



Vladan Stojnić
@stojnicv.xyz
Ph.D. student at Visual Recognition Group, Czech Technical University in Prague
🔗 https://stojnicv.xyz
🔗 https://stojnicv.xyz
Are you at @iccv.bsky.social #ICCV2025? Come by our poster.
📅 October 22, 2025, 14:30 – 16:30 HST
📍 Location: Exhibit Hall I, Poster #207
📅 October 22, 2025, 14:30 – 16:30 HST
📍 Location: Exhibit Hall I, Poster #207

October 21, 2025 at 6:15 PM
Are you at @iccv.bsky.social #ICCV2025? Come by our poster.
📅 October 22, 2025, 14:30 – 16:30 HST
📍 Location: Exhibit Hall I, Poster #207
📅 October 22, 2025, 14:30 – 16:30 HST
📍 Location: Exhibit Hall I, Poster #207
I agree that the terminology is confusing. However, I wouldn't agree that CLIP is an SSL method. It uses a contrastive loss, but not with self-supervised labels. DINOv2 and v3 classify it as weakly-supervised as it uses labels coming from the text.


August 18, 2025 at 3:05 PM
I agree that the terminology is confusing. However, I wouldn't agree that CLIP is an SSL method. It uses a contrastive loss, but not with self-supervised labels. DINOv2 and v3 classify it as weakly-supervised as it uses labels coming from the text.
The same pattern can be observed for the acquisition parameters in the task of near-duplicate retrieval. If the negatives are captured using the same camera as the query, the task becomes harder for some models compared to the case when they are captured by a different camera.

August 18, 2025 at 10:48 AM
The same pattern can be observed for the acquisition parameters in the task of near-duplicate retrieval. If the negatives are captured using the same camera as the query, the task becomes harder for some models compared to the case when they are captured by a different camera.
Impact on the semantic performance is again the most pronounced for contrastive VLMs, and the least for SSL models.
Here, we show kNN classification in a few cases, depending on whether the semantic positives and negatives share the same processing parameters as the test image.
Here, we show kNN classification in a few cases, depending on whether the semantic positives and negatives share the same processing parameters as the test image.

August 18, 2025 at 10:48 AM
Impact on the semantic performance is again the most pronounced for contrastive VLMs, and the least for SSL models.
Here, we show kNN classification in a few cases, depending on whether the semantic positives and negatives share the same processing parameters as the test image.
Here, we show kNN classification in a few cases, depending on whether the semantic positives and negatives share the same processing parameters as the test image.
This impact is especially pronounced when there is a strong correlation/anticorrelation between the semantic and metadata labels. E.g., when semantic positives/negatives have the same/different processing parameters as a query image.

August 18, 2025 at 10:48 AM
This impact is especially pronounced when there is a strong correlation/anticorrelation between the semantic and metadata labels. E.g., when semantic positives/negatives have the same/different processing parameters as a query image.
More strikingly, we show that traces of these metadata labels (processing and acquisition parameters) can significantly impact the semantic recognition abilities.

August 18, 2025 at 10:48 AM
More strikingly, we show that traces of these metadata labels (processing and acquisition parameters) can significantly impact the semantic recognition abilities.
A similar pattern is observed for the acquisition parameters, although generally, all models have a harder time predicting these parameters than the processing ones.

August 18, 2025 at 10:48 AM
A similar pattern is observed for the acquisition parameters, although generally, all models have a harder time predicting these parameters than the processing ones.
Image processing parameters can be recovered from the representations of frozen models by training a linear layer on top. This ability is especially pronounced for contrastive VLMs (e.g., CLIP). Some supervised models perform strongly as well, while SSL models perform the worst.

August 18, 2025 at 10:48 AM
Image processing parameters can be recovered from the representations of frozen models by training a linear layer on top. This ability is especially pronounced for contrastive VLMs (e.g., CLIP). Some supervised models perform strongly as well, while SSL models perform the worst.
Have you ever asked yourself how much your favorite vision model knows about image capture parameters (e.g., the amount of JPEG compression, the camera model, etc.)? Furthermore, could these parameters influence its semantic recognition abilities?

