



Wayne
@waynechi.bsky.social
CS Ph.D. at CMU. Building Copilot Arena. Editor at http://blog.ml.cmu.edu
Interested in trying out Copilot Arena for yourself?
Download at lmarena.ai/copilot.
Follow for more updates!
Download at lmarena.ai/copilot.
Follow for more updates!

Copilot Arena - Visual Studio Marketplace
Extension for Visual Studio Code - Code with and evaluate the latest LLMs and Code Completion models
lmarena.ai
March 5, 2025 at 4:49 PM
Interested in trying out Copilot Arena for yourself?
Download at lmarena.ai/copilot.
Follow for more updates!
Download at lmarena.ai/copilot.
Follow for more updates!
Full Paper with additional analyses: arxiv.org/abs/2502.09328
Code: github.com/lmarena/copi...
w/ Valerie Chen, Anastasios Nikolas Angelopoulos, Wei-Lin Chiang, Aditya Mittal, Naman Jain, Tianjun Zhang, Ion Stoica, @chrisdonahue.com , @atalwalkar.bsky.social
Code: github.com/lmarena/copi...
w/ Valerie Chen, Anastasios Nikolas Angelopoulos, Wei-Lin Chiang, Aditya Mittal, Naman Jain, Tianjun Zhang, Ion Stoica, @chrisdonahue.com , @atalwalkar.bsky.social
arxiv.org
March 5, 2025 at 4:49 PM
Full Paper with additional analyses: arxiv.org/abs/2502.09328
Code: github.com/lmarena/copi...
w/ Valerie Chen, Anastasios Nikolas Angelopoulos, Wei-Lin Chiang, Aditya Mittal, Naman Jain, Tianjun Zhang, Ion Stoica, @chrisdonahue.com , @atalwalkar.bsky.social
Code: github.com/lmarena/copi...
w/ Valerie Chen, Anastasios Nikolas Angelopoulos, Wei-Lin Chiang, Aditya Mittal, Naman Jain, Tianjun Zhang, Ion Stoica, @chrisdonahue.com , @atalwalkar.bsky.social
Our paper analyzes human preferences across 10 SOTA coding models, but we continue to add more models to the live Copilot Arena leaderboard on lmarena.ai!

March 5, 2025 at 4:49 PM
Our paper analyzes human preferences across 10 SOTA coding models, but we continue to add more models to the live Copilot Arena leaderboard on lmarena.ai!
Different data slices affect user preferences disproportionally. There is a drastic difference in relative model performance between real-world tasks such as frontend or backend development versus leetcode style coding challenges but little difference between programming languages.
March 5, 2025 at 4:49 PM
Different data slices affect user preferences disproportionally. There is a drastic difference in relative model performance between real-world tasks such as frontend or backend development versus leetcode style coding challenges but little difference between programming languages.
We attribute these differences to a significant shift in our data distribution. Compared to previous benchmarks, Copilot Arena observes more programming languages (PL), natural languages (NL), longer context lengths, multiple task types, and various code structures.

March 5, 2025 at 4:49 PM
We attribute these differences to a significant shift in our data distribution. Compared to previous benchmarks, Copilot Arena observes more programming languages (PL), natural languages (NL), longer context lengths, multiple task types, and various code structures.
Our leaderboard differs from existing evaluations. In particular, smaller models over perform in static benchmarks compared to real development workflows.

March 5, 2025 at 4:49 PM
Our leaderboard differs from existing evaluations. In particular, smaller models over perform in static benchmarks compared to real development workflows.
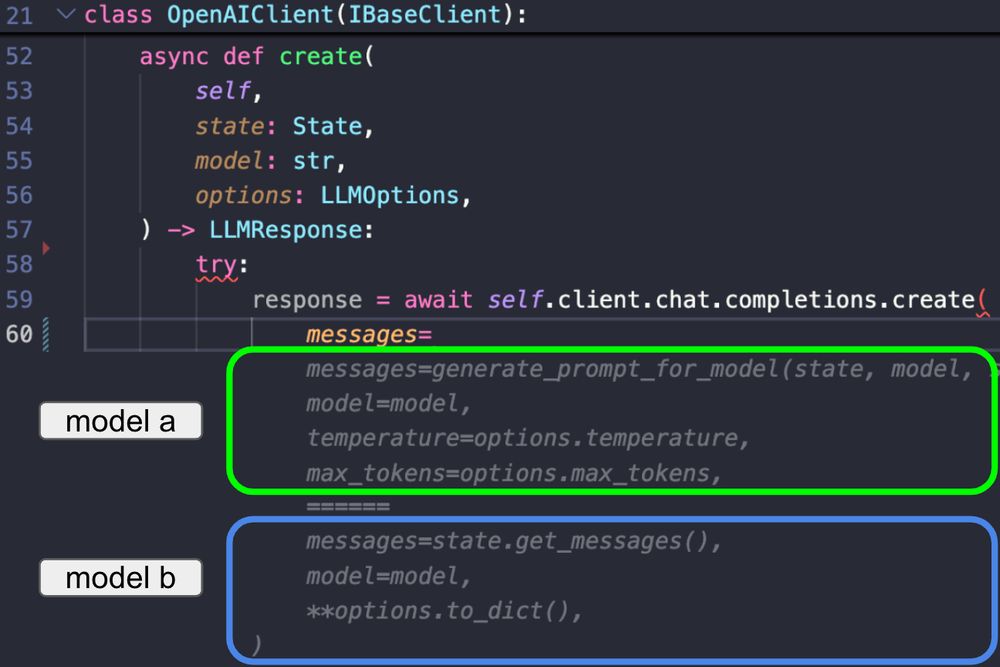
We evaluate models in a developer's IDE by presenting pairs of code completions generated by two different models. This workflow evaluates human preferences across models with real users and tasks in their native environment.
March 5, 2025 at 4:49 PM
We evaluate models in a developer's IDE by presenting pairs of code completions generated by two different models. This workflow evaluates human preferences across models with real users and tasks in their native environment.