




Thomas Wimmer
@wimmerthomas.bsky.social
PhD Candidate at the Max Planck ETH Center for Learning Systems working on 3D Computer Vision.
https://wimmerth.github.io
https://wimmerth.github.io
Generalization: AnyUp is the first learned upsampler that can be applied out-of-the-box to other features of potentially different dimensionality.
In our experiments, we show that it matches encoder-specific upsamplers and that trends between different model sizes are preserved.
In our experiments, we show that it matches encoder-specific upsamplers and that trends between different model sizes are preserved.

October 16, 2025 at 9:07 AM
Generalization: AnyUp is the first learned upsampler that can be applied out-of-the-box to other features of potentially different dimensionality.
In our experiments, we show that it matches encoder-specific upsamplers and that trends between different model sizes are preserved.
In our experiments, we show that it matches encoder-specific upsamplers and that trends between different model sizes are preserved.
When performing linear probing for semantic segmentation or normal and depth estimation, AnyUp consistently outperforms prior upsamplers.
Importantly, the upsampled features also stay faithful to the input feature space, as we show in experiments with pre-trained DINOv2 probes.
Importantly, the upsampled features also stay faithful to the input feature space, as we show in experiments with pre-trained DINOv2 probes.

October 16, 2025 at 9:07 AM
When performing linear probing for semantic segmentation or normal and depth estimation, AnyUp consistently outperforms prior upsamplers.
Importantly, the upsampled features also stay faithful to the input feature space, as we show in experiments with pre-trained DINOv2 probes.
Importantly, the upsampled features also stay faithful to the input feature space, as we show in experiments with pre-trained DINOv2 probes.
AnyUp is a lightweight model that uses a feature-agnostic layer to obtain a canonical representation that is independent of the input dimensionality.
Together with window attention-based upsampling, a new training pipeline and consistency regularization, we achieve SOTA results.
Together with window attention-based upsampling, a new training pipeline and consistency regularization, we achieve SOTA results.

October 16, 2025 at 9:07 AM
AnyUp is a lightweight model that uses a feature-agnostic layer to obtain a canonical representation that is independent of the input dimensionality.
Together with window attention-based upsampling, a new training pipeline and consistency regularization, we achieve SOTA results.
Together with window attention-based upsampling, a new training pipeline and consistency regularization, we achieve SOTA results.
Super excited to introduce
✨ AnyUp: Universal Feature Upsampling 🔎
Upsample any feature - really any feature - with the same upsampler, no need for cumbersome retraining.
SOTA feature upsampling results while being feature-agnostic at inference time.
🌐 wimmerth.github.io/anyup/
✨ AnyUp: Universal Feature Upsampling 🔎
Upsample any feature - really any feature - with the same upsampler, no need for cumbersome retraining.
SOTA feature upsampling results while being feature-agnostic at inference time.
🌐 wimmerth.github.io/anyup/
October 16, 2025 at 9:07 AM
Super excited to introduce
✨ AnyUp: Universal Feature Upsampling 🔎
Upsample any feature - really any feature - with the same upsampler, no need for cumbersome retraining.
SOTA feature upsampling results while being feature-agnostic at inference time.
🌐 wimmerth.github.io/anyup/
✨ AnyUp: Universal Feature Upsampling 🔎
Upsample any feature - really any feature - with the same upsampler, no need for cumbersome retraining.
SOTA feature upsampling results while being feature-agnostic at inference time.
🌐 wimmerth.github.io/anyup/
While we can now transfer motion into 3D, we still have to deal with a fundamental problem: Lacking 3D consistency of generated videos.
With limited resources, we can't fine-tune or retrain a VDM to be pose-conditioned. Thus, we propose a zero-shot technique to generate more 3D-consistent videos!
🧵⬇️
With limited resources, we can't fine-tune or retrain a VDM to be pose-conditioned. Thus, we propose a zero-shot technique to generate more 3D-consistent videos!
🧵⬇️

