



Travis Reid
@treid803.bsky.social
PhD Student at ODU CS and member of @webscidl.bsky.social.
Goel et al.’s crawler (Jawa) removes some non-deterministic JavaScript code so that the replay of an archived web page does not change if different users replay it. Removing this code resulted in storage savings of 41% and improved the crawling throughput by 39%.


June 11, 2025 at 11:34 PM
Goel et al.’s crawler (Jawa) removes some non-deterministic JavaScript code so that the replay of an archived web page does not change if different users replay it. Removing this code resulted in storage savings of 41% and improved the crawling throughput by 39%.
While working on the Saving Ads project, we encountered similar problems that involved JavaScript code generating URLs with random values that differed during crawl time and replay time. A Google SafeFrame URL is an example where a random value in the URL caused a replay problem.

June 11, 2025 at 11:34 PM
While working on the Saving Ads project, we encountered similar problems that involved JavaScript code generating URLs with random values that differed during crawl time and replay time. A Google SafeFrame URL is an example where a random value in the URL caused a replay problem.
When non-determinism causes variance in resources’ URLs it results in failed requests, which prevents resources from loading.
Goel et al. matched a requested URL with a crawled URL by removing the query string (querystrip) and using Levenshtein distance (fuzzy matching).
Goel et al. matched a requested URL with a crawled URL by removing the query string (querystrip) and using Levenshtein distance (fuzzy matching).

June 11, 2025 at 11:34 PM
When non-determinism causes variance in resources’ URLs it results in failed requests, which prevents resources from loading.
Goel et al. matched a requested URL with a crawled URL by removing the query string (querystrip) and using Levenshtein distance (fuzzy matching).
Goel et al. matched a requested URL with a crawled URL by removing the query string (querystrip) and using Levenshtein distance (fuzzy matching).
Sources of non-determinism identified by Goel et al:
> Server-side state
> Client side state
> Client characteristics
> JavaScript's Date, Random, and Performance APIs
> Server-side state
> Client side state
> Client characteristics
> JavaScript's Date, Random, and Performance APIs
June 11, 2025 at 11:34 PM
Sources of non-determinism identified by Goel et al:
> Server-side state
> Client side state
> Client characteristics
> JavaScript's Date, Random, and Performance APIs
> Server-side state
> Client side state
> Client characteristics
> JavaScript's Date, Random, and Performance APIs
Our tech report provides additional details not covered in the blog posts:
bsky.app/profile/trei...
(7/7)
bsky.app/profile/trei...
(7/7)
Our new tech report (arxiv.org/abs/2502.01525): "Archiving and Replaying Current Web Advertisements…" describes the archiving and replay problems we encountered while creating a dataset of 279 archived ads.
#WebArchiveWednesday @webscidl.bsky.social
@machawk1 @phonedudemln @weiglemc
(1/10)
#WebArchiveWednesday @webscidl.bsky.social
@machawk1 @phonedudemln @weiglemc
(1/10)

February 12, 2025 at 8:58 PM
Our tech report provides additional details not covered in the blog posts:
bsky.app/profile/trei...
(7/7)
bsky.app/profile/trei...
(7/7)
To learn more about the replay problems identified while creating this dataset you can read this blog post:
ws-dl.blogspot.com/2024/12/2024...
(6/7)
ws-dl.blogspot.com/2024/12/2024...
(6/7)

