



Stella Biderman
@stellaathena.bsky.social
I make sure that OpenAI et al. aren't the only people who are able to study large scale AI systems.
In the original Pile paper we talked about various conceptions of consent (though I don't stand by everything I wrote about this topic 5 years ago). None of this data has EIC, though I think that the ones marked "author" in the table are ones where authorial objection would be unreasonable.


October 20, 2025 at 6:55 AM
In the original Pile paper we talked about various conceptions of consent (though I don't stand by everything I wrote about this topic 5 years ago). None of this data has EIC, though I think that the ones marked "author" in the table are ones where authorial objection would be unreasonable.
Thanks for the signal boost! I think you'll appreciate the serious shade we threw at the end of our blog post: blog.eleuther.ai/deep-ignorance/

August 12, 2025 at 1:13 PM
Thanks for the signal boost! I think you'll appreciate the serious shade we threw at the end of our blog post: blog.eleuther.ai/deep-ignorance/
"But wait," the skeptic cries. "Surely this is infeasible for frontier models! Their datasets are far too large to expect companies to meaningfully understand or document!"
Actually our methodology is extremely cheap, mostly runs on CPU, and adds an overhead of less than 1%.
Actually our methodology is extremely cheap, mostly runs on CPU, and adds an overhead of less than 1%.

August 12, 2025 at 12:41 PM
"But wait," the skeptic cries. "Surely this is infeasible for frontier models! Their datasets are far too large to expect companies to meaningfully understand or document!"
Actually our methodology is extremely cheap, mostly runs on CPU, and adds an overhead of less than 1%.
Actually our methodology is extremely cheap, mostly runs on CPU, and adds an overhead of less than 1%.
Preventing a model from going into an interaction with relevant knowledge isn't a panacea though: filtered models see minimal performance loss when it comes to reasoning about information provided in-context. The models are still smart, they just don't know the concepts innately.

August 12, 2025 at 12:41 PM
Preventing a model from going into an interaction with relevant knowledge isn't a panacea though: filtered models see minimal performance loss when it comes to reasoning about information provided in-context. The models are still smart, they just don't know the concepts innately.
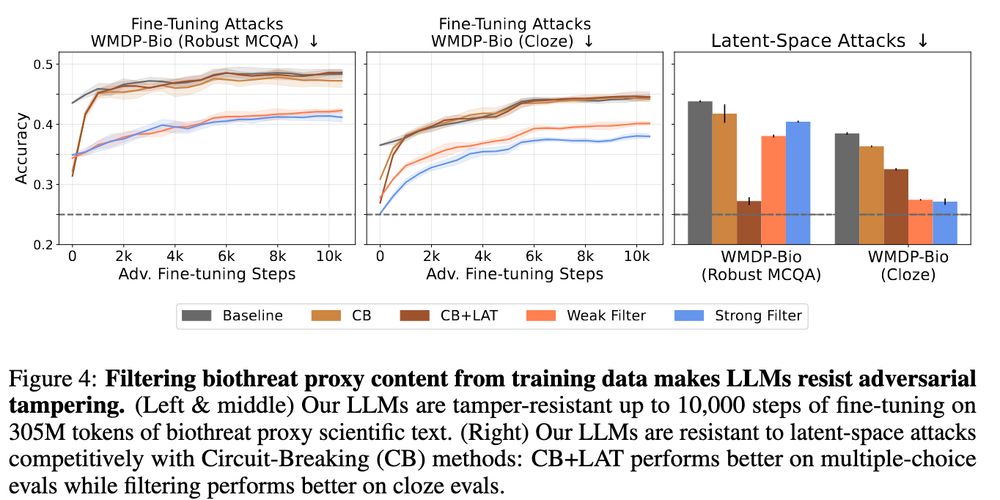
Our results are competitive with circuit-breaking when it comes to out-of-the-box performance and substantially more robust to both adversarial and benign finetuning. These results lead us to believe that we are genuinely impairing the knowledge of LLMs, not just suppressing it

August 12, 2025 at 12:40 PM
Our results are competitive with circuit-breaking when it comes to out-of-the-box performance and substantially more robust to both adversarial and benign finetuning. These results lead us to believe that we are genuinely impairing the knowledge of LLMs, not just suppressing it
Our headline result is simple: data filtering can send WMDP-Bio scores to random chance without hurting general performance. And FT'ing these models to match the performance of the baseline model w/o FT'ing requires 300M tokens of finetuning, >10x more than any other approach.

