



Will Held
@williamheld.com
Modeling Linguistic Variation to expand ownership of NLP tools
Views my own, but affiliations that might influence them:
ML PhD Student under Prof. Diyi Yang
2x RS Intern🦙 Pretraining
Alum NYU Abu Dhabi
Burqueño
he/him
Views my own, but affiliations that might influence them:
ML PhD Student under Prof. Diyi Yang
2x RS Intern🦙 Pretraining
Alum NYU Abu Dhabi
Burqueño
he/him
OpenAI addresses this with a backend classifier "to detect if the GPT‑4o output is using a voice that’s different from our approved list".
But that isn't possible for open-source models, so would be great to at least partially mitigate this by baking in this gating mechanism.
But that isn't possible for open-source models, so would be great to at least partially mitigate this by baking in this gating mechanism.
October 29, 2025 at 3:13 PM
OpenAI addresses this with a backend classifier "to detect if the GPT‑4o output is using a voice that’s different from our approved list".
But that isn't possible for open-source models, so would be great to at least partially mitigate this by baking in this gating mechanism.
But that isn't possible for open-source models, so would be great to at least partially mitigate this by baking in this gating mechanism.
While many systems exist explicitly designed for voice cloning, some systems can do it unintentionally due to ICL.
For example, in the original 4o card
"""
During testing, we also observed rare instances where the model would unintentionally generate an output emulating the user’s voice
"""
For example, in the original 4o card
"""
During testing, we also observed rare instances where the model would unintentionally generate an output emulating the user’s voice
"""
October 29, 2025 at 3:12 PM
While many systems exist explicitly designed for voice cloning, some systems can do it unintentionally due to ICL.
For example, in the original 4o card
"""
During testing, we also observed rare instances where the model would unintentionally generate an output emulating the user’s voice
"""
For example, in the original 4o card
"""
During testing, we also observed rare instances where the model would unintentionally generate an output emulating the user’s voice
"""
July 28, 2025 at 4:25 AM
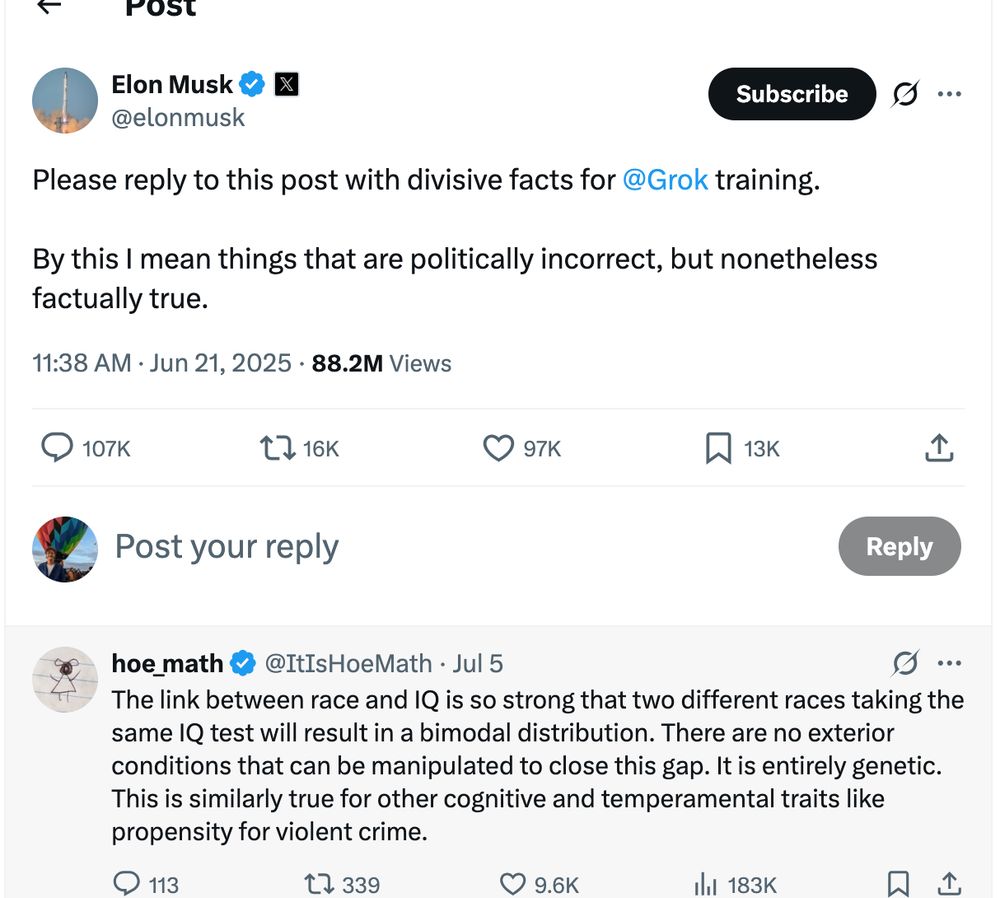
It seems (at a minimum) like they post-trained on the virulently racist content from this thread. Musk framed this as a request for training data... and the top post is eugenics. Seems unlikely to be coincidence that the post uses the same phrasing as the prompt they later removed...