2024-12-04: Problems With Replaying Ads That Use iframes
The Web Science and Digital Libraries Research Group at Old Dominion University.
ws-dl.blogspot.com
February 12, 2025 at 8:58 PM
To learn more about the replay problems identified while creating this dataset you can read this blog post:
ws-dl.blogspot.com/2024/12/2024...
(6/7)
ws-dl.blogspot.com/2024/12/2024...
(6/7)
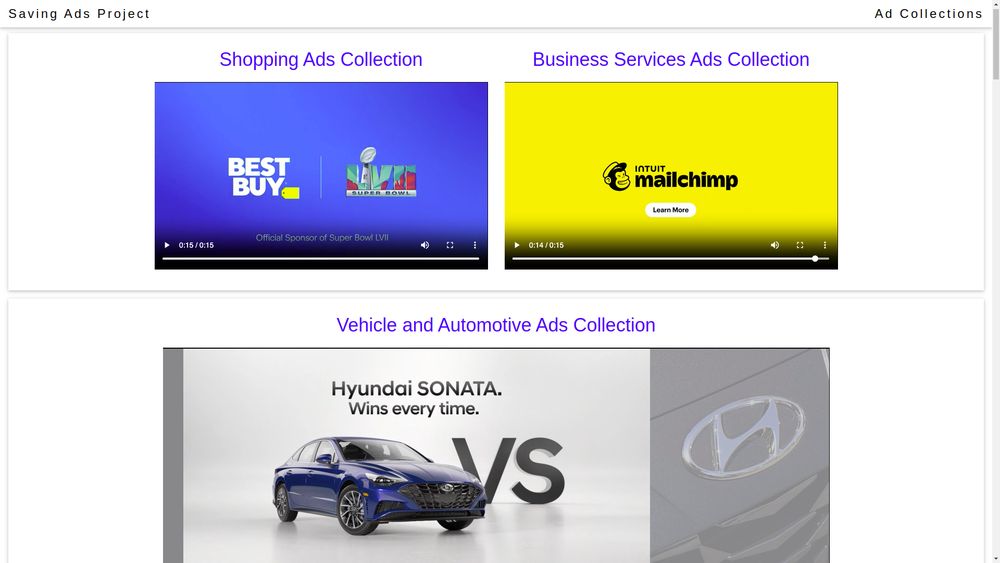
We also created a web page that allows us to view all of the information from the dataset including the replay of the archived ads:
savingads.github.io/themed_ad_co...
(5/7)
savingads.github.io/themed_ad_co...
(5/7)
February 12, 2025 at 8:58 PM
We also created a web page that allows us to view all of the information from the dataset including the replay of the archived ads:
savingads.github.io/themed_ad_co...
(5/7)
savingads.github.io/themed_ad_co...
(5/7)
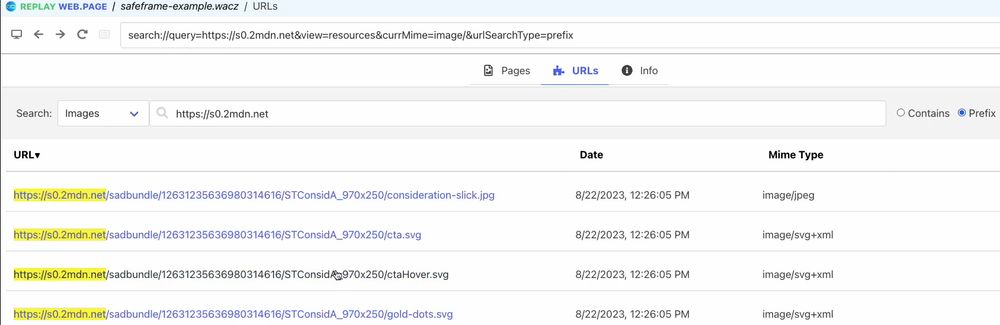
To identify ads that were not able to replay in the containing web page that loaded the ads during the crawling session, we used ReplayWeb.page’s URL search feature (replayweb.page/docs/user-guide/exploring/) and our Display Archived Ads tool (github.com/savingads/Display-Archived-Ads).
(4/7)
(4/7)

