



Vivek Kalyan
@vivekkalyan.com
Applied AI. Building cartograph.app. Previously: Head of AI @ handshakes.ai 🇸🇬
I write (sparsely) at: vivekkalyan.com
I write (sparsely) at: vivekkalyan.com
We're launching early access for Cartograph (cartograph.app). It takes your codebase, and automatically generates architecture diagrams and documentation for them.
See some demos of open-source repos here (no sign-up required):
cartograph.app/demo
(Reply here if you'd like to see others added)
See some demos of open-source repos here (no sign-up required):
cartograph.app/demo
(Reply here if you'd like to see others added)
December 8, 2024 at 3:01 PM
We're launching early access for Cartograph (cartograph.app). It takes your codebase, and automatically generates architecture diagrams and documentation for them.
See some demos of open-source repos here (no sign-up required):
cartograph.app/demo
(Reply here if you'd like to see others added)
See some demos of open-source repos here (no sign-up required):
cartograph.app/demo
(Reply here if you'd like to see others added)
PPO - replaces the standard reward model with a verification function when the answer can be verified correct (e.g., in mathematics). The model is trained using PPO, only getting a reward if the answer is correct. This works really well to improve domains which have verifiable answers.

November 24, 2024 at 6:04 PM
PPO - replaces the standard reward model with a verification function when the answer can be verified correct (e.g., in mathematics). The model is trained using PPO, only getting a reward if the answer is correct. This works really well to improve domains which have verifiable answers.
DPO ablations - there is much focus on ensuring model follows instruction, mostly leveraging synthetic data methods to create {chosen, rejected} pairs. They also measure that you can take an existing dataset, regenerate it using their synthetic pipeline and it improves performance. Really cool.

November 24, 2024 at 6:04 PM
DPO ablations - there is much focus on ensuring model follows instruction, mostly leveraging synthetic data methods to create {chosen, rejected} pairs. They also measure that you can take an existing dataset, regenerate it using their synthetic pipeline and it improves performance. Really cool.
DPO ablations - on-policy data (generations from the base SFT model) improve model performance. Although, it's interesting to note that they don't seem to train the model for multiple rounds like Llama 3.1 (maybe cost concerns?)

November 24, 2024 at 6:04 PM
DPO ablations - on-policy data (generations from the base SFT model) improve model performance. Although, it's interesting to note that they don't seem to train the model for multiple rounds like Llama 3.1 (maybe cost concerns?)
DPO ablations - the number of unique prompts in the preference dataset matter. More unique prompts result in better downstream performance, while more generations for the same prompts does not. Using different prompts from SFT data also improve performance.

November 24, 2024 at 6:04 PM
DPO ablations - the number of unique prompts in the preference dataset matter. More unique prompts result in better downstream performance, while more generations for the same prompts does not. Using different prompts from SFT data also improve performance.
DPO - preference data is made of a on-policy model pool (Tulu 3 7B/70B) and off-policy model pool (other models). GPT-4o is used to rate generations from 4 random models from the model pool from 1-5. The highest is taken as the chosen response and the rejected response is sampled from the rest.

November 24, 2024 at 6:04 PM
DPO - preference data is made of a on-policy model pool (Tulu 3 7B/70B) and off-policy model pool (other models). GPT-4o is used to rate generations from 4 random models from the model pool from 1-5. The highest is taken as the chosen response and the rejected response is sampled from the rest.
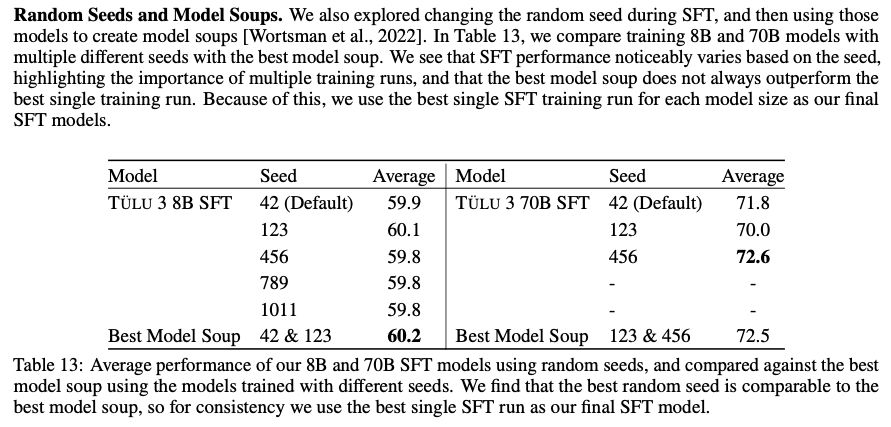
SFT - performance varies greatly depending on the random seed. They tried model soups (averaging weights of multiple models using github.com/arcee-ai/mer...), but decided to choose a single best model instead.
November 24, 2024 at 6:04 PM
SFT - performance varies greatly depending on the random seed. They tried model soups (averaging weights of multiple models using github.com/arcee-ai/mer...), but decided to choose a single best model instead.
SFT - using a better pretrained model (Qwen 2.5) results in better scores for GSM8K and MATH. Kinda surprising since the final model is still Llama 3.1, wonder if they evaluated Qwen 2.5 on other datasets as well and if the performance was not good enough to be the base model?

