



Tom George
@tomnotgeorge.bsky.social
Neuroscience/ML PhD @UCL
• NeuroAI, navigation, hippocampus, ...
• Open-source software tools for science (https://github.com/RatInABox-Lab/RatInABox)
• Co-organiser of TReND CaMinA summer school
🔎👀 for a postdoc position…
• NeuroAI, navigation, hippocampus, ...
• Open-source software tools for science (https://github.com/RatInABox-Lab/RatInABox)
• Co-organiser of TReND CaMinA summer school
🔎👀 for a postdoc position…
Initialising at behaviour is a powerful trick here. In many regions (e.g., but not limited to, hippocampus 👀), a behavioural correlate (position👀) exists which is VERY CLOSE to the true latent. Starting right next to the global maxima help makes optimisation straightforward.

November 25, 2024 at 1:39 PM
Initialising at behaviour is a powerful trick here. In many regions (e.g., but not limited to, hippocampus 👀), a behavioural correlate (position👀) exists which is VERY CLOSE to the true latent. Starting right next to the global maxima help makes optimisation straightforward.
And there’s cool stuff in the optimised latent too. It mostly tracks behaviour (hippocampus is still mostly a cognitive map) but does occasional big jumps as though the animal is contemplating another location in the environment.
17/21
17/21

November 25, 2024 at 1:39 PM
And there’s cool stuff in the optimised latent too. It mostly tracks behaviour (hippocampus is still mostly a cognitive map) but does occasional big jumps as though the animal is contemplating another location in the environment.
17/21
17/21
It’s quite a sizeable effect. The median place cell has 23% more place fields...the median place field is 34% smaller and has a firing rate 45% higher. It’s hard to overstate this result…
14/21
14/21

November 25, 2024 at 1:39 PM
It’s quite a sizeable effect. The median place cell has 23% more place fields...the median place field is 34% smaller and has a firing rate 45% higher. It’s hard to overstate this result…
14/21
14/21
When applied to a similarly large (but now real) hippocampal dataset SIMPL optimises the tuning curves. “Real” place fields, it turns out, are much smaller, sharper, more numerous and more uniformly-distributed than previously thought.
13/21
13/21

November 25, 2024 at 1:39 PM
When applied to a similarly large (but now real) hippocampal dataset SIMPL optimises the tuning curves. “Real” place fields, it turns out, are much smaller, sharper, more numerous and more uniformly-distributed than previously thought.
13/21
13/21
SIMPL outperforms CEBRA — a contemporary, more general-purpose, neural-net-based technique — in terms of performance and compute-time. It’s over 30x faster. It also beats pi-VAE and GPLVM.
12/21
12/21

November 25, 2024 at 1:39 PM
SIMPL outperforms CEBRA — a contemporary, more general-purpose, neural-net-based technique — in terms of performance and compute-time. It’s over 30x faster. It also beats pi-VAE and GPLVM.
12/21
12/21
I think this gif explains it well. The animal is "thinking" of the green location but located at the yellow. Spikes plotted against green give sharp grid fields but against yellow are blurred.
In the brain this discrepancy will be caused by replay, planning, uncertainty and more.
In the brain this discrepancy will be caused by replay, planning, uncertainty and more.

November 25, 2024 at 1:39 PM
I think this gif explains it well. The animal is "thinking" of the green location but located at the yellow. Spikes plotted against green give sharp grid fields but against yellow are blurred.
In the brain this discrepancy will be caused by replay, planning, uncertainty and more.
In the brain this discrepancy will be caused by replay, planning, uncertainty and more.
In order to know the “true” tuning curves we need to know the “true” latent which passed through those curves to generate spikes. i.e. what was the animal thinking of…not what was the animal doing. This latent, of course, is often close to a behavioural readout such as position

November 25, 2024 at 1:39 PM
In order to know the “true” tuning curves we need to know the “true” latent which passed through those curves to generate spikes. i.e. what was the animal thinking of…not what was the animal doing. This latent, of course, is often close to a behavioural readout such as position
SIMPL is also "identifiable", returning not just any tuning curves but specifically THE tuning curves which generated the data (there are some caveats / subtleties here)
6/21
6/21

November 25, 2024 at 1:39 PM
SIMPL is also "identifiable", returning not just any tuning curves but specifically THE tuning curves which generated the data (there are some caveats / subtleties here)
6/21
6/21
This works because it’s really just expectation maximisation (EM) — a well known algo for optimising models with hidden latents — with some faff removed. We show how, under relatively weak assumptions, repeated redecoding (SIMPL) is the same thing.
4/21
4/21