February 12, 2025 at 8:58 PM
To identify ads that were not able to replay in the containing web page that loaded the ads during the crawling session, we used ReplayWeb.page’s URL search feature (replayweb.page/docs/user-guide/exploring/) and our Display Archived Ads tool (github.com/savingads/Display-Archived-Ads).
(4/7)
(4/7)
When archiving these web pages, we utilized:
> Web archiving services
>> Internet Archive's Save Page Now
>> Arquivo.pt
>> archive.today
>> Conifer
> Browser-based tools
>> ArchiveWeb.page
>> Browsertrix Crawler
>> Brozzler
(3/7)
> Web archiving services
>> Internet Archive's Save Page Now
>> Arquivo.pt
>> archive.today
>> Conifer
> Browser-based tools
>> ArchiveWeb.page
>> Browsertrix Crawler
>> Brozzler
(3/7)
February 12, 2025 at 8:58 PM
When archiving these web pages, we utilized:
> Web archiving services
>> Internet Archive's Save Page Now
>> Arquivo.pt
>> archive.today
>> Conifer
> Browser-based tools
>> ArchiveWeb.page
>> Browsertrix Crawler
>> Brozzler
(3/7)
> Web archiving services
>> Internet Archive's Save Page Now
>> Arquivo.pt
>> archive.today
>> Conifer
> Browser-based tools
>> ArchiveWeb.page
>> Browsertrix Crawler
>> Brozzler
(3/7)
Our dataset of 279 ads was created by archiving 17 web pages from SimilarWeb's top websites worldwide.
Dataset: github.com/savingads/Re...
(2/7)
Dataset: github.com/savingads/Re...
(2/7)
github.com
February 12, 2025 at 8:58 PM
Our dataset of 279 ads was created by archiving 17 web pages from SimilarWeb's top websites worldwide.
Dataset: github.com/savingads/Re...
(2/7)
Dataset: github.com/savingads/Re...
(2/7)
We were able to create a dataset of 279 ads by archiving 17 web pages from SimilarWeb’s top websites worldwide.
Dataset of 279 archived ads: github.com/savingads/Re...
We also created a web page to display ads from our dataset: savingads.github.io/themed_ad_co...
(10/10)
Dataset of 279 archived ads: github.com/savingads/Re...
We also created a web page to display ads from our dataset: savingads.github.io/themed_ad_co...
(10/10)
February 6, 2025 at 4:27 AM
We were able to create a dataset of 279 ads by archiving 17 web pages from SimilarWeb’s top websites worldwide.
Dataset of 279 archived ads: github.com/savingads/Re...
We also created a web page to display ads from our dataset: savingads.github.io/themed_ad_co...
(10/10)
Dataset of 279 archived ads: github.com/savingads/Re...
We also created a web page to display ads from our dataset: savingads.github.io/themed_ad_co...
(10/10)
To identify ads that were not able to replay in the containing web page that loaded the ads during the crawling session, we used ReplayWeb.page’s URL search feature (replayweb.page/docs/user-guide/exploring) and our Display Archived Ads tool (github.com/savingads/Display-Archived-Ads).
(9/10)
(9/10)
February 6, 2025 at 4:27 AM
To identify ads that were not able to replay in the containing web page that loaded the ads during the crawling session, we used ReplayWeb.page’s URL search feature (replayweb.page/docs/user-guide/exploring) and our Display Archived Ads tool (github.com/savingads/Display-Archived-Ads).
(9/10)
(9/10)
5) Successful replay of ads loaded in iframes with the src attribute of "about:blank" depended upon a given browser's service worker implementation. A Chromium bug stopped service workers from accessing resources inside of this type of iframe, which prevented replay.
(8/10)
(8/10)

