



Stella Li
@stellali.bsky.social
PhD student @uwnlp.bsky.social @uwcse.bsky.social | visiting researcher @MetaAI | previously @jhuclsp.bsky.social
https://stellalisy.com
https://stellalisy.com
🔍More importantly‼️we can see WHY preferences differ:
r/AskHistorians:📚values verbosity
r/RoastMe:💥values directness
r/confession:❤️values empathy
We visualize each group’s unique preference decisions—no more one-size-fits-all. Understand your audience at a glance🏷️
r/AskHistorians:📚values verbosity
r/RoastMe:💥values directness
r/confession:❤️values empathy
We visualize each group’s unique preference decisions—no more one-size-fits-all. Understand your audience at a glance🏷️

July 22, 2025 at 2:59 PM
🔍More importantly‼️we can see WHY preferences differ:
r/AskHistorians:📚values verbosity
r/RoastMe:💥values directness
r/confession:❤️values empathy
We visualize each group’s unique preference decisions—no more one-size-fits-all. Understand your audience at a glance🏷️
r/AskHistorians:📚values verbosity
r/RoastMe:💥values directness
r/confession:❤️values empathy
We visualize each group’s unique preference decisions—no more one-size-fits-all. Understand your audience at a glance🏷️
🏆Results across 45 Reddit communities:
📈Performance boost: +46.6% vs GPT-4o
💪Outperforms other training-based baselines w/ statistical significance
🕰️Robust to temporal shifts—trained pref models can be used out-of-the box!
📈Performance boost: +46.6% vs GPT-4o
💪Outperforms other training-based baselines w/ statistical significance
🕰️Robust to temporal shifts—trained pref models can be used out-of-the box!

July 22, 2025 at 2:59 PM
🏆Results across 45 Reddit communities:
📈Performance boost: +46.6% vs GPT-4o
💪Outperforms other training-based baselines w/ statistical significance
🕰️Robust to temporal shifts—trained pref models can be used out-of-the box!
📈Performance boost: +46.6% vs GPT-4o
💪Outperforms other training-based baselines w/ statistical significance
🕰️Robust to temporal shifts—trained pref models can be used out-of-the box!
⚙️How it works (pt.2)
1: 🎛️Train compact, efficient detectors for every attribute
2: 🎯Learn community-specific attribute weights during preference training
3: 🔧Add attribute embeddings to preference model for accurate & explainable predictions
1: 🎛️Train compact, efficient detectors for every attribute
2: 🎯Learn community-specific attribute weights during preference training
3: 🔧Add attribute embeddings to preference model for accurate & explainable predictions

July 22, 2025 at 2:59 PM
⚙️How it works (pt.2)
1: 🎛️Train compact, efficient detectors for every attribute
2: 🎯Learn community-specific attribute weights during preference training
3: 🔧Add attribute embeddings to preference model for accurate & explainable predictions
1: 🎛️Train compact, efficient detectors for every attribute
2: 🎯Learn community-specific attribute weights during preference training
3: 🔧Add attribute embeddings to preference model for accurate & explainable predictions
⚙️How it works (prep stage)
📜Define 19 sociolinguistics & cultural attributes from literature
🏭Novel preference data generation pipeline to isolate attributes
Our data gen pipeline generates pairwise data on *any* decomposed dimension, w/ applications beyond preference modeling
📜Define 19 sociolinguistics & cultural attributes from literature
🏭Novel preference data generation pipeline to isolate attributes
Our data gen pipeline generates pairwise data on *any* decomposed dimension, w/ applications beyond preference modeling