August 18, 2025 at 10:48 AM
Have you ever asked yourself how much your favorite vision model knows about image capture parameters (e.g., the amount of JPEG compression, the camera model, etc.)? Furthermore, could these parameters influence its semantic recognition abilities?
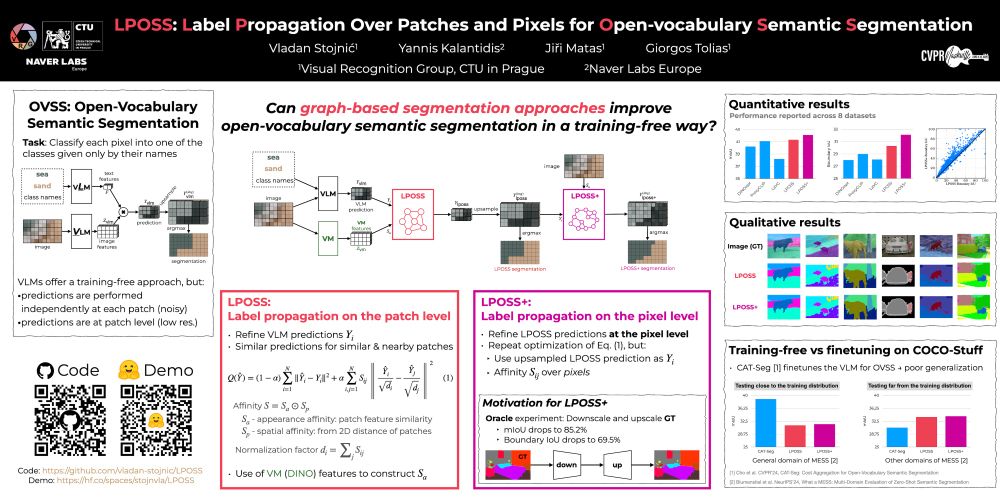
Are you at @cvprconference.bsky.social #CVPR2025 ? Come and check out LPOSS.
We show how can graph-based label propagation be used to improve weak, patch-level predictions from VLMs for open-vocabulary semantic segmentation.
📅 June 13, 2025, 16:00 – 18:00 CDT
📍 Location: ExHall D, Poster #421
We show how can graph-based label propagation be used to improve weak, patch-level predictions from VLMs for open-vocabulary semantic segmentation.
📅 June 13, 2025, 16:00 – 18:00 CDT
📍 Location: ExHall D, Poster #421
June 13, 2025 at 12:03 PM
Are you at @cvprconference.bsky.social #CVPR2025 ? Come and check out LPOSS.
We show how can graph-based label propagation be used to improve weak, patch-level predictions from VLMs for open-vocabulary semantic segmentation.
📅 June 13, 2025, 16:00 – 18:00 CDT
📍 Location: ExHall D, Poster #421
We show how can graph-based label propagation be used to improve weak, patch-level predictions from VLMs for open-vocabulary semantic segmentation.
📅 June 13, 2025, 16:00 – 18:00 CDT
📍 Location: ExHall D, Poster #421
I agree. However, be careful especially if you go to higher downsampling factors. Those numbers are a bit too optimistic, as it can be very dataset dependent. They were reported on PASCAL which mostly has images with one/two objects on the background.

April 14, 2025 at 11:54 AM
I agree. However, be careful especially if you go to higher downsampling factors. Those numbers are a bit too optimistic, as it can be very dataset dependent. They were reported on PASCAL which mostly has images with one/two objects on the background.

March 27, 2025 at 2:02 PM
They obtain especially strong performance around object boundaries as measured by the Boundary IoU metric.

March 27, 2025 at 2:02 PM
They obtain especially strong performance around object boundaries as measured by the Boundary IoU metric.
LPOSS and LPOSS+ obtain a strong performance across a wide range of different benchmarks in terms of the commonly used mIoU metric.

March 27, 2025 at 2:02 PM
LPOSS and LPOSS+ obtain a strong performance across a wide range of different benchmarks in terms of the commonly used mIoU metric.
LPOSS and LPOSS+, perform inference over the entire image, avoiding window-based processing and thereby capturing contextual interactions across the full image.

March 27, 2025 at 2:02 PM
LPOSS and LPOSS+, perform inference over the entire image, avoiding window-based processing and thereby capturing contextual interactions across the full image.
We are happy to share LPOSS: Label Propagation Over Patches and Pixels for Open-vocabulary Semantic Segmentation.
LPOSS is a training-free method for open-vocabulary semantic segmentation using Vision-Language Models.
LPOSS is a training-free method for open-vocabulary semantic segmentation using Vision-Language Models.

March 27, 2025 at 2:02 PM
We are happy to share LPOSS: Label Propagation Over Patches and Pixels for Open-vocabulary Semantic Segmentation.
LPOSS is a training-free method for open-vocabulary semantic segmentation using Vision-Language Models.
LPOSS is a training-free method for open-vocabulary semantic segmentation using Vision-Language Models.
SigLIP could be an interesting choice. However, note that in ILIAS we observe that DINOv2 mostly outperforms SigLIP on landmarks, which is probably our closest category to images in localization

February 26, 2025 at 6:06 PM
SigLIP could be an interesting choice. However, note that in ILIAS we observe that DINOv2 mostly outperforms SigLIP on landmarks, which is probably our closest category to images in localization