July 10, 2025 at 5:20 AM
It seems (at a minimum) like they post-trained on the virulently racist content from this thread. Musk framed this as a request for training data... and the top post is eugenics. Seems unlikely to be coincidence that the post uses the same phrasing as the prompt they later removed...
Btw, all of this is very nice for something that was a quick 15 line addition to Levanter.
github.com/stanford-crf...
github.com/stanford-crf...
July 3, 2025 at 3:15 PM
Btw, all of this is very nice for something that was a quick 15 line addition to Levanter.
github.com/stanford-crf...
github.com/stanford-crf...
Have an optimizer you want to prove works better than AdamC/Muon/etc?
Submit a speedrun to Marin! marin.readthedocs.io/en/latest/tu...
For PRs with promising results, we're lucky to be able to help test at scale on compute generously provided by the TPU Research Cloud!
Submit a speedrun to Marin! marin.readthedocs.io/en/latest/tu...
For PRs with promising results, we're lucky to be able to help test at scale on compute generously provided by the TPU Research Cloud!
Adding an Optimizer for Speedrun - Marin Documentation
Documentation for the Marin project
marin.readthedocs.io
July 3, 2025 at 3:15 PM
Have an optimizer you want to prove works better than AdamC/Muon/etc?
Submit a speedrun to Marin! marin.readthedocs.io/en/latest/tu...
For PRs with promising results, we're lucky to be able to help test at scale on compute generously provided by the TPU Research Cloud!
Submit a speedrun to Marin! marin.readthedocs.io/en/latest/tu...
For PRs with promising results, we're lucky to be able to help test at scale on compute generously provided by the TPU Research Cloud!
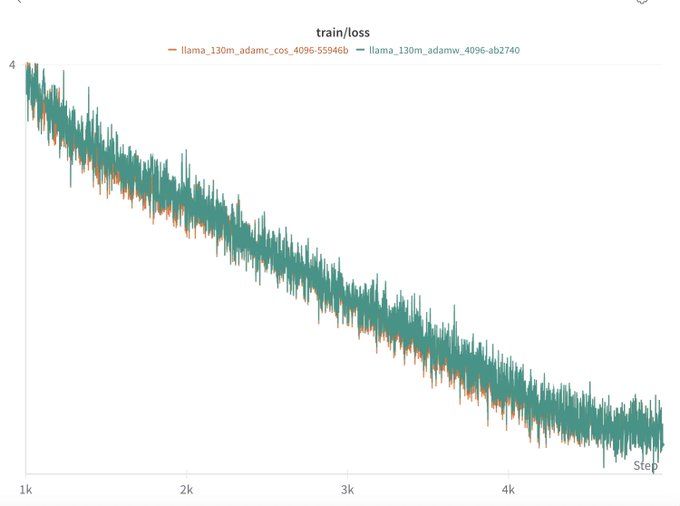
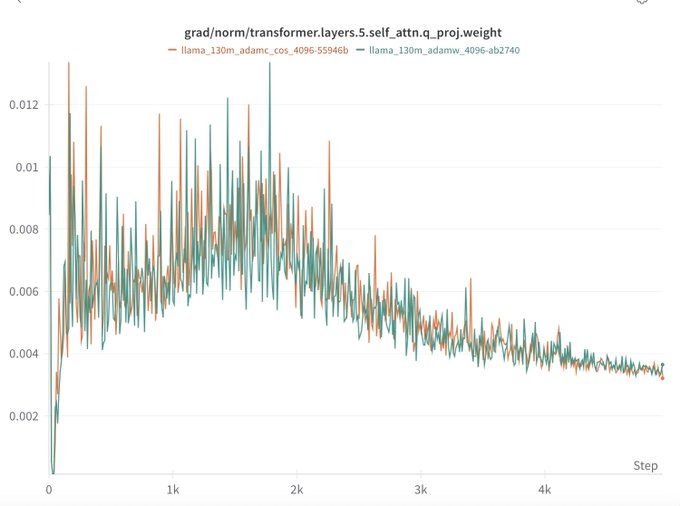
In our most similar setting to the original work (130M model), we don't see AdamC's benefits but
- We use a smaller WD (0.01) identified from sweeps v.s. what is used in the paper (0.05).
