




Verena Blaschke
@verenablaschke.bsky.social
PhD student @mainlp.bsky.social (@cislmu.bsky.social, LMU Munich). Interested in language variation & change, currently working on NLP for dialects and low-resource languages.
verenablaschke.github.io
verenablaschke.github.io
Reposted by Verena Blaschke

📄DistaLs: A Comprehensive Collection of Language Distance Measures
👥 Rob van der Goot, Esther Ploeger, @verenablaschke.bsky.social Tanja Samardžic
🔗 aclanthology.org/2025.emnlp-d...
🎯A convenient toolkit for obtaining distance measures across languages
▶️ www.youtube.com/watch?v=SSk9...
👥 Rob van der Goot, Esther Ploeger, @verenablaschke.bsky.social Tanja Samardžic
🔗 aclanthology.org/2025.emnlp-d...
🎯A convenient toolkit for obtaining distance measures across languages
▶️ www.youtube.com/watch?v=SSk9...
November 5, 2025 at 1:17 PM
📄DistaLs: A Comprehensive Collection of Language Distance Measures
👥 Rob van der Goot, Esther Ploeger, @verenablaschke.bsky.social Tanja Samardžic
🔗 aclanthology.org/2025.emnlp-d...
🎯A convenient toolkit for obtaining distance measures across languages
▶️ www.youtube.com/watch?v=SSk9...
👥 Rob van der Goot, Esther Ploeger, @verenablaschke.bsky.social Tanja Samardžic
🔗 aclanthology.org/2025.emnlp-d...
🎯A convenient toolkit for obtaining distance measures across languages
▶️ www.youtube.com/watch?v=SSk9...
It was fun to do a bit of science outreach, but I also found it super interesting to get a look behind the scenes of how a tv segment is made 😃
October 24, 2025 at 1:07 PM
It was fun to do a bit of science outreach, but I also found it super interesting to get a look behind the scenes of how a tv segment is made 😃
The work I talked about is mainly described in this paper on German dialect ASR:
bsky.app/profile/vere...
bsky.app/profile/vere...
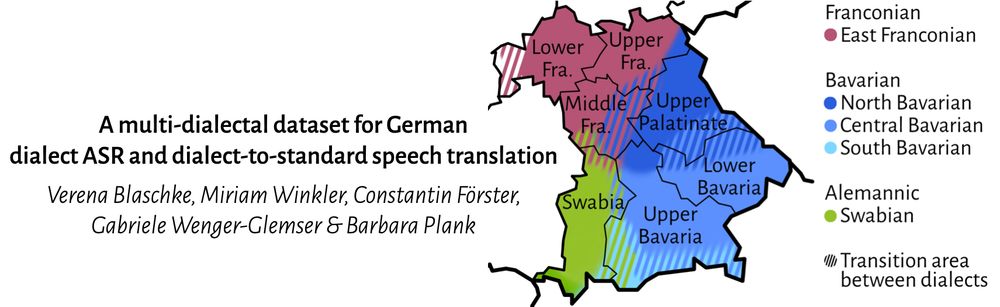
At #Interspeech2025 I'm going to present Betthupferl, a dataset for German dialect ASR & dialect-to-standard speech translation! We analyze differences between dialectal & Standard German transcriptions, benchmark ASR models, and examine shortcomings of current ASR models & evaluation metrics.
October 24, 2025 at 1:07 PM
The work I talked about is mainly described in this paper on German dialect ASR:
bsky.app/profile/vere...
bsky.app/profile/vere...
Timeline:
- Paper submission: Dec 19
- Commitment for pre-reviewed papers: Jan 2
- Acceptance notifs: Jan 23
- Camera-ready: Feb 3
- Workshop: TBD (Mar 24-29)
Organizers:
Yves Scherrer, Noëmi Aepli, @tosaja.bsky.social, Nikola Ljubešić, Preslav Nakov, @tiedeman.bsky.social, Marcos Zampieri & me
- Paper submission: Dec 19
- Commitment for pre-reviewed papers: Jan 2
- Acceptance notifs: Jan 23
- Camera-ready: Feb 3
- Workshop: TBD (Mar 24-29)
Organizers:
Yves Scherrer, Noëmi Aepli, @tosaja.bsky.social, Nikola Ljubešić, Preslav Nakov, @tiedeman.bsky.social, Marcos Zampieri & me
October 21, 2025 at 10:36 AM
Timeline:
- Paper submission: Dec 19
- Commitment for pre-reviewed papers: Jan 2
- Acceptance notifs: Jan 23
- Camera-ready: Feb 3
- Workshop: TBD (Mar 24-29)
Organizers:
Yves Scherrer, Noëmi Aepli, @tosaja.bsky.social, Nikola Ljubešić, Preslav Nakov, @tiedeman.bsky.social, Marcos Zampieri & me
- Paper submission: Dec 19
- Commitment for pre-reviewed papers: Jan 2
- Acceptance notifs: Jan 23
- Camera-ready: Feb 3
- Workshop: TBD (Mar 24-29)
Organizers:
Yves Scherrer, Noëmi Aepli, @tosaja.bsky.social, Nikola Ljubešić, Preslav Nakov, @tiedeman.bsky.social, Marcos Zampieri & me
Has the "Black LLMirror" work already been published / is it going to be turned into a publication? I'd love to read more about it!
October 14, 2025 at 1:14 PM
Has the "Black LLMirror" work already been published / is it going to be turned into a publication? I'd love to read more about it!
Check out the...
- talk on Mon Aug 18, 15:50–16:10
- preprint: arxiv.org/abs/2506.02894
- suppl. material: github.com/mainlp/betth...
Joint work w/ Miriam Winkler & @barbaraplank.bsky.social from @mainlp.bsky.social, and Constantin Förster & Gabriele Wenger-Glemser from Bayerischer Rundfunk!
- talk on Mon Aug 18, 15:50–16:10
- preprint: arxiv.org/abs/2506.02894
- suppl. material: github.com/mainlp/betth...
Joint work w/ Miriam Winkler & @barbaraplank.bsky.social from @mainlp.bsky.social, and Constantin Förster & Gabriele Wenger-Glemser from Bayerischer Rundfunk!

