



@vinhtong.bsky.social
Many thanks to my collaborators Dung Hoang, @anjiliu.bsky.social, @guyvdb.bsky.social, and @mniepert.bsky.social.
February 13, 2025 at 8:31 AM
Many thanks to my collaborators Dung Hoang, @anjiliu.bsky.social, @guyvdb.bsky.social, and @mniepert.bsky.social.

[9/n] Beyond Image Generation
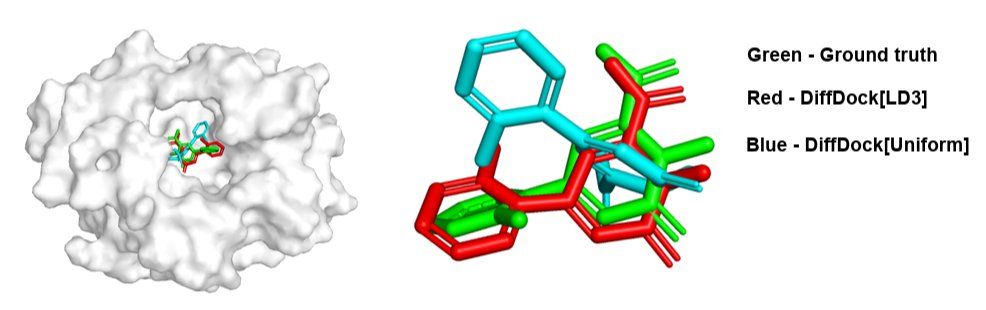
LD3 can be applied to diffusion models in other domains, such as molecular docking.
LD3 can be applied to diffusion models in other domains, such as molecular docking.
February 13, 2025 at 8:31 AM
[9/n] Beyond Image Generation
LD3 can be applied to diffusion models in other domains, such as molecular docking.
LD3 can be applied to diffusion models in other domains, such as molecular docking.
[8/n] LD3 is fast
LD3 can be trained on a single GPU in under one hour. For smaller datasets like CIFAR-10, training can be completed in less than 6 minutes.
LD3 can be trained on a single GPU in under one hour. For smaller datasets like CIFAR-10, training can be completed in less than 6 minutes.

February 13, 2025 at 8:31 AM
[8/n] LD3 is fast
LD3 can be trained on a single GPU in under one hour. For smaller datasets like CIFAR-10, training can be completed in less than 6 minutes.
LD3 can be trained on a single GPU in under one hour. For smaller datasets like CIFAR-10, training can be completed in less than 6 minutes.
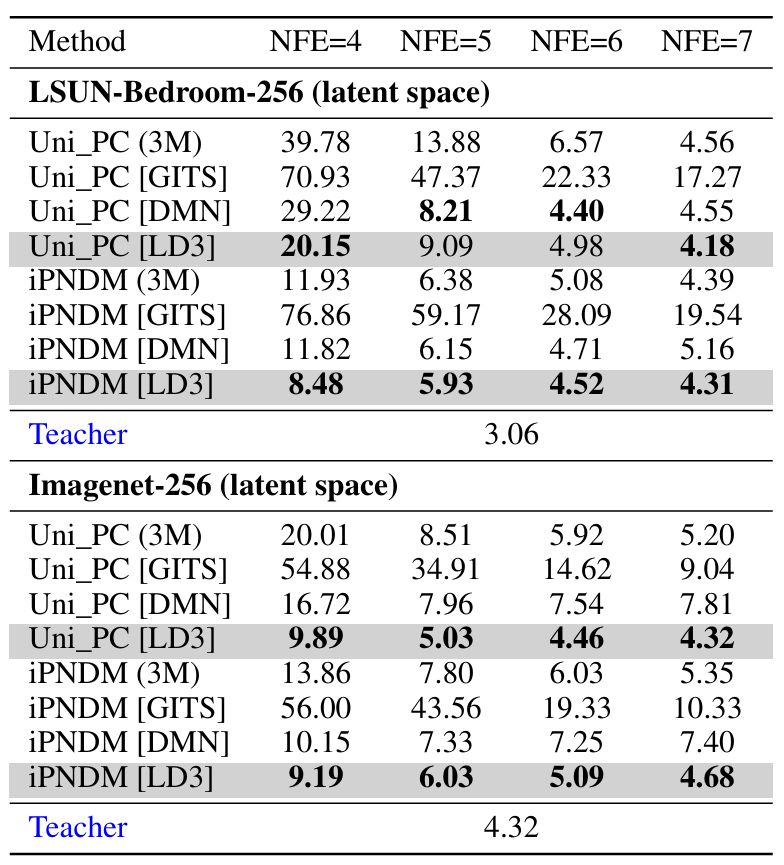
[7/n]
LD3 significantly improves sample quality.
LD3 significantly improves sample quality.

February 13, 2025 at 8:31 AM
[7/n]
LD3 significantly improves sample quality.
LD3 significantly improves sample quality.
[6/n]
This surrogate loss is theoretically close to the original distillation objective, leading to better convergence and avoiding underfitting.
This surrogate loss is theoretically close to the original distillation objective, leading to better convergence and avoiding underfitting.