- We only train to Chnichilla optimal (2B tokens) whereas the original paper was at 200B.
- We use a smaller WD (0.01) identified from sweeps v.s. what is used in the paper (0.05).
- We only train to Chnichilla optimal (2B tokens) whereas the original paper was at 200B.
July 3, 2025 at 3:15 PM
In our most similar setting to the original work (130M model), we don't see AdamC's benefits but
- We use a smaller WD (0.01) identified from sweeps v.s. what is used in the paper (0.05).
- We only train to Chnichilla optimal (2B tokens) whereas the original paper was at 200B.
- We use a smaller WD (0.01) identified from sweeps v.s. what is used in the paper (0.05).
- We only train to Chnichilla optimal (2B tokens) whereas the original paper was at 200B.
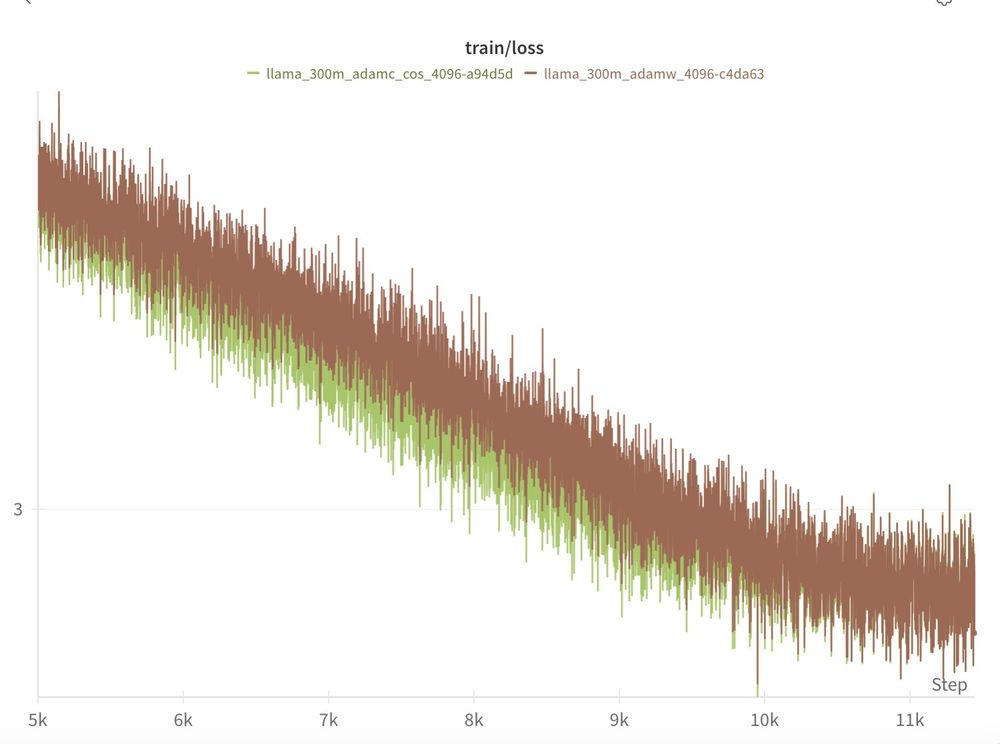
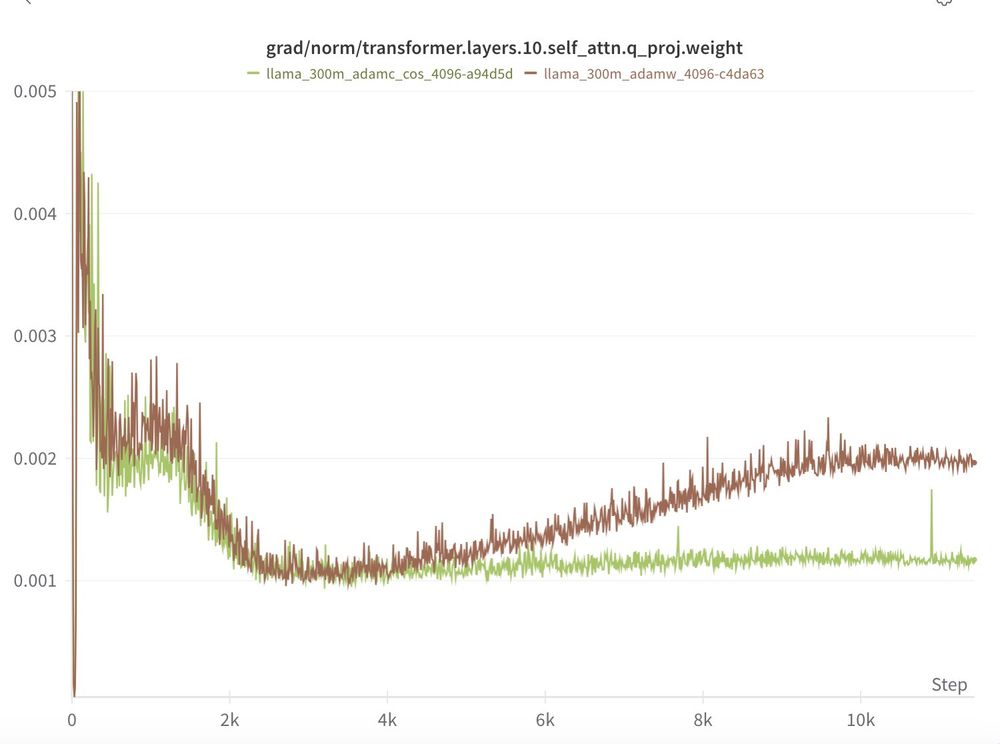
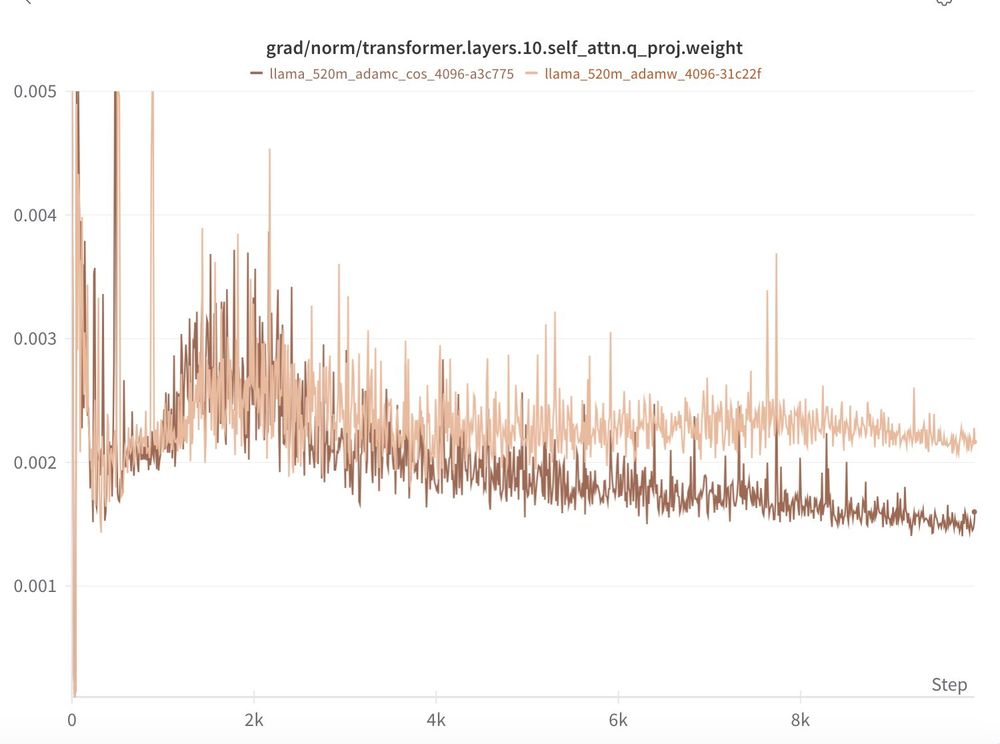
We see the same pattern at 300m and 500m!