August 12, 2025 at 12:40 PM
Our headline result is simple: data filtering can send WMDP-Bio scores to random chance without hurting general performance. And FT'ing these models to match the performance of the baseline model w/o FT'ing requires 300M tokens of finetuning, >10x more than any other approach.
Are you afraid of LLMs teaching people how to build bioweapons? Have you tried just... not teaching LLMs about bioweapons?
@eleutherai.bsky.social and the UK AISI joined forces to see what would happen, pretraining three 6.9B models for 500B tokens and producing 15 total models to study
@eleutherai.bsky.social and the UK AISI joined forces to see what would happen, pretraining three 6.9B models for 500B tokens and producing 15 total models to study

August 12, 2025 at 12:40 PM
Are you afraid of LLMs teaching people how to build bioweapons? Have you tried just... not teaching LLMs about bioweapons?
@eleutherai.bsky.social and the UK AISI joined forces to see what would happen, pretraining three 6.9B models for 500B tokens and producing 15 total models to study
@eleutherai.bsky.social and the UK AISI joined forces to see what would happen, pretraining three 6.9B models for 500B tokens and producing 15 total models to study
"It's unclear if this research matters because real users speak English and Chinese" has got to be up there for worst dismissive takes about how multilingual doesn't matter.

July 30, 2025 at 7:26 PM
"It's unclear if this research matters because real users speak English and Chinese" has got to be up there for worst dismissive takes about how multilingual doesn't matter.

Our deep-dive case studies show typical AI blind spots: models struggle with long-tail knowledge absent from web data and extremely long contexts; without fully spelled-out derivations, they misinterpret calculations and ignore domain-specific conventions, leading to student-like errors. 🔍

May 23, 2025 at 4:22 PM
Our deep-dive case studies show typical AI blind spots: models struggle with long-tail knowledge absent from web data and extremely long contexts; without fully spelled-out derivations, they misinterpret calculations and ignore domain-specific conventions, leading to student-like errors. 🔍
We also look at what happens when you run a model multiple times: across 8 trials models rarely discover the same errors and generally assign a near-zero confidence to their claims.

May 23, 2025 at 4:22 PM
We also look at what happens when you run a model multiple times: across 8 trials models rarely discover the same errors and generally assign a near-zero confidence to their claims.
We benchmarked 10 top models, both closed and open, and the results are sobering – the best results are from o3 which has a precision of 6% and a recall of 21%. All other models score below 4% precision and 10% recall.

May 23, 2025 at 4:22 PM
We benchmarked 10 top models, both closed and open, and the results are sobering – the best results are from o3 which has a precision of 6% and a recall of 21%. All other models score below 4% precision and 10% recall.
2️⃣ The dataset spans long documents (avg 12,000 tokens) with rich visuals (avg 18 figures) 📊. Challenging both long-context reasoning and image understanding capabilities of modern LLMs.
To make sure these errors are genuine, we only include those that have been acknowledged by the original authors!
To make sure these errors are genuine, we only include those that have been acknowledged by the original authors!

May 23, 2025 at 4:22 PM
2️⃣ The dataset spans long documents (avg 12,000 tokens) with rich visuals (avg 18 figures) 📊. Challenging both long-context reasoning and image understanding capabilities of modern LLMs.
To make sure these errors are genuine, we only include those that have been acknowledged by the original authors!
To make sure these errors are genuine, we only include those that have been acknowledged by the original authors!
SPOT consists of 83 papers and 91 author-validated errors across 10 STEM fields and 6 error types – equation/proof, figure duplication, data inconsistency, statistical reporting, reagent identity, and experiment setup.
We note the location, severe, and have short human description of errors.
We note the location, severe, and have short human description of errors.
May 23, 2025 at 4:22 PM
SPOT consists of 83 papers and 91 author-validated errors across 10 STEM fields and 6 error types – equation/proof, figure duplication, data inconsistency, statistical reporting, reagent identity, and experiment setup.
We note the location, severe, and have short human description of errors.
We note the location, severe, and have short human description of errors.
People keep plugging AI "Co-Scientists," so what happens when you ask them to do an important task like finding errors in papers?
We built SPOT, a dataset of STEM manuscripts across 10 fields annotated with real errors to find out.
(tl;dr not even close to usable) #NLProc
arxiv.org/abs/2505.11855
We built SPOT, a dataset of STEM manuscripts across 10 fields annotated with real errors to find out.
(tl;dr not even close to usable) #NLProc
arxiv.org/abs/2505.11855

May 23, 2025 at 4:22 PM
People keep plugging AI "Co-Scientists," so what happens when you ask them to do an important task like finding errors in papers?
We built SPOT, a dataset of STEM manuscripts across 10 fields annotated with real errors to find out.
(tl;dr not even close to usable) #NLProc
arxiv.org/abs/2505.11855
We built SPOT, a dataset of STEM manuscripts across 10 fields annotated with real errors to find out.
(tl;dr not even close to usable) #NLProc
arxiv.org/abs/2505.11855
I can't read the linked article, but is this representation is even vaguely accurate that is deeply humiliating for ATI. LLMs may had caught the public by surprise in 2023 but they've been among the sexiest things in AI research since at least 2020 (when I entered the field, can't speak to before)

April 23, 2025 at 8:59 PM
I can't read the linked article, but is this representation is even vaguely accurate that is deeply humiliating for ATI. LLMs may had caught the public by surprise in 2023 but they've been among the sexiest things in AI research since at least 2020 (when I entered the field, can't speak to before)
@eleutherai.bsky.social succeeded in its original goal of ensuring independent research on LLMs would be possible. But the research landscape is still overwhelming dominated by corporate funding and corporate priorities and there's much more still to do to help non-profit research thrive.

