



Tim Kellogg
@timkellogg.me
AI Architect | North Carolina | AI/ML, IoT, science
WARNING: I talk about kids sometimes
WARNING: I talk about kids sometimes
is this where Google overtakes OpenAI?
November 11, 2025 at 10:46 PM
is this where Google overtakes OpenAI?
New York governor’s open letter to AI companies operating in the state

November 11, 2025 at 9:12 PM
New York governor’s open letter to AI companies operating in the state
interesting paper
imo if base models perform the same at high pass@k, then RLVR is just making them better *agents*, bc the reduced error rate translates to long agent trajectories
so while there is limits to RLVR, it’s clearly necessary
limit-of-rlvr.github.io
imo if base models perform the same at high pass@k, then RLVR is just making them better *agents*, bc the reduced error rate translates to long agent trajectories
so while there is limits to RLVR, it’s clearly necessary
limit-of-rlvr.github.io

November 11, 2025 at 2:12 PM
interesting paper
imo if base models perform the same at high pass@k, then RLVR is just making them better *agents*, bc the reduced error rate translates to long agent trajectories
so while there is limits to RLVR, it’s clearly necessary
limit-of-rlvr.github.io
imo if base models perform the same at high pass@k, then RLVR is just making them better *agents*, bc the reduced error rate translates to long agent trajectories
so while there is limits to RLVR, it’s clearly necessary
limit-of-rlvr.github.io
oh! teor likes it! congrats “Alexander” @dorialexander.bsky.social 🤣

November 11, 2025 at 12:17 PM
oh! teor likes it! congrats “Alexander” @dorialexander.bsky.social 🤣
chat, what are we thinking: quantization or batch size?

November 11, 2025 at 12:15 PM
chat, what are we thinking: quantization or batch size?

while being the most French model yet, they had to rationalize why it wasn’t trained on French
but fr imagine being able to do ablations on THE ENTIRE end-to-end training process. you’d learn so much
but fr imagine being able to do ablations on THE ENTIRE end-to-end training process. you’d learn so much

November 11, 2025 at 2:36 AM
while being the most French model yet, they had to rationalize why it wasn’t trained on French
but fr imagine being able to do ablations on THE ENTIRE end-to-end training process. you’d learn so much
but fr imagine being able to do ablations on THE ENTIRE end-to-end training process. you’d learn so much
sent this to my brother asking, “does this count as wealth redistribution?”
(fun fact: my bro voted for Trump and is also undergoing collapse of the company he’s CEO of due to tariffs)
(fun fact: my bro voted for Trump and is also undergoing collapse of the company he’s CEO of due to tariffs)
November 9, 2025 at 9:36 PM
sent this to my brother asking, “does this count as wealth redistribution?”
(fun fact: my bro voted for Trump and is also undergoing collapse of the company he’s CEO of due to tariffs)
(fun fact: my bro voted for Trump and is also undergoing collapse of the company he’s CEO of due to tariffs)
The town of German, NY elected 2 positions on write-in ballots alone
1. Superintendent of Highways
2. Town Justice
apparently no one ran
1. Superintendent of Highways
2. Town Justice
apparently no one ran

November 9, 2025 at 9:06 PM
The town of German, NY elected 2 positions on write-in ballots alone
1. Superintendent of Highways
2. Town Justice
apparently no one ran
1. Superintendent of Highways
2. Town Justice
apparently no one ran
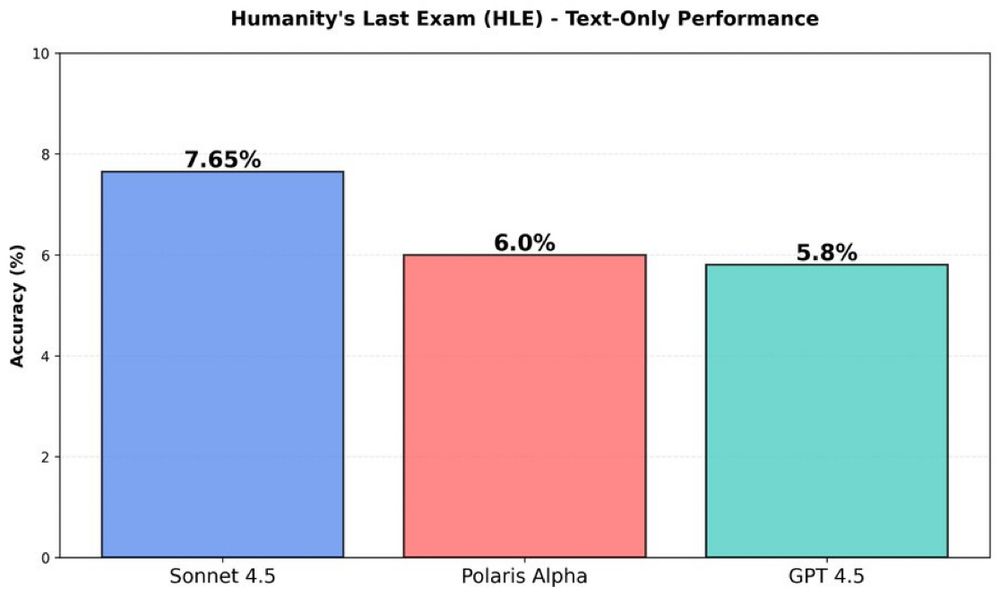
Polaris Alpha, believed to be GPT-5.1 non-reasoning, scores just below Sonnet 4.5 on HLE (unofficial run)
There will be a reasoning version too, and OpenAI excels at RL & post training, so I have high expectations for it
also leaked: Nov 24 release date
There will be a reasoning version too, and OpenAI excels at RL & post training, so I have high expectations for it
also leaked: Nov 24 release date
November 9, 2025 at 2:18 PM
Polaris Alpha, believed to be GPT-5.1 non-reasoning, scores just below Sonnet 4.5 on HLE (unofficial run)
There will be a reasoning version too, and OpenAI excels at RL & post training, so I have high expectations for it
also leaked: Nov 24 release date
There will be a reasoning version too, and OpenAI excels at RL & post training, so I have high expectations for it
also leaked: Nov 24 release date
idk is a 50 year mortgage even worth it?

