



@timyphan.bsky.social
Reposted

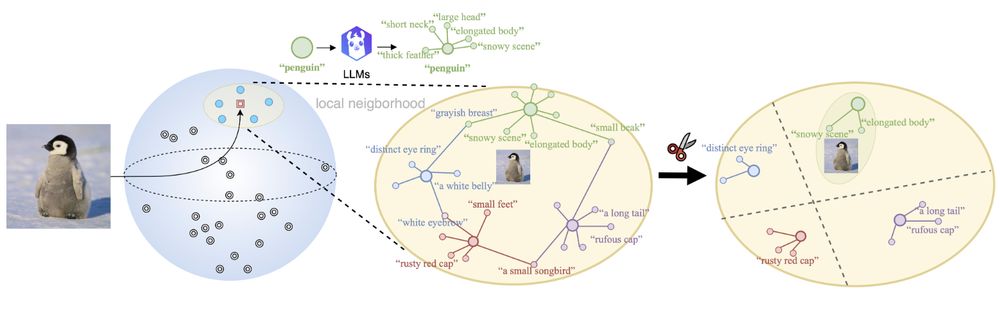
🤔When combining Vision-language models (VLMs) with Large language models (LLMs), do VLMs benefit from additional genuine semantics or artificial augmentations of the text for downstream tasks?
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
January 8, 2025 at 3:54 PM
🤔When combining Vision-language models (VLMs) with Large language models (LLMs), do VLMs benefit from additional genuine semantics or artificial augmentations of the text for downstream tasks?
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
Reposted

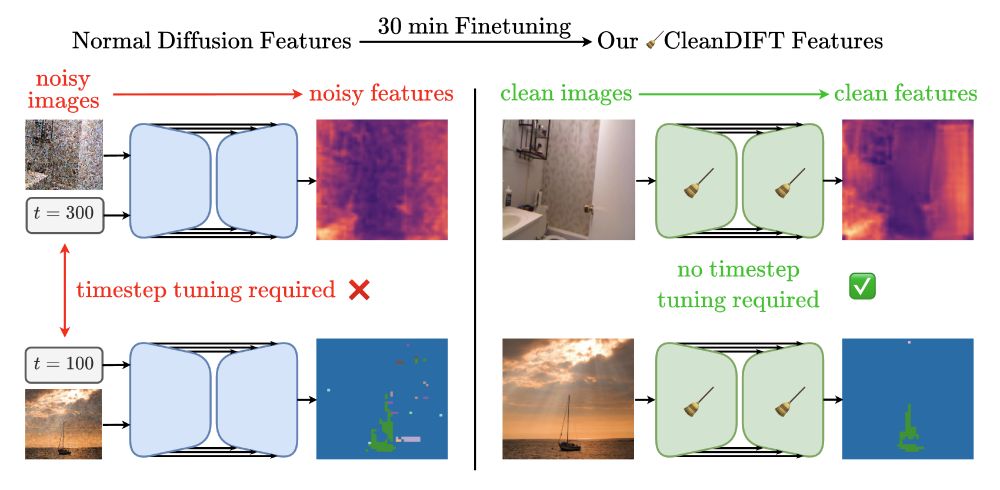
🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
December 4, 2024 at 11:31 PM
🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