March 28, 2025 at 8:35 AM
While we can now transfer motion into 3D, we still have to deal with a fundamental problem: Lacking 3D consistency of generated videos.
With limited resources, we can't fine-tune or retrain a VDM to be pose-conditioned. Thus, we propose a zero-shot technique to generate more 3D-consistent videos!
🧵⬇️
With limited resources, we can't fine-tune or retrain a VDM to be pose-conditioned. Thus, we propose a zero-shot technique to generate more 3D-consistent videos!
🧵⬇️
Standard practices like SDS fail for this task as VDMs provide a guidance signal that is too noisy, resulting in "exploding" scenes.
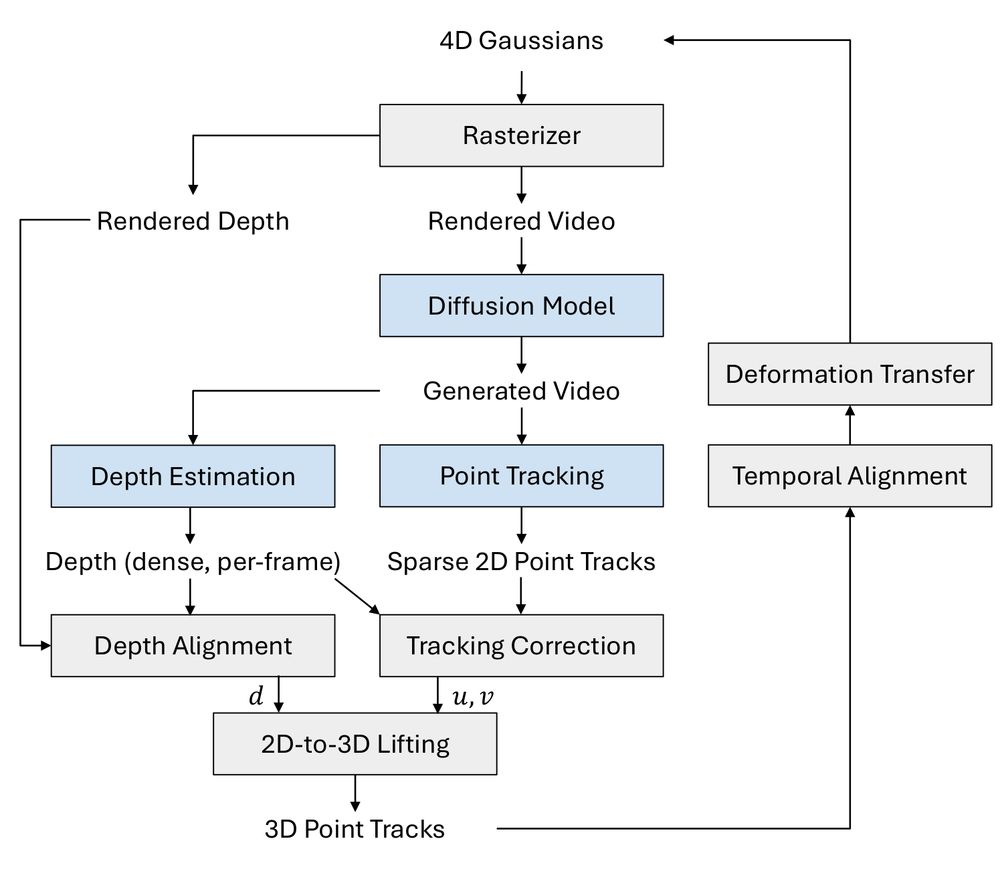
Instead, we propose to employ several pre-trained 2D models to directly lift motion from tracked points in the generated videos to 3D Gaussians.
🧵⬇️
Instead, we propose to employ several pre-trained 2D models to directly lift motion from tracked points in the generated videos to 3D Gaussians.
🧵⬇️
March 28, 2025 at 8:35 AM
Standard practices like SDS fail for this task as VDMs provide a guidance signal that is too noisy, resulting in "exploding" scenes.
Instead, we propose to employ several pre-trained 2D models to directly lift motion from tracked points in the generated videos to 3D Gaussians.
🧵⬇️
Instead, we propose to employ several pre-trained 2D models to directly lift motion from tracked points in the generated videos to 3D Gaussians.
🧵⬇️
Had the honor to present "Gaussians-to-Life" at #3DV2025 yesterday. In this work, we used video diffusion models to animate arbitrary 3D Gaussian Splatting scenes.
This work was a great collaboration with @moechsle.bsky.social, @miniemeyer.bsky.social, and Federico Tombari.
🧵⬇️
This work was a great collaboration with @moechsle.bsky.social, @miniemeyer.bsky.social, and Federico Tombari.
🧵⬇️

March 28, 2025 at 8:35 AM
Had the honor to present "Gaussians-to-Life" at #3DV2025 yesterday. In this work, we used video diffusion models to animate arbitrary 3D Gaussian Splatting scenes.
This work was a great collaboration with @moechsle.bsky.social, @miniemeyer.bsky.social, and Federico Tombari.
🧵⬇️
This work was a great collaboration with @moechsle.bsky.social, @miniemeyer.bsky.social, and Federico Tombari.
🧵⬇️
Well well, it turns out that GIFs aren't yet supported on this platform. Here is the teaser video as an MP4 instead:
January 15, 2025 at 5:27 PM
Well well, it turns out that GIFs aren't yet supported on this platform. Here is the teaser video as an MP4 instead:
Quantitative evaluation of diffusion model outputs is hard!
We realized that we are often lacking metrics for comparing the quality of video and multi-view diffusion models. Especially the quantification of multi-view 3D consistency across frames is difficult.
But not anymore: Introducing MET3R 🧵
We realized that we are often lacking metrics for comparing the quality of video and multi-view diffusion models. Especially the quantification of multi-view 3D consistency across frames is difficult.
But not anymore: Introducing MET3R 🧵
January 15, 2025 at 5:21 PM
Quantitative evaluation of diffusion model outputs is hard!
We realized that we are often lacking metrics for comparing the quality of video and multi-view diffusion models. Especially the quantification of multi-view 3D consistency across frames is difficult.
But not anymore: Introducing MET3R 🧵
We realized that we are often lacking metrics for comparing the quality of video and multi-view diffusion models. Especially the quantification of multi-view 3D consistency across frames is difficult.
But not anymore: Introducing MET3R 🧵