



Vishaal Udandarao
@vishaalurao.bsky.social
@ELLISforEurope PhD Student @bethgelab @caml_lab @Cambridge_Uni @uni_tue; Currently SR @GoogleAI; Previously MPhil @Cambridge_Uni, RA @RutgersU, UG @iiitdelhi
vishaal27.github.io
vishaal27.github.io
Bonus: Along the way, we found current state of CLIP zero-shot benchmarking in disarray—some test datasets have a seed std of ~12%!
We construct a stable & reliable set of evaluations (StableEval) inspired by the inverse-variance-weighting method, to prune out unreliable evals!
We construct a stable & reliable set of evaluations (StableEval) inspired by the inverse-variance-weighting method, to prune out unreliable evals!

December 2, 2024 at 6:03 PM
Bonus: Along the way, we found current state of CLIP zero-shot benchmarking in disarray—some test datasets have a seed std of ~12%!
We construct a stable & reliable set of evaluations (StableEval) inspired by the inverse-variance-weighting method, to prune out unreliable evals!
We construct a stable & reliable set of evaluations (StableEval) inspired by the inverse-variance-weighting method, to prune out unreliable evals!
Finally, we scale all our insights to pretrain SoTA FLOP-efficient models across three different FLOP-scales: ACED-F{0,1,2}
Outperforming strong baselines including Apple's MobileCLIP, TinyCLIP and @datologyai.com CLIP models!
Outperforming strong baselines including Apple's MobileCLIP, TinyCLIP and @datologyai.com CLIP models!

December 2, 2024 at 6:02 PM
Finally, we scale all our insights to pretrain SoTA FLOP-efficient models across three different FLOP-scales: ACED-F{0,1,2}
Outperforming strong baselines including Apple's MobileCLIP, TinyCLIP and @datologyai.com CLIP models!
Outperforming strong baselines including Apple's MobileCLIP, TinyCLIP and @datologyai.com CLIP models!
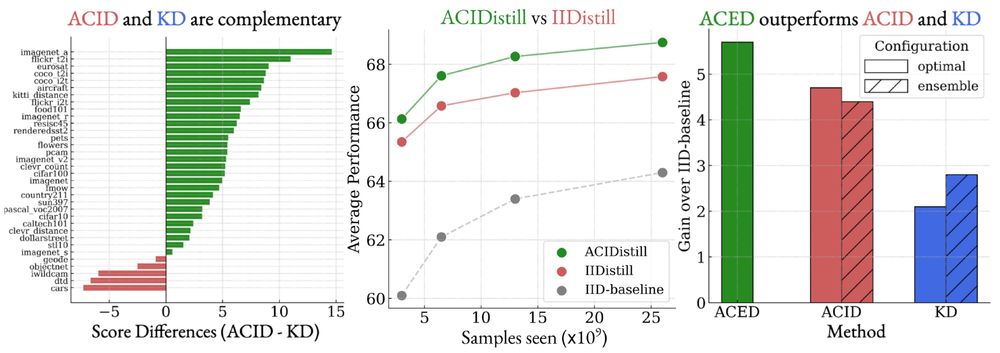
There's more! ACID and KD are complementary — they can be profitably combined, at scale! Our simple pretraining recipe ACED-ACIDistill showcases continued benefits as we scale to 26B samples seen!
December 2, 2024 at 6:02 PM
There's more! ACID and KD are complementary — they can be profitably combined, at scale! Our simple pretraining recipe ACED-ACIDistill showcases continued benefits as we scale to 26B samples seen!
We also show that ACID strongly outperforms KD across different reference/teacher training datasets, KD objectives, and student sizes.

December 2, 2024 at 6:01 PM
We also show that ACID strongly outperforms KD across different reference/teacher training datasets, KD objectives, and student sizes.
Our ACID method shows very strong scaling properties as the size of the reference model increases, until we hit a saturation point — the optimal reference-student capacity ratio.
Further, ACID significantly outperforms KD as we scale up the reference/teacher sizes.
Further, ACID significantly outperforms KD as we scale up the reference/teacher sizes.

December 2, 2024 at 6:01 PM
Our ACID method shows very strong scaling properties as the size of the reference model increases, until we hit a saturation point — the optimal reference-student capacity ratio.
Further, ACID significantly outperforms KD as we scale up the reference/teacher sizes.
Further, ACID significantly outperforms KD as we scale up the reference/teacher sizes.
As our ACID method performs implicit distillation, we can further combine our data curation strategy with an explicit distillation objective, and conduct a series of experiments to determine the optimal combination strategy.

December 2, 2024 at 6:00 PM
As our ACID method performs implicit distillation, we can further combine our data curation strategy with an explicit distillation objective, and conduct a series of experiments to determine the optimal combination strategy.
Our online curation method (ACID) uses large pretrained reference models (adopting from prior work: JEST) & we show a theoretical equivalence b/w KD and ACID (appx C in paper).

December 2, 2024 at 6:00 PM
Our online curation method (ACID) uses large pretrained reference models (adopting from prior work: JEST) & we show a theoretical equivalence b/w KD and ACID (appx C in paper).
TLDR: We introduce an online data curation method that when coupled with simple softmax knowledge distillation produces a very effective pretraining recipe yielding SoTA inference-efficient two-tower contrastive VLMs!

December 2, 2024 at 5:59 PM
TLDR: We introduce an online data curation method that when coupled with simple softmax knowledge distillation produces a very effective pretraining recipe yielding SoTA inference-efficient two-tower contrastive VLMs!
🚀New Paper: Active Data Curation Effectively Distills Multimodal Models
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇

December 2, 2024 at 5:59 PM
🚀New Paper: Active Data Curation Effectively Distills Multimodal Models
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