July 22, 2025 at 2:59 PM
⚙️How it works (prep stage)
📜Define 19 sociolinguistics & cultural attributes from literature
🏭Novel preference data generation pipeline to isolate attributes
Our data gen pipeline generates pairwise data on *any* decomposed dimension, w/ applications beyond preference modeling
📜Define 19 sociolinguistics & cultural attributes from literature
🏭Novel preference data generation pipeline to isolate attributes
Our data gen pipeline generates pairwise data on *any* decomposed dimension, w/ applications beyond preference modeling
Meet PrefPalette🎨! Our approach:
🔍⚖️models preferences w/ 19 attribute detectors and dynamic, context-aware weights
🕶️👍uses unobtrusive signals from Reddit to avoid response bias
🧠mirrors attribute-mediated human judgment—so you know not just what it predicts, but *why*🧐
🔍⚖️models preferences w/ 19 attribute detectors and dynamic, context-aware weights
🕶️👍uses unobtrusive signals from Reddit to avoid response bias
🧠mirrors attribute-mediated human judgment—so you know not just what it predicts, but *why*🧐

July 22, 2025 at 2:59 PM
Meet PrefPalette🎨! Our approach:
🔍⚖️models preferences w/ 19 attribute detectors and dynamic, context-aware weights
🕶️👍uses unobtrusive signals from Reddit to avoid response bias
🧠mirrors attribute-mediated human judgment—so you know not just what it predicts, but *why*🧐
🔍⚖️models preferences w/ 19 attribute detectors and dynamic, context-aware weights
🕶️👍uses unobtrusive signals from Reddit to avoid response bias
🧠mirrors attribute-mediated human judgment—so you know not just what it predicts, but *why*🧐
WHY do you prefer something over another?
Reward models treat preference as a black-box😶🌫️but human brains🧠decompose decisions into hidden attributes
We built the first system to mirror how people really make decisions in our recent COLM paper🎨PrefPalette✨
Why it matters👉🏻🧵
Reward models treat preference as a black-box😶🌫️but human brains🧠decompose decisions into hidden attributes
We built the first system to mirror how people really make decisions in our recent COLM paper🎨PrefPalette✨
Why it matters👉🏻🧵

July 22, 2025 at 2:59 PM
WHY do you prefer something over another?
Reward models treat preference as a black-box😶🌫️but human brains🧠decompose decisions into hidden attributes
We built the first system to mirror how people really make decisions in our recent COLM paper🎨PrefPalette✨
Why it matters👉🏻🧵
Reward models treat preference as a black-box😶🌫️but human brains🧠decompose decisions into hidden attributes
We built the first system to mirror how people really make decisions in our recent COLM paper🎨PrefPalette✨
Why it matters👉🏻🧵
🌟 Impressive Generalization!
ALFA-trained models maintain strong performance even on completely new interactive medical tasks (MediQ-MedQA).
highlighting ALFA’s potential for broader applicability in real-world clinical scenarios‼️
ALFA-trained models maintain strong performance even on completely new interactive medical tasks (MediQ-MedQA).
highlighting ALFA’s potential for broader applicability in real-world clinical scenarios‼️

February 21, 2025 at 4:08 PM
🌟 Impressive Generalization!
ALFA-trained models maintain strong performance even on completely new interactive medical tasks (MediQ-MedQA).
highlighting ALFA’s potential for broader applicability in real-world clinical scenarios‼️
ALFA-trained models maintain strong performance even on completely new interactive medical tasks (MediQ-MedQA).
highlighting ALFA’s potential for broader applicability in real-world clinical scenarios‼️
🔬 Key Finding #2: Every Attribute Matters!
Removing any single attribute hurts performance‼️
Grouping general (clarify, focus, answerability) vs. clinical (medical accuracy, diagnostic relevance, avoiding DDX bias) attributes leads to drastically different outputs👩⚕️
Check out some cool examples!👇
Removing any single attribute hurts performance‼️
Grouping general (clarify, focus, answerability) vs. clinical (medical accuracy, diagnostic relevance, avoiding DDX bias) attributes leads to drastically different outputs👩⚕️
Check out some cool examples!👇

February 21, 2025 at 4:07 PM
🔬 Key Finding #2: Every Attribute Matters!
Removing any single attribute hurts performance‼️
Grouping general (clarify, focus, answerability) vs. clinical (medical accuracy, diagnostic relevance, avoiding DDX bias) attributes leads to drastically different outputs👩⚕️
Check out some cool examples!👇
Removing any single attribute hurts performance‼️
Grouping general (clarify, focus, answerability) vs. clinical (medical accuracy, diagnostic relevance, avoiding DDX bias) attributes leads to drastically different outputs👩⚕️
Check out some cool examples!👇
🔬 Key Finding #1: Preference Learning > Supervised Learning
Is it just good synthetic data❓ No❗️
Simply showing good examples isn't enough! Models need to learn directional differences between good and bad questions.
(but only SFT no DPO also doesn't work!)
Is it just good synthetic data❓ No❗️
Simply showing good examples isn't enough! Models need to learn directional differences between good and bad questions.
(but only SFT no DPO also doesn't work!)