February 6, 2025 at 4:27 AM
5) Successful replay of ads loaded in iframes with the src attribute of "about:blank" depended upon a given browser's service worker implementation. A Chromium bug stopped service workers from accessing resources inside of this type of iframe, which prevented replay.
(8/10)
(8/10)
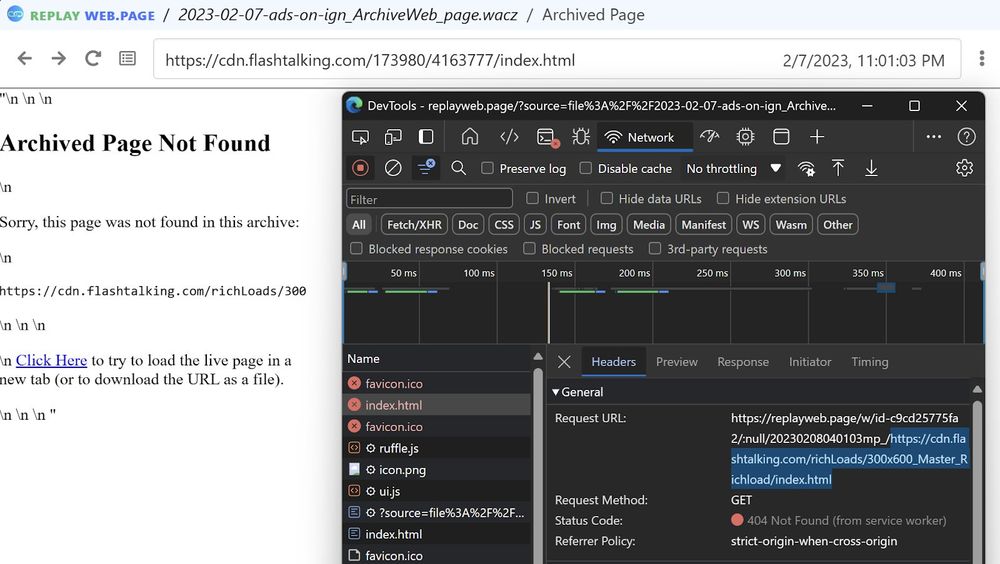
4) When loading Flashtalking web page ads outside of ad iframes, the ad script requested a non-existent URL, which prevented the replay of ad resources.
(7/10)
(7/10)
February 6, 2025 at 4:27 AM
4) When loading Flashtalking web page ads outside of ad iframes, the ad script requested a non-existent URL, which prevented the replay of ad resources.
(7/10)
(7/10)
We created an example web page that used ad code from Google’s pubads_impl_2023020201.js script to determine how the random values were generated for a Google SafeFrame.
Demo web page for generating random numbers and Google SafeFrames: treid003.github.io/random_Value...
(6/10)
Demo web page for generating random numbers and Google SafeFrames: treid003.github.io/random_Value...
(6/10)

February 6, 2025 at 4:27 AM
We created an example web page that used ad code from Google’s pubads_impl_2023020201.js script to determine how the random values were generated for a Google SafeFrame.
Demo web page for generating random numbers and Google SafeFrames: treid003.github.io/random_Value...
(6/10)
Demo web page for generating random numbers and Google SafeFrames: treid003.github.io/random_Value...
(6/10)
3) During crawling and replay sessions, Google's and Amazon's ad scripts generated URLs with different random values, because the random number generator’s seed is not the same during the crawl and replay sessions. This prevented archived ads' replay.
(5/10)
(5/10)