November 25, 2024 at 1:39 PM
This works because it’s really just expectation maximisation (EM) — a well known algo for optimising models with hidden latents — with some faff removed. We show how, under relatively weak assumptions, repeated redecoding (SIMPL) is the same thing.
4/21
4/21
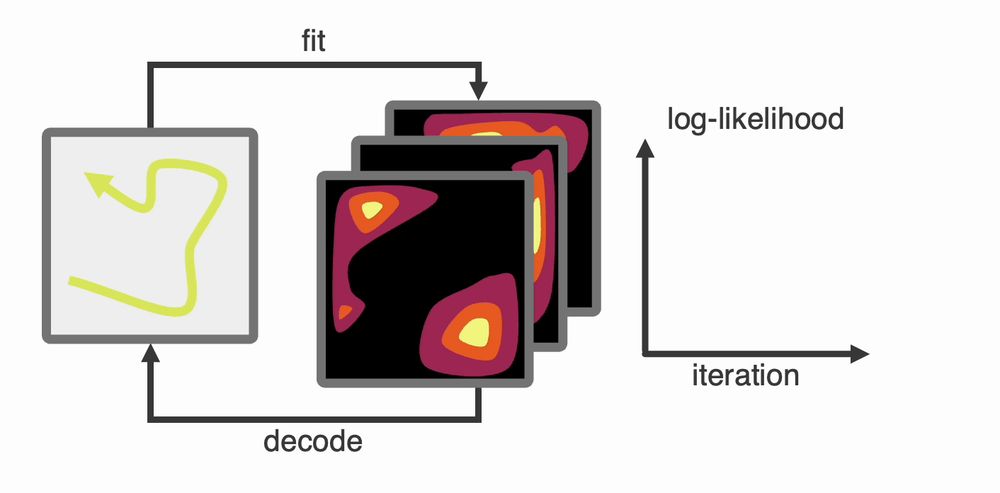
TL;DR
1. Start by assuming the latent IS behaviour (e.g. the animals position) …
2. ...fit tuning curves to this latent…
3. …re-decode the latent from these tuning curves…
4. …repeat steps 2 and 3
You will, very quickly, converge on the “true” latent space.
1. Start by assuming the latent IS behaviour (e.g. the animals position) …
2. ...fit tuning curves to this latent…
3. …re-decode the latent from these tuning curves…
4. …repeat steps 2 and 3
You will, very quickly, converge on the “true” latent space.
November 25, 2024 at 1:39 PM
TL;DR
1. Start by assuming the latent IS behaviour (e.g. the animals position) …
2. ...fit tuning curves to this latent…
3. …re-decode the latent from these tuning curves…
4. …repeat steps 2 and 3
You will, very quickly, converge on the “true” latent space.
1. Start by assuming the latent IS behaviour (e.g. the animals position) …
2. ...fit tuning curves to this latent…
3. …re-decode the latent from these tuning curves…
4. …repeat steps 2 and 3
You will, very quickly, converge on the “true” latent space.
All details, links, code etc. can be found here: tomge.org/papers/simpl/
And a huge shout out to my amazing collaborators
Pierre Glaser as well as @clopathlab.bsky.social, Kim Stachenfeld and @caswell.bsky.social !
2/21
And a huge shout out to my amazing collaborators
Pierre Glaser as well as @clopathlab.bsky.social, Kim Stachenfeld and @caswell.bsky.social !
2/21

November 25, 2024 at 1:39 PM
All details, links, code etc. can be found here: tomge.org/papers/simpl/
And a huge shout out to my amazing collaborators
Pierre Glaser as well as @clopathlab.bsky.social, Kim Stachenfeld and @caswell.bsky.social !
2/21
And a huge shout out to my amazing collaborators
Pierre Glaser as well as @clopathlab.bsky.social, Kim Stachenfeld and @caswell.bsky.social !
2/21
What are the brain’s “real” tuning curves?
Our new preprint "SIMPL: Scalable and hassle-free optimisation of neural representations from behaviour” argues that existing techniques for latent variable discovery are lacking.
We suggest a much simpl-er way to do things.
1/21🧵
Our new preprint "SIMPL: Scalable and hassle-free optimisation of neural representations from behaviour” argues that existing techniques for latent variable discovery are lacking.
We suggest a much simpl-er way to do things.
1/21🧵
November 25, 2024 at 1:39 PM
What are the brain’s “real” tuning curves?
Our new preprint "SIMPL: Scalable and hassle-free optimisation of neural representations from behaviour” argues that existing techniques for latent variable discovery are lacking.
We suggest a much simpl-er way to do things.
1/21🧵
Our new preprint "SIMPL: Scalable and hassle-free optimisation of neural representations from behaviour” argues that existing techniques for latent variable discovery are lacking.
We suggest a much simpl-er way to do things.
1/21🧵