A Multi-Dialectal Dataset for German Dialect ASR and Dialect-to-Standard Speech Translation
Although Germany has a diverse landscape of dialects, they are underrepresented in current automatic speech recognition (ASR) research. To enable studies of how robust models are towards dialectal var...
arxiv.org
August 7, 2025 at 8:46 AM
Check out the...
- talk on Mon Aug 18, 15:50–16:10
- preprint: arxiv.org/abs/2506.02894
- suppl. material: github.com/mainlp/betth...
Joint work w/ Miriam Winkler & @barbaraplank.bsky.social from @mainlp.bsky.social, and Constantin Förster & Gabriele Wenger-Glemser from Bayerischer Rundfunk!
- talk on Mon Aug 18, 15:50–16:10
- preprint: arxiv.org/abs/2506.02894
- suppl. material: github.com/mainlp/betth...
Joint work w/ Miriam Winkler & @barbaraplank.bsky.social from @mainlp.bsky.social, and Constantin Förster & Gabriele Wenger-Glemser from Bayerischer Rundfunk!
Automatic metrics like WER and human quality judgements are moderately correlated. Dialectal words are often rendered as nonsense. Dialectal syntactic structures are often retained in the output – whether this is acceptable in Std German is hit-or-miss.
August 7, 2025 at 8:46 AM
Automatic metrics like WER and human quality judgements are moderately correlated. Dialectal words are often rendered as nonsense. Dialectal syntactic structures are often retained in the output – whether this is acceptable in Std German is hit-or-miss.
All ASR models we benchmark perform much better on Standard German than dialectal audio. Whether the transcriptions of the dialectal audios tend to be closer to the Std German references or to the dialectal references depends on the model decoder type.
August 7, 2025 at 8:46 AM
All ASR models we benchmark perform much better on Standard German than dialectal audio. Whether the transcriptions of the dialectal audios tend to be closer to the Std German references or to the dialectal references depends on the model decoder type.
Betthupferl contains sentences from three dialect groups spoken in southeast Germany, as well as Std German sentences for comparison. The dialectal sentences have both dialectal and Std German gold transcriptions, showing differences between pronunciation, word choice and morphosyntax.

August 7, 2025 at 8:46 AM
Betthupferl contains sentences from three dialect groups spoken in southeast Germany, as well as Std German sentences for comparison. The dialectal sentences have both dialectal and Std German gold transcriptions, showing differences between pronunciation, word choice and morphosyntax.
The poster presentation slot got moved to Tuesday, 16:00–17:30!
July 27, 2025 at 2:27 PM
The poster presentation slot got moved to Tuesday, 16:00–17:30!
Joint work with Masha Fedzechkina and @maartjeterhoeve.bsky.social produced during my internship at Apple last year!
See you at the Findings poster reception on Monday July 28 (18:00-19:30) :)
Preprint: arxiv.org/abs/2501.14491
See you at the Findings poster reception on Monday July 28 (18:00-19:30) :)
Preprint: arxiv.org/abs/2501.14491
Analyzing the Effect of Linguistic Similarity on Cross-Lingual Transfer: Tasks and Experimental Setups Matter
Cross-lingual transfer is a popular approach to increase the amount of training data for NLP tasks in a low-resource context. However, the best strategy to decide which cross-lingual data to include i...
arxiv.org
July 18, 2025 at 10:45 AM
Joint work with Masha Fedzechkina and @maartjeterhoeve.bsky.social produced during my internship at Apple last year!
See you at the Findings poster reception on Monday July 28 (18:00-19:30) :)
Preprint: arxiv.org/abs/2501.14491
See you at the Findings poster reception on Monday July 28 (18:00-19:30) :)
Preprint: arxiv.org/abs/2501.14491
In practice, selecting a transfer language based on just one relevant similarity measure or the transfer results on a similar NLP task w/ similar input representations works well -- although it's best to compare multiple promising transfer candidates.
July 18, 2025 at 10:45 AM
In practice, selecting a transfer language based on just one relevant similarity measure or the transfer results on a similar NLP task w/ similar input representations works well -- although it's best to compare multiple promising transfer candidates.
... Topic classification based on n-grams is sensitive to string overlap (+ correlated linguistic measures), but topic classification based on mBERT embeddings doesn't show any strong correlations – here, inclusion in the pre-training data is important instead.
July 18, 2025 at 10:45 AM
... Topic classification based on n-grams is sensitive to string overlap (+ correlated linguistic measures), but topic classification based on mBERT embeddings doesn't show any strong correlations – here, inclusion in the pre-training data is important instead.
Fortunately, the patterns confirm our intuitions – e.g., syntactic similarity matters for parsing but not for topic classification. However, input representations matter too....
July 18, 2025 at 10:45 AM
Fortunately, the patterns confirm our intuitions – e.g., syntactic similarity matters for parsing but not for topic classification. However, input representations matter too....