February 13, 2025 at 7:56 PM
@eleutherai.bsky.social succeeded in its original goal of ensuring independent research on LLMs would be possible. But the research landscape is still overwhelming dominated by corporate funding and corporate priorities and there's much more still to do to help non-profit research thrive.
In case you're curious how much of a hellscape X is. I opened it today to get greeted with a porn ad. The censored section is a 20 second video clip of a woman sucking a dick, with audio. It autoplays.

February 7, 2025 at 10:47 AM
In case you're curious how much of a hellscape X is. I opened it today to get greeted with a porn ad. The censored section is a 20 second video clip of a woman sucking a dick, with audio. It autoplays.
Obligatory "actually my lab invented test-time-compute" post. In "Stay on topic with Classifier-Free Guidance," we show that CFG enables a model to expend twice as much compute at inference time and match the performance of a model twice as large.
arxiv.org/abs/2306.17806
arxiv.org/abs/2306.17806

January 29, 2025 at 6:56 PM
Obligatory "actually my lab invented test-time-compute" post. In "Stay on topic with Classifier-Free Guidance," we show that CFG enables a model to expend twice as much compute at inference time and match the performance of a model twice as large.
arxiv.org/abs/2306.17806
arxiv.org/abs/2306.17806


December 24, 2024 at 8:03 PM
“GPT-4o, o1, o1-preview & o1-mini all demonstrate strong persuasive argumentation abilities, within the top ~80-90% percentile of humans"
It's remarkable how what OpenAI considers "dangerous" changes continuously to exclude the thing they're currently selling. There was a time this was a red line.
It's remarkable how what OpenAI considers "dangerous" changes continuously to exclude the thing they're currently selling. There was a time this was a red line.

December 24, 2024 at 5:23 PM
“GPT-4o, o1, o1-preview & o1-mini all demonstrate strong persuasive argumentation abilities, within the top ~80-90% percentile of humans"
It's remarkable how what OpenAI considers "dangerous" changes continuously to exclude the thing they're currently selling. There was a time this was a red line.
It's remarkable how what OpenAI considers "dangerous" changes continuously to exclude the thing they're currently selling. There was a time this was a red line.
Is there any evidence that such a set-up works? I've seen a lot of claims that this is what MoE models do, but the empirical evidence (see, e.g., Mixtral) contradicts that.
It seems possible you could deliberately induce that, but again is there evidence that works well?
It seems possible you could deliberately induce that, but again is there evidence that works well?

December 14, 2024 at 6:00 PM
Is there any evidence that such a set-up works? I've seen a lot of claims that this is what MoE models do, but the empirical evidence (see, e.g., Mixtral) contradicts that.
It seems possible you could deliberately induce that, but again is there evidence that works well?
It seems possible you could deliberately induce that, but again is there evidence that works well?
I don't understand the hype around the Byte Latent Transformer... it's really unclear to me how it's supposed to work and these tables seem to be pretty contradictory? In particular, Table 5 seems to refute the rest of the paper


December 13, 2024 at 5:50 PM
I don't understand the hype around the Byte Latent Transformer... it's really unclear to me how it's supposed to work and these tables seem to be pretty contradictory? In particular, Table 5 seems to refute the rest of the paper
Assuming the subsequent 119 pages of math are, a new entry to the list of GOATed abstracts dropped this weekend.
arxiv.org/abs/2411.19826
arxiv.org/abs/2411.19826

December 2, 2024 at 10:06 PM
Assuming the subsequent 119 pages of math are, a new entry to the list of GOATed abstracts dropped this weekend.
arxiv.org/abs/2411.19826
arxiv.org/abs/2411.19826
The GDM paper on Stratego doesn't cite any papers by their titles?!? If you go look at the bibliography there just aren't titles for the papers listed.
I sure how there aren't multiple papers that match "J. Doe et al. NeurIPS (2023)."
arxiv.org/abs/2206.15378
Why would anyone do this?
I sure how there aren't multiple papers that match "J. Doe et al. NeurIPS (2023)."
arxiv.org/abs/2206.15378
Why would anyone do this?


December 1, 2024 at 5:33 AM
The GDM paper on Stratego doesn't cite any papers by their titles?!? If you go look at the bibliography there just aren't titles for the papers listed.
I sure how there aren't multiple papers that match "J. Doe et al. NeurIPS (2023)."
arxiv.org/abs/2206.15378
Why would anyone do this?
I sure how there aren't multiple papers that match "J. Doe et al. NeurIPS (2023)."
arxiv.org/abs/2206.15378
Why would anyone do this?