February 21, 2025 at 4:05 PM
🔬 Key Finding #1: Preference Learning > Supervised Learning
Is it just good synthetic data❓ No❗️
Simply showing good examples isn't enough! Models need to learn directional differences between good and bad questions.
(but only SFT no DPO also doesn't work!)
Is it just good synthetic data❓ No❗️
Simply showing good examples isn't enough! Models need to learn directional differences between good and bad questions.
(but only SFT no DPO also doesn't work!)
Results show ALFA’s strengths🚀
ALFA-aligned models achieve:
⭐️56.6% reduction in diagnostic errors🦾
⭐️64.4% win rate in question quality✅
⭐️Strong generalization.
in comparison with baseline SoTA instruction-tuned LLMs.
ALFA-aligned models achieve:
⭐️56.6% reduction in diagnostic errors🦾
⭐️64.4% win rate in question quality✅
⭐️Strong generalization.
in comparison with baseline SoTA instruction-tuned LLMs.

February 21, 2025 at 4:04 PM
Results show ALFA’s strengths🚀
ALFA-aligned models achieve:
⭐️56.6% reduction in diagnostic errors🦾
⭐️64.4% win rate in question quality✅
⭐️Strong generalization.
in comparison with baseline SoTA instruction-tuned LLMs.
ALFA-aligned models achieve:
⭐️56.6% reduction in diagnostic errors🦾
⭐️64.4% win rate in question quality✅
⭐️Strong generalization.
in comparison with baseline SoTA instruction-tuned LLMs.
Introducing ALFA: ALignment via Fine-grained Attributes 🎓
A systematic, general question-asking framework that:
1️⃣ Decomposes the concept of good questioning into attributes📋
2️⃣ Generates targeted attribute-specific data📚
3️⃣ Teaches LLMs through preference learning🧑🏫
A systematic, general question-asking framework that:
1️⃣ Decomposes the concept of good questioning into attributes📋
2️⃣ Generates targeted attribute-specific data📚
3️⃣ Teaches LLMs through preference learning🧑🏫

February 21, 2025 at 4:01 PM
Introducing ALFA: ALignment via Fine-grained Attributes 🎓
A systematic, general question-asking framework that:
1️⃣ Decomposes the concept of good questioning into attributes📋
2️⃣ Generates targeted attribute-specific data📚
3️⃣ Teaches LLMs through preference learning🧑🏫
A systematic, general question-asking framework that:
1️⃣ Decomposes the concept of good questioning into attributes📋
2️⃣ Generates targeted attribute-specific data📚
3️⃣ Teaches LLMs through preference learning🧑🏫
Asking the right questions can make or break decisions in fields like medicine, law, and beyond✴️
Our new framework ALFA—ALignment with Fine-grained Attributes—teaches LLMs to PROACTIVE seek information through better questions through **structured rewards**🏥❓
(co-led with @jiminmun.bsky.social)
👉🏻🧵
Our new framework ALFA—ALignment with Fine-grained Attributes—teaches LLMs to PROACTIVE seek information through better questions through **structured rewards**🏥❓
(co-led with @jiminmun.bsky.social)
👉🏻🧵

February 21, 2025 at 4:00 PM
Asking the right questions can make or break decisions in fields like medicine, law, and beyond✴️
Our new framework ALFA—ALignment with Fine-grained Attributes—teaches LLMs to PROACTIVE seek information through better questions through **structured rewards**🏥❓
(co-led with @jiminmun.bsky.social)
👉🏻🧵
Our new framework ALFA—ALignment with Fine-grained Attributes—teaches LLMs to PROACTIVE seek information through better questions through **structured rewards**🏥❓
(co-led with @jiminmun.bsky.social)
👉🏻🧵