February 6, 2025 at 4:27 AM
3) During crawling and replay sessions, Google's and Amazon's ad scripts generated URLs with different random values, because the random number generator’s seed is not the same during the crawl and replay sessions. This prevented archived ads' replay.
(5/10)
(5/10)
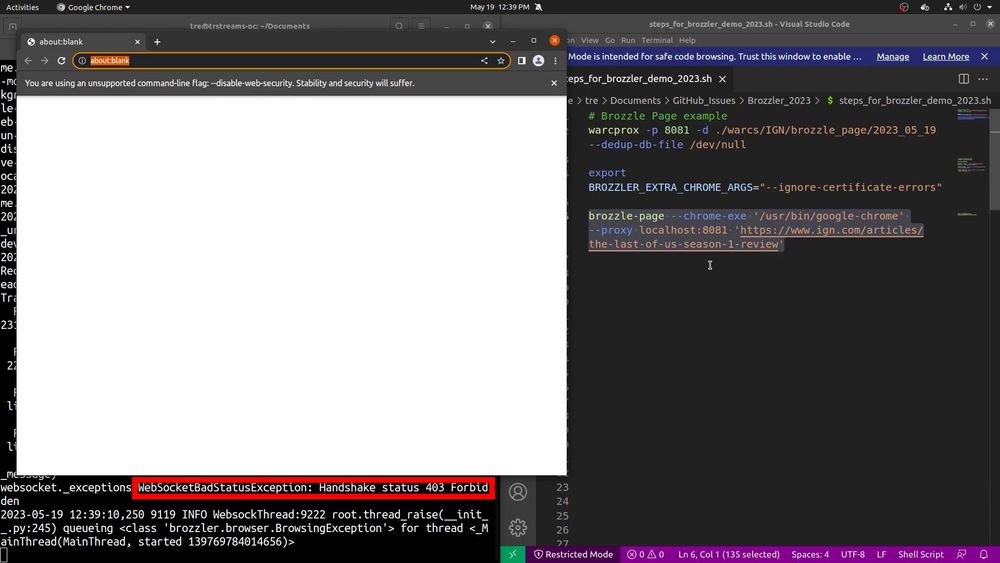
2) During 2023, Brozzler was incompatible with versions of Chrome released after version 111.0.5563.110, which prevented ads from being archived.
This thread describes the problem:
x.com/TReid803/sta...
(4/10)
This thread describes the problem:
x.com/TReid803/sta...
(4/10)
x.com
x.com
February 6, 2025 at 4:27 AM
2) During 2023, Brozzler was incompatible with versions of Chrome released after version 111.0.5563.110, which prevented ads from being archived.
This thread describes the problem:
x.com/TReid803/sta...
(4/10)
This thread describes the problem:
x.com/TReid803/sta...
(4/10)
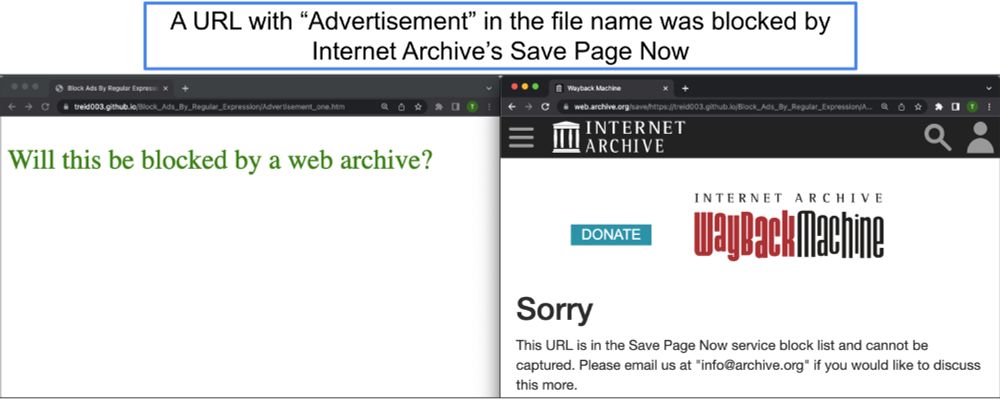
1) Before August 2023, Internet Archive's Save Page Now (SPN) excluded ad services' ads & URLs with ad related file and directory names. After August 2023, SPN still excluded ads loaded on a web page & only allowed ad resources if the user directly archived the ad's URL(s)
(3/10)
(3/10)

February 6, 2025 at 4:27 AM
1) Before August 2023, Internet Archive's Save Page Now (SPN) excluded ad services' ads & URLs with ad related file and directory names. After August 2023, SPN still excluded ads loaded on a web page & only allowed ad resources if the user directly archived the ad's URL(s)
(3/10)
(3/10)
Five problems with archiving & replaying ads during 2023:
1. IA's Save Page Now excluded ads
2. Brozzler's incompatibility with Chrome
3. Google & Amazon ad URLs with random values
4. Flashtalking ads requested unarchived URL
5. Replay of ads differed depending on browser
(2/10)
1. IA's Save Page Now excluded ads
2. Brozzler's incompatibility with Chrome
3. Google & Amazon ad URLs with random values
4. Flashtalking ads requested unarchived URL
5. Replay of ads differed depending on browser
(2/10)


February 6, 2025 at 4:27 AM
Five problems with archiving & replaying ads during 2023:
1. IA's Save Page Now excluded ads
2. Brozzler's incompatibility with Chrome
3. Google & Amazon ad URLs with random values
4. Flashtalking ads requested unarchived URL
5. Replay of ads differed depending on browser
(2/10)
1. IA's Save Page Now excluded ads
2. Brozzler's incompatibility with Chrome
3. Google & Amazon ad URLs with random values
4. Flashtalking ads requested unarchived URL
5. Replay of ads differed depending on browser
(2/10)