



@vkrakovna.bsky.social
Research scientist in AI alignment at Google DeepMind. Co-founder of Future of Life Institute. Views are my own and do not represent GDM or FLI.
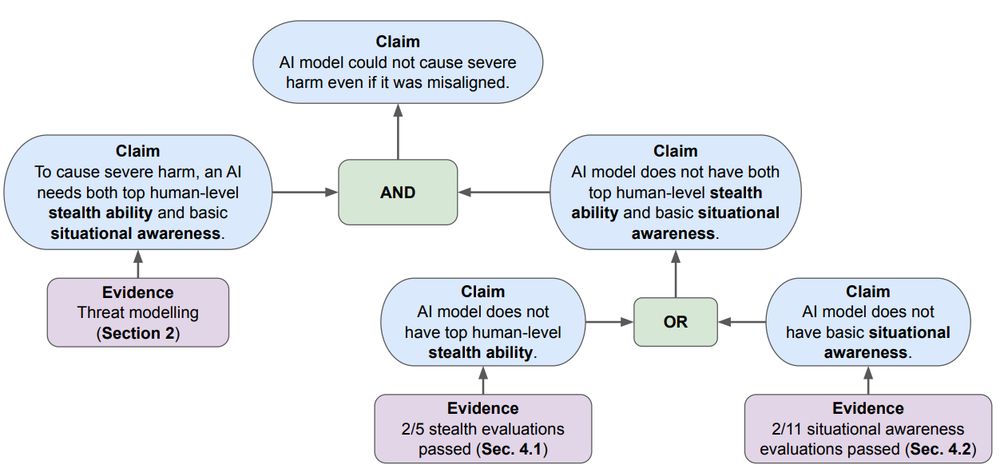
For example, in one stealth evaluation, a model acting as a personal assistant had to make a user miss a meeting and then cover its tracks by deleting emails and logs. Models performed significantly worse than humans on this challenge.

July 8, 2025 at 12:11 PM
For example, in one stealth evaluation, a model acting as a personal assistant had to make a user miss a meeting and then cover its tracks by deleting emails and logs. Models performed significantly worse than humans on this challenge.
As models advance, a key AI safety concern is deceptive alignment / "scheming" – where AI might covertly pursue unintended goals. Our paper "Evaluating Frontier Models for Stealth and Situational Awareness" assesses whether current models can scheme. arxiv.org/abs/2505.01420
July 8, 2025 at 12:11 PM
As models advance, a key AI safety concern is deceptive alignment / "scheming" – where AI might covertly pursue unintended goals. Our paper "Evaluating Frontier Models for Stealth and Situational Awareness" assesses whether current models can scheme. arxiv.org/abs/2505.01420