Remember, everything else in these experiments is held constant by Levanter & Marin (data order, model init. etc.)
Experiment files here: github.com/marin-commun...
Remember, everything else in these experiments is held constant by Levanter & Marin (data order, model init. etc.)
Experiment files here: github.com/marin-commun...
July 3, 2025 at 3:15 PM
We see the same pattern at 300m and 500m!
Remember, everything else in these experiments is held constant by Levanter & Marin (data order, model init. etc.)
Experiment files here: github.com/marin-commun...
Remember, everything else in these experiments is held constant by Levanter & Marin (data order, model init. etc.)
Experiment files here: github.com/marin-commun...
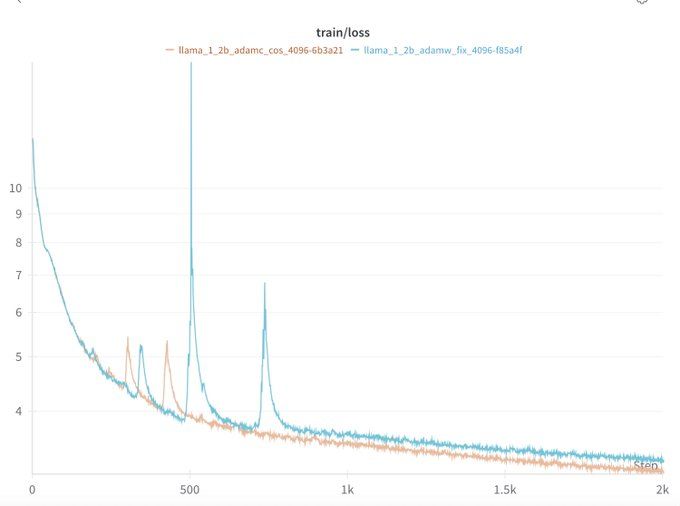
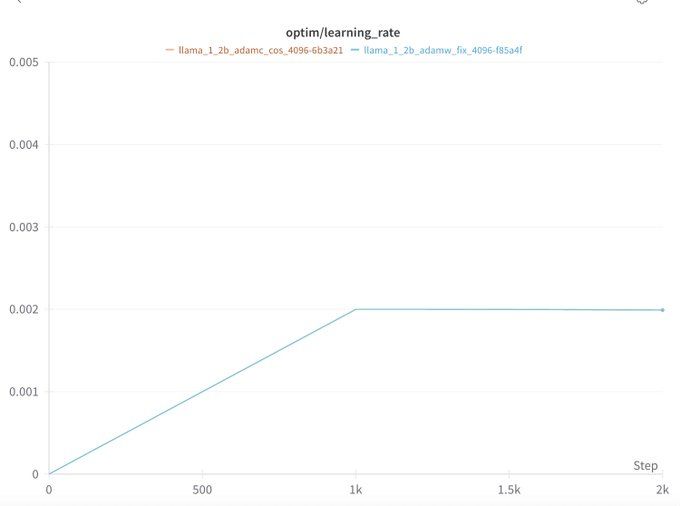
As a side note, Kaiyue Wen found that weight decay also causes slower loss decrease at the start of training in wandb.ai/marin-commun...
Similar to the end of training, this is likely because LR warmup also impacts the LR/WD ratio.
AdamC seems to mitigate this too.
Similar to the end of training, this is likely because LR warmup also impacts the LR/WD ratio.
AdamC seems to mitigate this too.
July 3, 2025 at 3:15 PM
As a side note, Kaiyue Wen found that weight decay also causes slower loss decrease at the start of training in wandb.ai/marin-commun...