November 24, 2024 at 6:04 PM
SFT - using a better pretrained model (Qwen 2.5) results in better scores for GSM8K and MATH. Kinda surprising since the final model is still Llama 3.1, wonder if they evaluated Qwen 2.5 on other datasets as well and if the performance was not good enough to be the base model?
SFT - a couple of data ablations:
- Adding safety data didn't negatively affect other skills. - Measured the removal of math data on GSM8K and MATH, confirming that the scores drop.
- Measured the the effectiveness of WildChat (diverse chat data) and Persona (skill based data)
- Adding safety data didn't negatively affect other skills. - Measured the removal of math data on GSM8K and MATH, confirming that the scores drop.
- Measured the the effectiveness of WildChat (diverse chat data) and Persona (skill based data)

November 24, 2024 at 6:04 PM
SFT - a couple of data ablations:
- Adding safety data didn't negatively affect other skills. - Measured the removal of math data on GSM8K and MATH, confirming that the scores drop.
- Measured the the effectiveness of WildChat (diverse chat data) and Persona (skill based data)
- Adding safety data didn't negatively affect other skills. - Measured the removal of math data on GSM8K and MATH, confirming that the scores drop.
- Measured the the effectiveness of WildChat (diverse chat data) and Persona (skill based data)
SFT - for the data, train models on skill specific data mixtures, keep the mixtures that lead to the best performance on those skills. Later, combine the mixtures and do decontamination/downsampling of larger datasets.

November 24, 2024 at 6:04 PM
SFT - for the data, train models on skill specific data mixtures, keep the mixtures that lead to the best performance on those skills. Later, combine the mixtures and do decontamination/downsampling of larger datasets.
Data decontamination
- n-gram matching works better than embedding methods in terms of precision
- 8-gram matching only on user-turns (since completions are LLM generated)
- remove training sets that have more than 2% overlap with any evaluation set
- n-gram matching works better than embedding methods in terms of precision
- 8-gram matching only on user-turns (since completions are LLM generated)
- remove training sets that have more than 2% overlap with any evaluation set

November 24, 2024 at 6:04 PM
Data decontamination
- n-gram matching works better than embedding methods in terms of precision
- 8-gram matching only on user-turns (since completions are LLM generated)
- remove training sets that have more than 2% overlap with any evaluation set
- n-gram matching works better than embedding methods in terms of precision
- 8-gram matching only on user-turns (since completions are LLM generated)
- remove training sets that have more than 2% overlap with any evaluation set
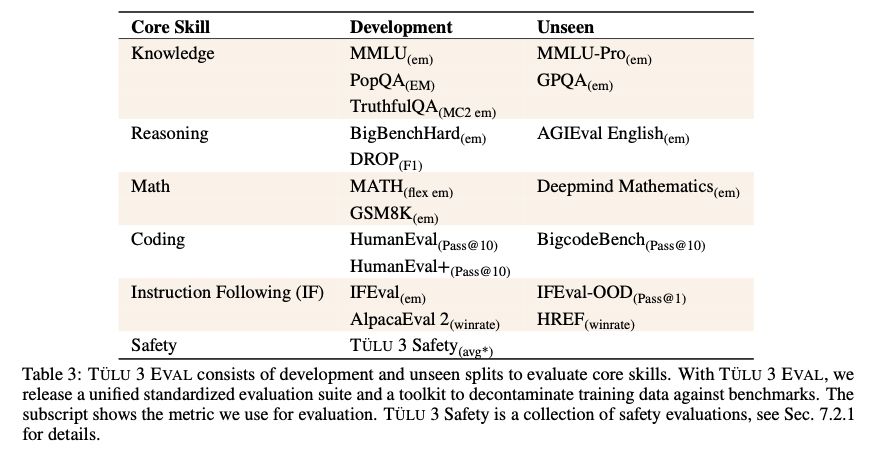
Core skills - they identify some key areas open post-training models struggle with and target those for improving, picking datasets in those areas for evaluation. Notably, they avoid looking at scores from the unseen set during development to assess if their choices might have led to overfitting.
November 24, 2024 at 6:04 PM
Core skills - they identify some key areas open post-training models struggle with and target those for improving, picking datasets in those areas for evaluation. Notably, they avoid looking at scores from the unseen set during development to assess if their choices might have led to overfitting.
Not asking you to stop, but I was hacking around with the firehose feed and I was utterly confused why I'm getting posts from Feb 2024. Now I know why 🙂

November 23, 2024 at 4:27 PM
Not asking you to stop, but I was hacking around with the firehose feed and I was utterly confused why I'm getting posts from Feb 2024. Now I know why 🙂
I spent today making this with wife, really happy how it turned out!

November 23, 2024 at 2:32 PM
I spent today making this with wife, really happy how it turned out!