



William Jurayj
@williamjurayj.bsky.social
PhD student at Johns Hopkins CLSP (@jhuclsp.bsky.social).
Researching natural and formal language processing.
williamjurayj.com
Researching natural and formal language processing.
williamjurayj.com
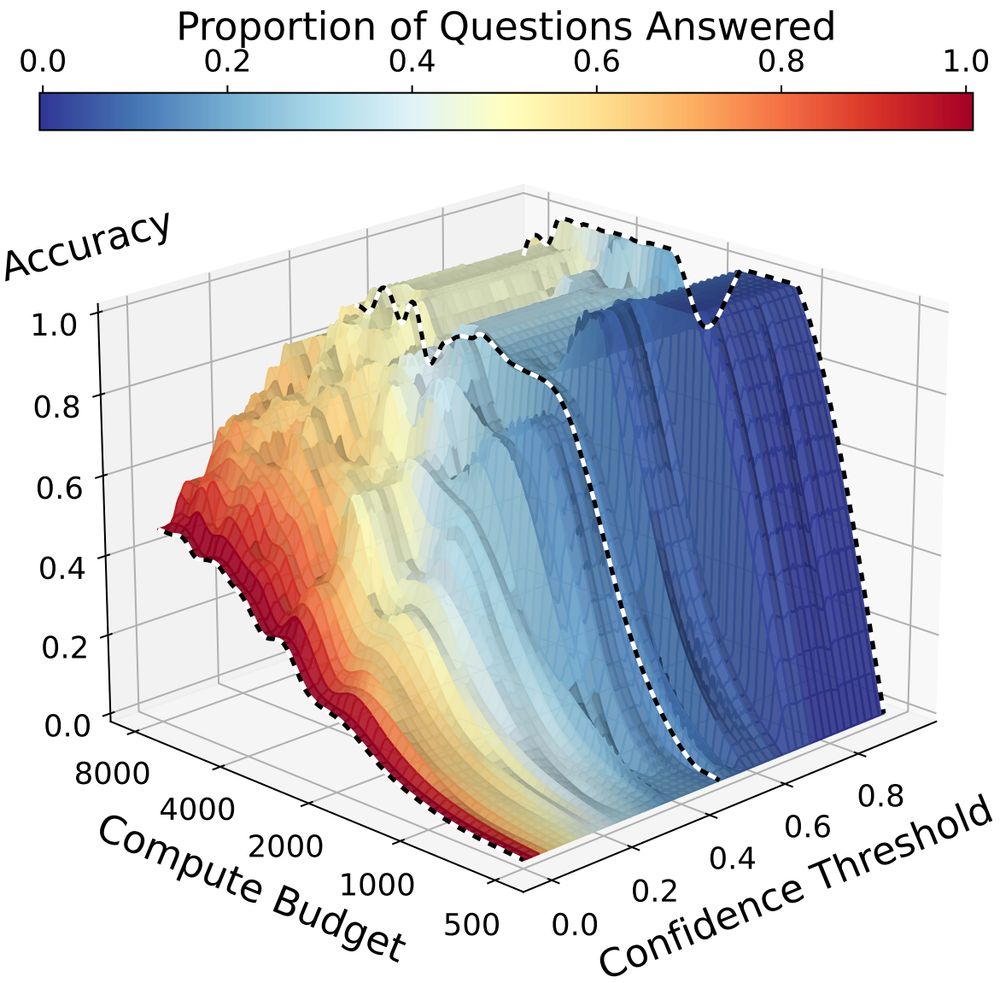
We propose the standard evaluation format of “Jeopardy odds”: win a point when you’re right, lose a point when you’re wrong. Here we see compute scaling distinctions that were hidden when evaluating under a zero-risk setting. Selection functions matter!

February 20, 2025 at 3:14 PM
We propose the standard evaluation format of “Jeopardy odds”: win a point when you’re right, lose a point when you’re wrong. Here we see compute scaling distinctions that were hidden when evaluating under a zero-risk setting. Selection functions matter!
We test DeepSeek-R1 and find that scaling test-time compute can substantially increase a model’s confidence in correct answers, drawing a wider gap between correct and incorrect answers.

February 20, 2025 at 3:14 PM
We test DeepSeek-R1 and find that scaling test-time compute can substantially increase a model’s confidence in correct answers, drawing a wider gap between correct and incorrect answers.
🚨 You are only evaluating a slice of your test-time scaling model's performance! 🚨
📈 We consider how models’ confidence in their answers changes as test-time compute increases. Reasoning longer helps models answer more confidently!
📝: arxiv.org/abs/2502.13962
📈 We consider how models’ confidence in their answers changes as test-time compute increases. Reasoning longer helps models answer more confidently!
📝: arxiv.org/abs/2502.13962
February 20, 2025 at 3:14 PM
🚨 You are only evaluating a slice of your test-time scaling model's performance! 🚨
📈 We consider how models’ confidence in their answers changes as test-time compute increases. Reasoning longer helps models answer more confidently!
📝: arxiv.org/abs/2502.13962
📈 We consider how models’ confidence in their answers changes as test-time compute increases. Reasoning longer helps models answer more confidently!
📝: arxiv.org/abs/2502.13962