🏗️ Ablations:
• Adding rationale generation (RG) improves diagnostic accuracy and reduces calibration error.
• Self-consistency boosts reliability (but only with RG!).
Combining both enhances performance by 22%.
Each piece matters for better LLM reasoning! 📊
• Adding rationale generation (RG) improves diagnostic accuracy and reduces calibration error.
• Self-consistency boosts reliability (but only with RG!).
Combining both enhances performance by 22%.
Each piece matters for better LLM reasoning! 📊

December 6, 2024 at 10:53 PM
🏗️ Ablations:
• Adding rationale generation (RG) improves diagnostic accuracy and reduces calibration error.
• Self-consistency boosts reliability (but only with RG!).
Combining both enhances performance by 22%.
Each piece matters for better LLM reasoning! 📊
• Adding rationale generation (RG) improves diagnostic accuracy and reduces calibration error.
• Self-consistency boosts reliability (but only with RG!).
Combining both enhances performance by 22%.
Each piece matters for better LLM reasoning! 📊
Key findings✨:
📉SOTA LLMs fail at interactive clinical reasoning‼️they don’t ask questions.
👑BEST Expert improves diagnostic accuracy by 22% w/ abstention module.
🗨️ Iterative questioning helped gather crucial missing information in incomplete scenarios.
📉SOTA LLMs fail at interactive clinical reasoning‼️they don’t ask questions.
👑BEST Expert improves diagnostic accuracy by 22% w/ abstention module.
🗨️ Iterative questioning helped gather crucial missing information in incomplete scenarios.

December 6, 2024 at 10:53 PM
Key findings✨:
📉SOTA LLMs fail at interactive clinical reasoning‼️they don’t ask questions.
👑BEST Expert improves diagnostic accuracy by 22% w/ abstention module.
🗨️ Iterative questioning helped gather crucial missing information in incomplete scenarios.
📉SOTA LLMs fail at interactive clinical reasoning‼️they don’t ask questions.
👑BEST Expert improves diagnostic accuracy by 22% w/ abstention module.
🗨️ Iterative questioning helped gather crucial missing information in incomplete scenarios.
At the core of #MediQ is the Abstention Module🔍where the Expert evaluates its confidence before acting:
✅If confident, provide a final answer.
❓If unsure, it asks targeted questions to gather more info.
This process mimics how clinicians manage uncertainty, reducing errors and improving safety.
✅If confident, provide a final answer.
❓If unsure, it asks targeted questions to gather more info.
This process mimics how clinicians manage uncertainty, reducing errors and improving safety.