November 8, 2025 at 10:45 PM
idk is a 50 year mortgage even worth it?

GPT-5-codex-mini
Almost same performance as GPT-5-codex on high, but 4x faster and without pesky things like warm personality
www.neowin.net/amp/openai-i...
Almost same performance as GPT-5-codex on high, but 4x faster and without pesky things like warm personality
www.neowin.net/amp/openai-i...

November 8, 2025 at 4:46 PM
GPT-5-codex-mini
Almost same performance as GPT-5-codex on high, but 4x faster and without pesky things like warm personality
www.neowin.net/amp/openai-i...
Almost same performance as GPT-5-codex on high, but 4x faster and without pesky things like warm personality
www.neowin.net/amp/openai-i...
“nah, we don’t do 996”
November 8, 2025 at 12:49 PM
“nah, we don’t do 996”
this morning, X is saturated with people from US claiming that their favorite unknown benchmark (that happens to show K2 trailing US models) is actually the best single benchmark to watch
lol notice how they clipped off the top 12
lol notice how they clipped off the top 12

November 8, 2025 at 12:10 PM
this morning, X is saturated with people from US claiming that their favorite unknown benchmark (that happens to show K2 trailing US models) is actually the best single benchmark to watch
lol notice how they clipped off the top 12
lol notice how they clipped off the top 12


K2-Thinking is available in the Kimi app now

November 7, 2025 at 7:29 PM
K2-Thinking is available in the Kimi app now

November 7, 2025 at 6:35 PM
GPT-5.1 is live on OpenRouter via stealth preview

November 7, 2025 at 4:15 PM
GPT-5.1 is live on OpenRouter via stealth preview
i haven’t figured out how to use it, but apparently Kimi K2-Thinking has a Heavy mode with 8 parallel trajectories that are reflectively aggregated
it does better than GPT-5-pro on HLE
it does better than GPT-5-pro on HLE

November 7, 2025 at 4:04 PM
i haven’t figured out how to use it, but apparently Kimi K2-Thinking has a Heavy mode with 8 parallel trajectories that are reflectively aggregated
it does better than GPT-5-pro on HLE
it does better than GPT-5-pro on HLE
K2-Thinking is SOTA, top model in agentic tool calling

November 7, 2025 at 10:40 AM
K2-Thinking is SOTA, top model in agentic tool calling
this really highlights how LLMs do math
math is a string of many operations, so one small error (e.g. a misremembered shortcut) causes cascading calculation errors downstream
math is a string of many operations, so one small error (e.g. a misremembered shortcut) causes cascading calculation errors downstream

November 7, 2025 at 1:02 AM
this really highlights how LLMs do math
math is a string of many operations, so one small error (e.g. a misremembered shortcut) causes cascading calculation errors downstream
math is a string of many operations, so one small error (e.g. a misremembered shortcut) causes cascading calculation errors downstream
Surprising: Math requires a lot of memorization
Goodfire is at it again!
They developed a method similar to PCA that measures how much of an LLM’s weights are dedicated to memorization
www.goodfire.ai/research/und...
Goodfire is at it again!
They developed a method similar to PCA that measures how much of an LLM’s weights are dedicated to memorization
www.goodfire.ai/research/und...

November 7, 2025 at 1:02 AM
Surprising: Math requires a lot of memorization
Goodfire is at it again!
They developed a method similar to PCA that measures how much of an LLM’s weights are dedicated to memorization
www.goodfire.ai/research/und...
Goodfire is at it again!
They developed a method similar to PCA that measures how much of an LLM’s weights are dedicated to memorization
www.goodfire.ai/research/und...
notable: they ripped out the silicon that supports training
they say: “it’s the age of inference”
which, yeah, RL is mostly inference. Continual learning is almost all inference. Ambient agents, fast growing inference demands in general audiences
kartik343.wixstudio.com/blogorithm/p...
they say: “it’s the age of inference”
which, yeah, RL is mostly inference. Continual learning is almost all inference. Ambient agents, fast growing inference demands in general audiences
kartik343.wixstudio.com/blogorithm/p...

November 7, 2025 at 12:43 AM
notable: they ripped out the silicon that supports training
they say: “it’s the age of inference”
which, yeah, RL is mostly inference. Continual learning is almost all inference. Ambient agents, fast growing inference demands in general audiences
kartik343.wixstudio.com/blogorithm/p...
they say: “it’s the age of inference”
which, yeah, RL is mostly inference. Continual learning is almost all inference. Ambient agents, fast growing inference demands in general audiences
kartik343.wixstudio.com/blogorithm/p...