



📘 How it works (high level): identify the teacher’s task circuit --> find functionally analogous student components via ablation --> align their internals during training. Outcome: the student learns the same computation, not just the outputs. (3/4)

September 30, 2025 at 11:32 PM
📘 How it works (high level): identify the teacher’s task circuit --> find functionally analogous student components via ablation --> align their internals during training. Outcome: the student learns the same computation, not just the outputs. (3/4)
🍎 On Entity Tracking and Theory of Mind, a student that updates only ~11–15% of attention heads inherits the teacher’s capability and closes much of the gap; targeted transfer over brute-force fine-tuning. (2/4)

September 30, 2025 at 11:32 PM
🍎 On Entity Tracking and Theory of Mind, a student that updates only ~11–15% of attention heads inherits the teacher’s capability and closes much of the gap; targeted transfer over brute-force fine-tuning. (2/4)
🔊 New work w/ @silvioamir.bsky.social & @byron.bsky.social! We show you can distill a model’s mechanism, not just its answers -- teaching a small LM to run it's circuit same as a larger teacher model. We call it Circuit Distillation. (1/4)
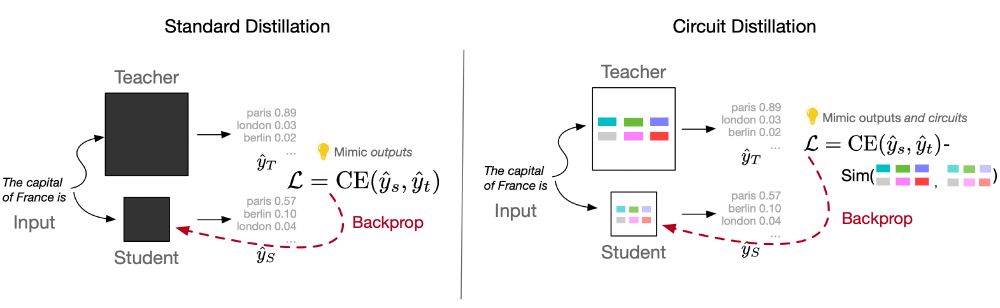
September 30, 2025 at 11:32 PM
🔊 New work w/ @silvioamir.bsky.social & @byron.bsky.social! We show you can distill a model’s mechanism, not just its answers -- teaching a small LM to run it's circuit same as a larger teacher model. We call it Circuit Distillation. (1/4)
3️⃣ But here’s the twist: Syntactic patterns (like Part-of-Speech templates) do retain strong teacher signals! Students unconsciously mimic structural patterns from their teacher, leaving behind an identifiable trace 🧩 [4/6]

February 11, 2025 at 5:16 PM
3️⃣ But here’s the twist: Syntactic patterns (like Part-of-Speech templates) do retain strong teacher signals! Students unconsciously mimic structural patterns from their teacher, leaving behind an identifiable trace 🧩 [4/6]
2️⃣ Simple similarity metrics like BERTScore fail to attribute a student to its teacher. Even perplexity under the teacher model isn’t enough to reliably identify the original teacher. Shallow lexical overlap is just not a strong fingerprint 🔍 [3/6]


February 11, 2025 at 5:16 PM
2️⃣ Simple similarity metrics like BERTScore fail to attribute a student to its teacher. Even perplexity under the teacher model isn’t enough to reliably identify the original teacher. Shallow lexical overlap is just not a strong fingerprint 🔍 [3/6]
1️⃣ Model distillation transfers knowledge from a large teacher model to a smaller student model. But does the fine-tuned student reveal clues in its outputs about its origins? [2/6]

February 11, 2025 at 5:16 PM
1️⃣ Model distillation transfers knowledge from a large teacher model to a smaller student model. But does the fine-tuned student reveal clues in its outputs about its origins? [2/6]