December 6, 2024 at 10:52 PM
At the core of #MediQ is the Abstention Module🔍where the Expert evaluates its confidence before acting:
✅If confident, provide a final answer.
❓If unsure, it asks targeted questions to gather more info.
This process mimics how clinicians manage uncertainty, reducing errors and improving safety.
✅If confident, provide a final answer.
❓If unsure, it asks targeted questions to gather more info.
This process mimics how clinicians manage uncertainty, reducing errors and improving safety.
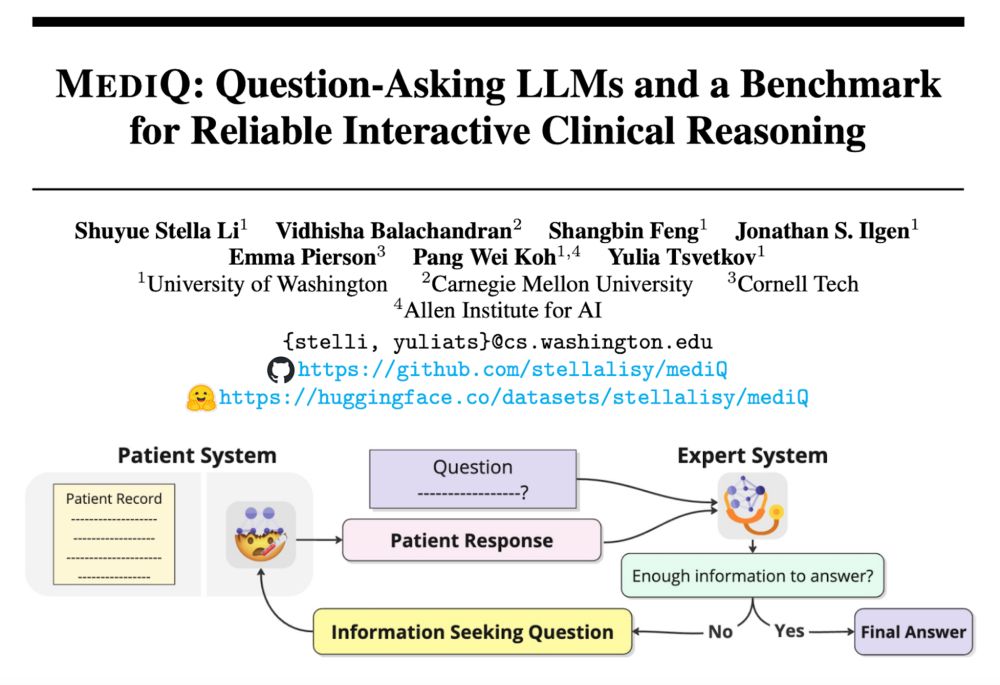
The #MediQ framework:
🤒Patient System: Simulates realistic patient responses with partial info.
🩺Expert System: Decides when to ask questions or answer using an abstention mechanism.
📊 Benchmark: Tests LLMs’ ability to handle iterative decision-making in medicine.
🤒Patient System: Simulates realistic patient responses with partial info.
🩺Expert System: Decides when to ask questions or answer using an abstention mechanism.
📊 Benchmark: Tests LLMs’ ability to handle iterative decision-making in medicine.

December 6, 2024 at 10:52 PM
The #MediQ framework:
🤒Patient System: Simulates realistic patient responses with partial info.
🩺Expert System: Decides when to ask questions or answer using an abstention mechanism.
📊 Benchmark: Tests LLMs’ ability to handle iterative decision-making in medicine.
🤒Patient System: Simulates realistic patient responses with partial info.
🩺Expert System: Decides when to ask questions or answer using an abstention mechanism.
📊 Benchmark: Tests LLMs’ ability to handle iterative decision-making in medicine.
31% of US adults use generative AI for healthcare 🤯But most AI systems answer questions assertively—even when they don’t have the necessary context. Introducing #MediQ a framework that enables LLMs to recognize uncertainty🤔and ask the right questions❓when info is missing: 🧵
December 6, 2024 at 10:51 PM
31% of US adults use generative AI for healthcare 🤯But most AI systems answer questions assertively—even when they don’t have the necessary context. Introducing #MediQ a framework that enables LLMs to recognize uncertainty🤔and ask the right questions❓when info is missing: 🧵
study music:1, taylor swift:0 (only for September I swear😅) Spotify knows too much about me….

December 4, 2024 at 7:45 PM
study music:1, taylor swift:0 (only for September I swear😅) Spotify knows too much about me….
Came across this paper, very cute of @hamishivi.bsky.social to say "popular BERT model"🤡

November 21, 2024 at 1:26 AM
Came across this paper, very cute of @hamishivi.bsky.social to say "popular BERT model"🤡
Had so much fun presenting our work ValueScope (arxiv.org/abs/2407.024...) at #EMNLP2024 and (mostly) enjoying Miami with friends last week🫶🏻🏖️!! Also learned about so many amazing works and now I’m inspired to start working again🫡💕



November 18, 2024 at 5:29 PM
Had so much fun presenting our work ValueScope (arxiv.org/abs/2407.024...) at #EMNLP2024 and (mostly) enjoying Miami with friends last week🫶🏻🏖️!! Also learned about so many amazing works and now I’m inspired to start working again🫡💕