



Thibaut Boissin
@thib-s.bsky.social
I used a mathematical trick to pre-condition the matrix, allowing to shave one iteration of the algorithm. This is not only faster, but also unlocks better convergence, with singular values closer to 1.

September 21, 2025 at 8:06 PM
I used a mathematical trick to pre-condition the matrix, allowing to shave one iteration of the algorithm. This is not only faster, but also unlocks better convergence, with singular values closer to 1.
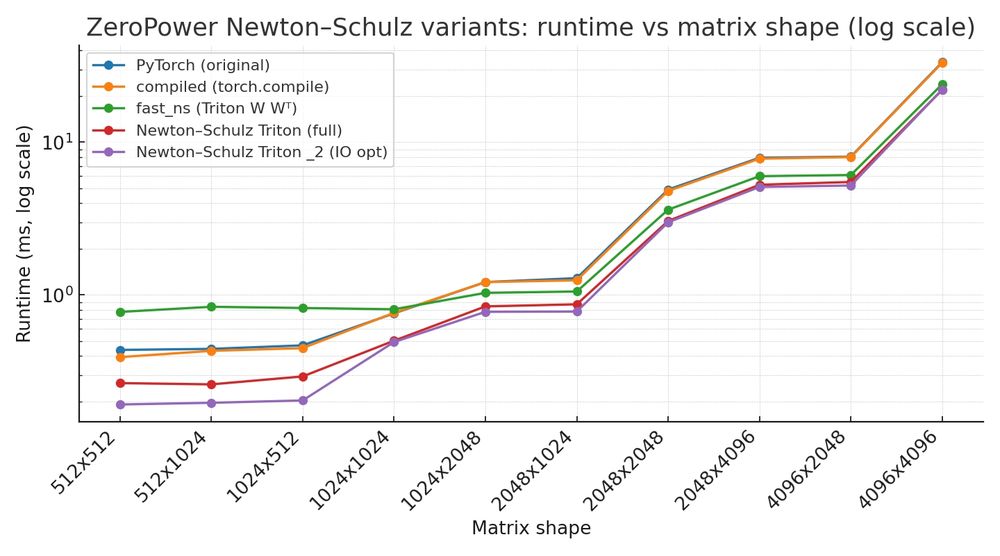
Good news: I managed to get an extra 1.6x speedup of the Newton Schulz algorithm (which is at the core of Dion/Muon). It reaches nearly a 3x speedup over the plain torch implementation !

September 21, 2025 at 8:06 PM
Good news: I managed to get an extra 1.6x speedup of the Newton Schulz algorithm (which is at the core of Dion/Muon). It reaches nearly a 3x speedup over the plain torch implementation !
Sharing my journey to learn triton: still wip but io optimization yields some decent runtime improvement (around 25% on 512x512) on Newton Schulz (as used in Dion/Muon).
August 10, 2025 at 10:15 AM
Sharing my journey to learn triton: still wip but io optimization yields some decent runtime improvement (around 25% on 512x512) on Newton Schulz (as used in Dion/Muon).
My journey with Triton

August 7, 2025 at 10:00 AM
My journey with Triton
This has deeper implications: two networks with different initialization, batch order, or data augmentation end up learning the same function (same answers, same errors, both in train and val), even though the weights are completely different!

July 25, 2025 at 7:44 PM
This has deeper implications: two networks with different initialization, batch order, or data augmentation end up learning the same function (same answers, same errors, both in train and val), even though the weights are completely different!
The change in the Lipschitz constant makes the network more accurate (when increased) or more robust (when decreased). Unlike traditional classification, robust classification with a Lipschitz net has a unique minimizer once the Lipschitz constant is set.

July 25, 2025 at 7:44 PM
The change in the Lipschitz constant makes the network more accurate (when increased) or more robust (when decreased). Unlike traditional classification, robust classification with a Lipschitz net has a unique minimizer once the Lipschitz constant is set.
The Lipschitz constant of a network impacts its robustness, but what happens when you change it during training? Here, we train 16 networks with a fixed Lipschitz constant at first, then increase or decrease it by a factor of two mid-training.

July 25, 2025 at 7:44 PM
The Lipschitz constant of a network impacts its robustness, but what happens when you change it during training? Here, we train 16 networks with a fixed Lipschitz constant at first, then increase or decrease it by a factor of two mid-training.
Beyond robustness: Lipschitz networks = stability.
Different inits, different seeds, different weights—same function.
A thread 🧵
Different inits, different seeds, different weights—same function.
A thread 🧵

July 25, 2025 at 7:44 PM
Beyond robustness: Lipschitz networks = stability.
Different inits, different seeds, different weights—same function.
A thread 🧵
Different inits, different seeds, different weights—same function.
A thread 🧵
Some bad, but creative, training losses 👌

June 10, 2025 at 9:55 PM
Some bad, but creative, training losses 👌