



Sonia Mazelet
@soniamazelet.bsky.social
PhD student at École Polytechnique and Inria working on optimal transport, machine learning and their applications to neuroscience
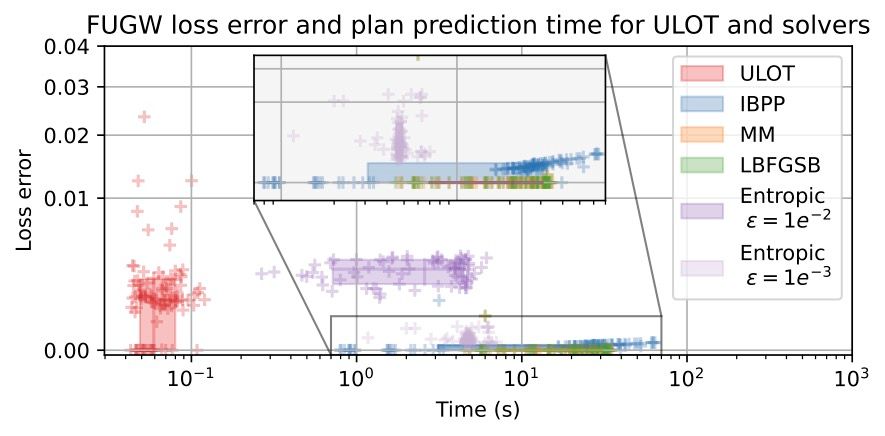
We apply ULOT to the problem of brain alignment and find that it predicts near-optimal FUGW plans up to 100× times faster than other solvers.
This efficiency enables detailed exploration of the effects of the FUGW hyperparameters on the optimal plans, and many more applications!
(5/5)
This efficiency enables detailed exploration of the effects of the FUGW hyperparameters on the optimal plans, and many more applications!
(5/5)


September 29, 2025 at 8:55 AM
We apply ULOT to the problem of brain alignment and find that it predicts near-optimal FUGW plans up to 100× times faster than other solvers.
This efficiency enables detailed exploration of the effects of the FUGW hyperparameters on the optimal plans, and many more applications!
(5/5)
This efficiency enables detailed exploration of the effects of the FUGW hyperparameters on the optimal plans, and many more applications!
(5/5)
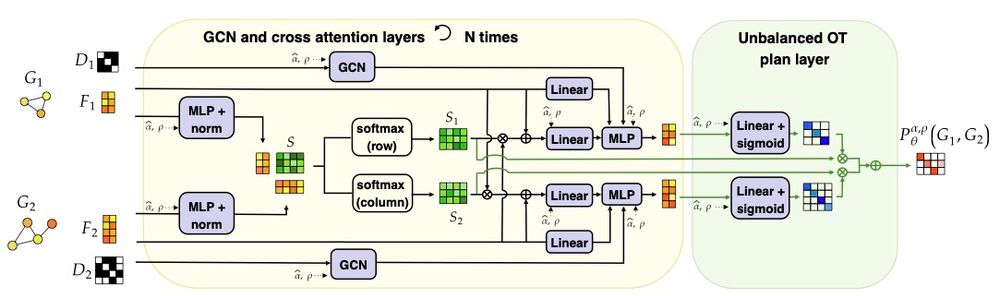
ULOT predicts FUGW plans conditioned on the FUGW hyperparameters.
Trained in a fully unsupervised way by minimizing the FUGW loss, it ensures the near optimality of its predictions and diminishes the complexity of finding optimal FUGW plans from cubic to quadratic in the number of nodes.
(4/5)
Trained in a fully unsupervised way by minimizing the FUGW loss, it ensures the near optimality of its predictions and diminishes the complexity of finding optimal FUGW plans from cubic to quadratic in the number of nodes.
(4/5)
September 29, 2025 at 8:55 AM
ULOT predicts FUGW plans conditioned on the FUGW hyperparameters.
Trained in a fully unsupervised way by minimizing the FUGW loss, it ensures the near optimality of its predictions and diminishes the complexity of finding optimal FUGW plans from cubic to quadratic in the number of nodes.
(4/5)
Trained in a fully unsupervised way by minimizing the FUGW loss, it ensures the near optimality of its predictions and diminishes the complexity of finding optimal FUGW plans from cubic to quadratic in the number of nodes.
(4/5)
Matching graphs can be achieved with the optimal transport distance Fused Unbalanced Gromov Wasserstein (FUGW). It produces meaningful plans but requires solving an optimization problem with cubic complexity in the number of nodes, which limits its applications.
(3/5)
(3/5)

September 29, 2025 at 8:55 AM
Matching graphs can be achieved with the optimal transport distance Fused Unbalanced Gromov Wasserstein (FUGW). It produces meaningful plans but requires solving an optimization problem with cubic complexity in the number of nodes, which limits its applications.
(3/5)
(3/5)
We developed ULOT, a neural network designed to predict optimal transport plans between graphs. It achieves accurate predictions up to 100× faster than solvers, both on synthetic graphs and on brain data.
(2/5)
(2/5)
September 29, 2025 at 8:55 AM
We developed ULOT, a neural network designed to predict optimal transport plans between graphs. It achieves accurate predictions up to 100× faster than solvers, both on synthetic graphs and on brain data.
(2/5)
(2/5)