February 13, 2025 at 8:31 AM
[6/n]
This surrogate loss is theoretically close to the original distillation objective, leading to better convergence and avoiding underfitting.
This surrogate loss is theoretically close to the original distillation objective, leading to better convergence and avoiding underfitting.
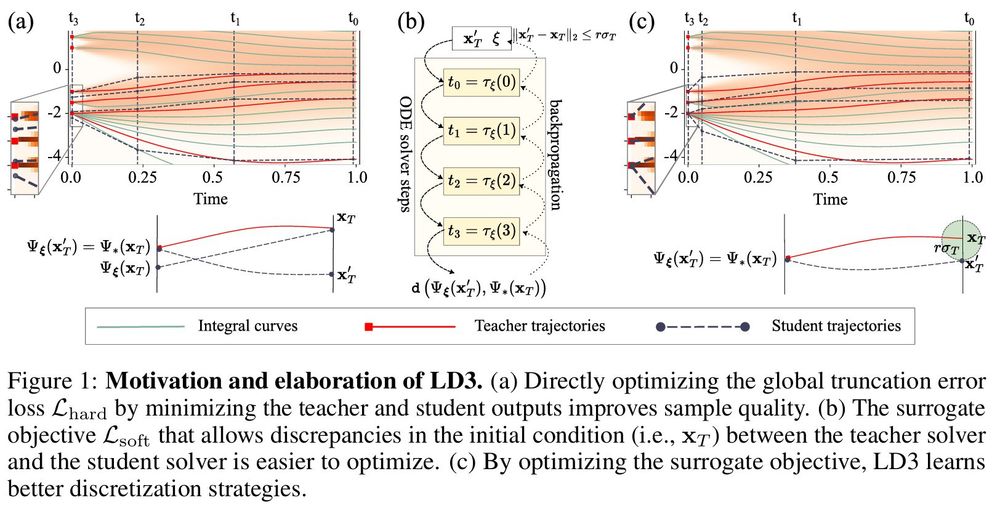
[5/n] Soft constraint
A potential problem with the student model is its limited capacity. To address this, we propose a soft surrogate loss, simplifying the student's optimization task.
A potential problem with the student model is its limited capacity. To address this, we propose a soft surrogate loss, simplifying the student's optimization task.
February 13, 2025 at 8:31 AM
[5/n] Soft constraint
A potential problem with the student model is its limited capacity. To address this, we propose a soft surrogate loss, simplifying the student's optimization task.
A potential problem with the student model is its limited capacity. To address this, we propose a soft surrogate loss, simplifying the student's optimization task.
[4/n] How?
LD3 uses a teacher-student framework:
🔹Teacher: Runs the ODE solver with small step sizes.
🔹Student: Learns optimal discretization to match the teacher's output.
🔹Backpropagates through the ODE solver to refine time steps.
LD3 uses a teacher-student framework:
🔹Teacher: Runs the ODE solver with small step sizes.
🔹Student: Learns optimal discretization to match the teacher's output.
🔹Backpropagates through the ODE solver to refine time steps.
February 13, 2025 at 8:31 AM
[4/n] How?
LD3 uses a teacher-student framework:
🔹Teacher: Runs the ODE solver with small step sizes.
🔹Student: Learns optimal discretization to match the teacher's output.
🔹Backpropagates through the ODE solver to refine time steps.
LD3 uses a teacher-student framework:
🔹Teacher: Runs the ODE solver with small step sizes.
🔹Student: Learns optimal discretization to match the teacher's output.
🔹Backpropagates through the ODE solver to refine time steps.
[3/n] Key idea
LD3 optimizes the time discretization for diffusion ODE solvers by minimizing the global truncation error, resulting in higher sample quality with fewer sampling steps.
LD3 optimizes the time discretization for diffusion ODE solvers by minimizing the global truncation error, resulting in higher sample quality with fewer sampling steps.
February 13, 2025 at 8:31 AM
[3/n] Key idea
LD3 optimizes the time discretization for diffusion ODE solvers by minimizing the global truncation error, resulting in higher sample quality with fewer sampling steps.
LD3 optimizes the time discretization for diffusion ODE solvers by minimizing the global truncation error, resulting in higher sample quality with fewer sampling steps.
[2/n]
Diffusion models produce high-quality generations but are computationally expensive due to multi-step sampling. Existing acceleration methods either require costly retraining (distillation) or depend on manually designed time discretization heuristics. LD3 changes that.
Diffusion models produce high-quality generations but are computationally expensive due to multi-step sampling. Existing acceleration methods either require costly retraining (distillation) or depend on manually designed time discretization heuristics. LD3 changes that.
February 13, 2025 at 8:31 AM
[2/n]
Diffusion models produce high-quality generations but are computationally expensive due to multi-step sampling. Existing acceleration methods either require costly retraining (distillation) or depend on manually designed time discretization heuristics. LD3 changes that.
Diffusion models produce high-quality generations but are computationally expensive due to multi-step sampling. Existing acceleration methods either require costly retraining (distillation) or depend on manually designed time discretization heuristics. LD3 changes that.