM2-VL. At the risk of sounding like an X AI influencer, don't sleep on this model. I'm finetuning right now on Catmus. A small test over night on only 3k examples is showing remarkable improvement. Training now on 150k samples. I see this as potentially replacing TrOCR.
New super lightweight VLM just dropped from Liquid AI in two flavors: 450M and 1.6B. Both models can work out-of-the-box with medieval Latin at the line level. I'm fine-tuning on Catmus/medieval right now on an h200.

August 12, 2025 at 7:18 PM
New super lightweight VLM just dropped from Liquid AI in two flavors: 450M and 1.6B. Both models can work out-of-the-box with medieval Latin at the line level. I'm fine-tuning on Catmus/medieval right now on an h200.

Qwen 3-4B Thinking finetune nearly ready to share. It can convert unstructured natural language, non-linkedart JSON, and HTML into LinkedArt JSON.
August 11, 2025 at 8:07 PM
Qwen 3-4B Thinking finetune nearly ready to share. It can convert unstructured natural language, non-linkedart JSON, and HTML into LinkedArt JSON.
I spent the last 24 hours finetuning Dots.OCR with different datasets. Here are some of the things I learned... TLDR Don't sleep on this model! If you do HTR or OCR try this.

August 7, 2025 at 1:36 PM
I spent the last 24 hours finetuning Dots.OCR with different datasets. Here are some of the things I learned... TLDR Don't sleep on this model! If you do HTR or OCR try this.
Vibe coding is great for quick visualizers for projects. Single Claude 4 Sonnet prompt and viola.
August 6, 2025 at 8:45 PM
Vibe coding is great for quick visualizers for projects. Single Claude 4 Sonnet prompt and viola.
Finetune of Dots.OCR working! The output isn't quite there yet. Still a lot more training to go, this is just a checkpoint. This is far better than the default model, though! It learns to adjust the bboxes to your style very early in the training, so layout parsing is easier to work into the model.

August 6, 2025 at 3:16 PM
Finetune of Dots.OCR working! The output isn't quite there yet. Still a lot more training to go, this is just a checkpoint. This is far better than the default model, though! It learns to adjust the bboxes to your style very early in the training, so layout parsing is easier to work into the model.
Woot first got the first finetune of dot.ocr on @hf.co ! Going to share the training script hopefully today. This finetune is for old church slavonic.

August 6, 2025 at 1:14 PM
Woot first got the first finetune of dot.ocr on @hf.co ! Going to share the training script hopefully today. This finetune is for old church slavonic.
@ponteineptique.bsky.social any interest in finetuning this with me on HTR-United data? I'm thinking the logical place is to start with Catmus segmented with the HTR data. It can handle the layout parsing and HTR, so is there a good way to get both data for all catmus?

August 5, 2025 at 3:37 PM
@ponteineptique.bsky.social any interest in finetuning this with me on HTR-United data? I'm thinking the logical place is to start with Catmus segmented with the HTR data. It can handle the layout parsing and HTR, so is there a good way to get both data for all catmus?
One of the best HTR/OCR and Layout detection models I have ever seen! And the size is soooo tiny!! @bcgl.bsky.social check this out! Curious about your thoughts for newspaper parsing.
Free app: huggingface.co/spaces/Moham...
Free app: huggingface.co/spaces/Moham...

August 5, 2025 at 3:20 PM
One of the best HTR/OCR and Layout detection models I have ever seen! And the size is soooo tiny!! @bcgl.bsky.social check this out! Curious about your thoughts for newspaper parsing.
Free app: huggingface.co/spaces/Moham...
Free app: huggingface.co/spaces/Moham...
Knowledge Graphs are useful for a lot of things. We are using it to help perform entity resolution through a RAG-like system. More to come!