Similar to the end of training, this is likely because LR warmup also impacts the LR/WD ratio.
AdamC seems to mitigate this too.
Similar to the end of training, this is likely because LR warmup also impacts the LR/WD ratio.
AdamC seems to mitigate this too.
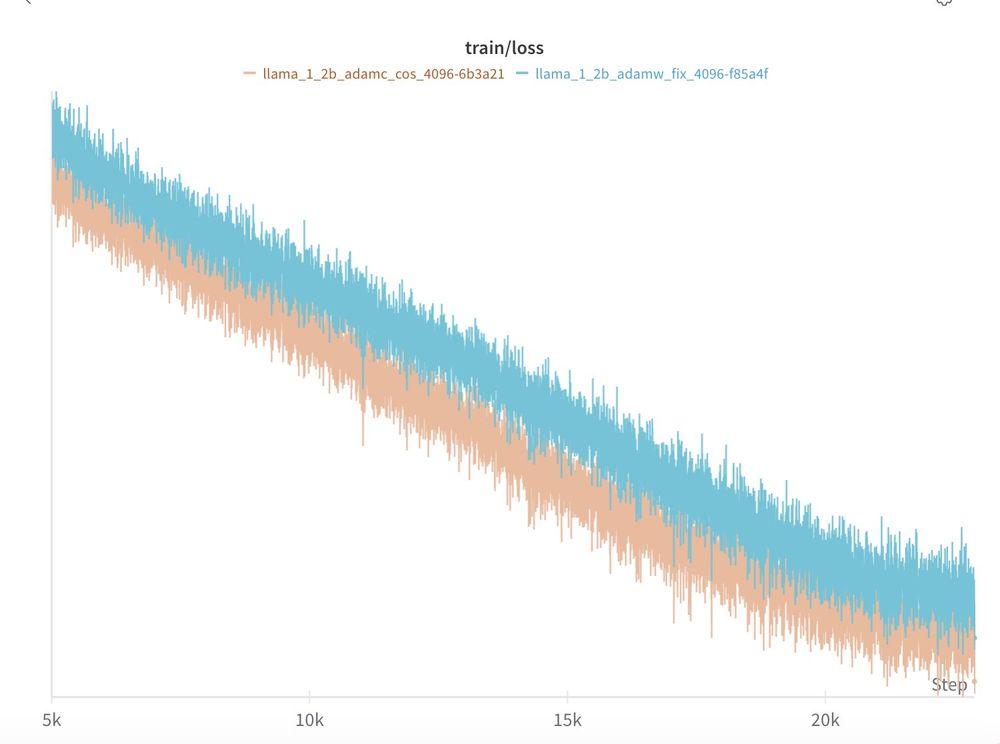
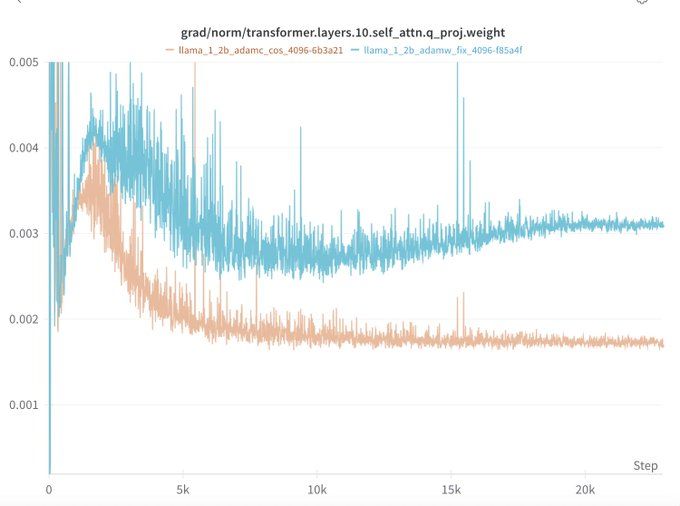
TL;DR: 3/4 of our scales we find the AdamC results to reproduce out of the box!