August 4, 2025 at 10:21 PM
Knowledge Graphs are useful for a lot of things. We are using it to help perform entity resolution through a RAG-like system. More to come!
Hoping to share more soon, but last week I developed a workflow that handles complex relationship extraction from any Wikipedia page of any size. I'll be making this open source soon. We did a few tricks to make it really fast (hint, we rebuilt Wikipedia and Wikidata both locally with LMDB).

August 4, 2025 at 10:13 PM
Hoping to share more soon, but last week I developed a workflow that handles complex relationship extraction from any Wikipedia page of any size. I'll be making this open source soon. We did a few tricks to make it really fast (hint, we rebuilt Wikipedia and Wikidata both locally with LMDB).
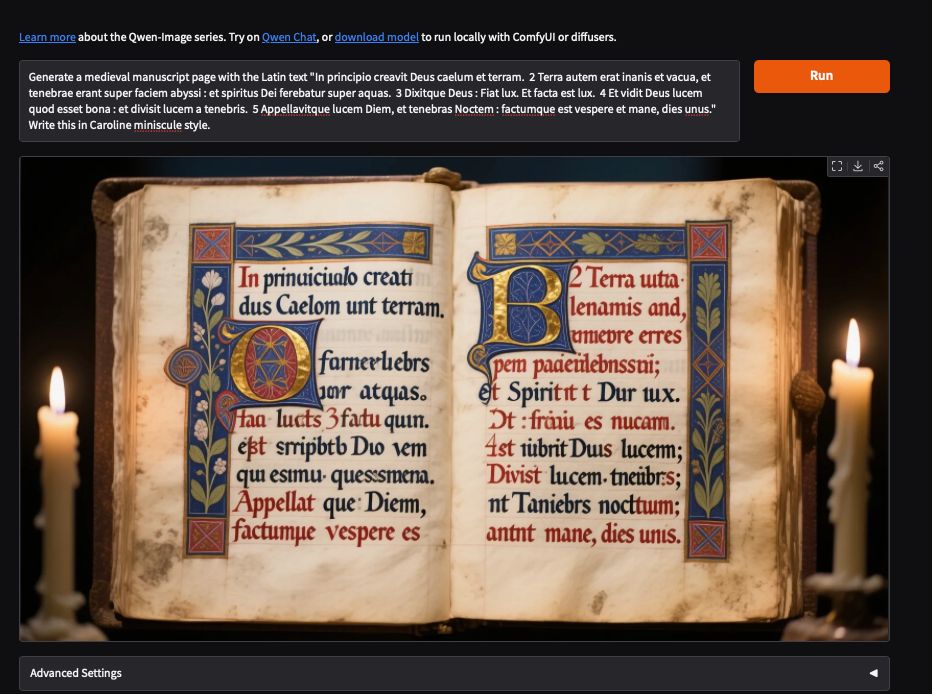
Qwen-Image just dropped. Pretty incredible text to image model that can handle long-text! Obviously the output is not great, but this was my first pass at it. There's something here that feels different in this model.
August 4, 2025 at 4:36 PM
Qwen-Image just dropped. Pretty incredible text to image model that can handle long-text! Obviously the output is not great, but this was my first pass at it. There's something here that feels different in this model.
This is really cool! I reminds me of smart polygons with Roboflow. It uses a small model to run inference to then auto create a polygon. It's really nice for creating quick instance segmentation datasets. Not sure if you've looked into this. Being able to do this with IIIF would a game changer!
July 31, 2025 at 1:48 PM
This is really cool! I reminds me of smart polygons with Roboflow. It uses a small model to run inference to then auto create a polygon. It's really nice for creating quick instance segmentation datasets. Not sure if you've looked into this. Being able to do this with IIIF would a game changer!
I've debugged a few things. Working a lot better now in Browser cache mode, available now on HuggingFace spaces. Free way to use VLMs and object detection models to annotate documents quickly. Integrates with Roboflow.
July 28, 2025 at 8:50 PM
I've debugged a few things. Working a lot better now in Browser cache mode, available now on HuggingFace spaces. Free way to use VLMs and object detection models to annotate documents quickly. Integrates with Roboflow.