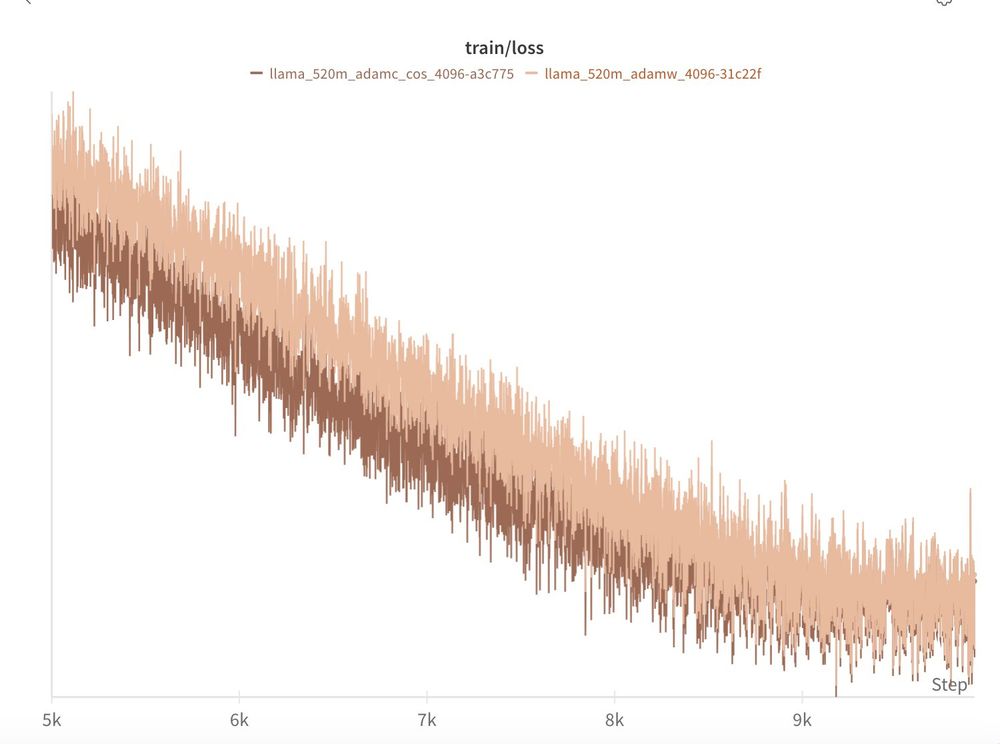
When compared to AdamW with all other factors held constant, AdamC mitigates the gradient ascent at the end of training and leads to an overall lower loss (-0.04)!
When compared to AdamW with all other factors held constant, AdamC mitigates the gradient ascent at the end of training and leads to an overall lower loss (-0.04)!
July 3, 2025 at 3:15 PM
TL;DR: 3/4 of our scales we find the AdamC results to reproduce out of the box!
When compared to AdamW with all other factors held constant, AdamC mitigates the gradient ascent at the end of training and leads to an overall lower loss (-0.04)!
When compared to AdamW with all other factors held constant, AdamC mitigates the gradient ascent at the end of training and leads to an overall lower loss (-0.04)!
As far as I can tell, the models aren't good enough right now that they can replace VFX at any high quality commercial scale.
They are exactly good enough to generate fake viral videos for ad revenue on TikTok/Instagram & spread misinformation. Is there any serious argument for their safe release??
They are exactly good enough to generate fake viral videos for ad revenue on TikTok/Instagram & spread misinformation. Is there any serious argument for their safe release??
June 17, 2025 at 1:32 AM
As far as I can tell, the models aren't good enough right now that they can replace VFX at any high quality commercial scale.
They are exactly good enough to generate fake viral videos for ad revenue on TikTok/Instagram & spread misinformation. Is there any serious argument for their safe release??
They are exactly good enough to generate fake viral videos for ad revenue on TikTok/Instagram & spread misinformation. Is there any serious argument for their safe release??
I don't really see an argument for releasing such models with photorealistic generation capabilities.
What valid & frequent business use case is there for photorealistic video & voice generation like Veo 3 offers?
What valid & frequent business use case is there for photorealistic video & voice generation like Veo 3 offers?
June 17, 2025 at 1:25 AM
I don't really see an argument for releasing such models with photorealistic generation capabilities.
What valid & frequent business use case is there for photorealistic video & voice generation like Veo 3 offers?
What valid & frequent business use case is there for photorealistic video & voice generation like Veo 3 offers?