



Simon Schug
@smonsays.bsky.social

November 4, 2025 at 2:33 PM
But, not all training distributions enable compositional generalization -- even with scale.
Strategically choosing the training data matters a lot.
Strategically choosing the training data matters a lot.

November 4, 2025 at 2:33 PM
But, not all training distributions enable compositional generalization -- even with scale.
Strategically choosing the training data matters a lot.
Strategically choosing the training data matters a lot.
We prove that MLPs can implement a general class of compositional tasks ("hyperteachers") using only a linear number of neurons in the number of modules, beating the exponential!

November 4, 2025 at 2:33 PM
We prove that MLPs can implement a general class of compositional tasks ("hyperteachers") using only a linear number of neurons in the number of modules, beating the exponential!
It turns out that simply scaling multilayer perceptrons / transformers can lead to compositional generalization.

November 4, 2025 at 2:33 PM
It turns out that simply scaling multilayer perceptrons / transformers can lead to compositional generalization.
Most natural data has compositional structure. This leads to a combinatorial explosion that is impossible to fully cover in the training data.
It might be tempting to think that we need to equip neural network architectures with stronger symbolic priors to capture this compositionality, but do we?
It might be tempting to think that we need to equip neural network architectures with stronger symbolic priors to capture this compositionality, but do we?

November 4, 2025 at 2:33 PM
Most natural data has compositional structure. This leads to a combinatorial explosion that is impossible to fully cover in the training data.
It might be tempting to think that we need to equip neural network architectures with stronger symbolic priors to capture this compositionality, but do we?
It might be tempting to think that we need to equip neural network architectures with stronger symbolic priors to capture this compositionality, but do we?
Does scaling lead to compositional generaliztation?
Our #NeurIPS2025 Spotlight paper suggests that it can -- with the right training distribution.
🧵 A short thread:
Our #NeurIPS2025 Spotlight paper suggests that it can -- with the right training distribution.
🧵 A short thread:

November 4, 2025 at 2:33 PM
Does scaling lead to compositional generaliztation?
Our #NeurIPS2025 Spotlight paper suggests that it can -- with the right training distribution.
🧵 A short thread:
Our #NeurIPS2025 Spotlight paper suggests that it can -- with the right training distribution.
🧵 A short thread:
Are transformers smarter than you? Hypernetworks might explain why.
Come checkout our Oral at #ICLR tomorrow (Apr 26th, poster at 10:00, Oral session 6C in the afternoon).
openreview.net/forum?id=V4K...
Come checkout our Oral at #ICLR tomorrow (Apr 26th, poster at 10:00, Oral session 6C in the afternoon).
openreview.net/forum?id=V4K...

April 25, 2025 at 4:50 AM
Are transformers smarter than you? Hypernetworks might explain why.
Come checkout our Oral at #ICLR tomorrow (Apr 26th, poster at 10:00, Oral session 6C in the afternoon).
openreview.net/forum?id=V4K...
Come checkout our Oral at #ICLR tomorrow (Apr 26th, poster at 10:00, Oral session 6C in the afternoon).
openreview.net/forum?id=V4K...
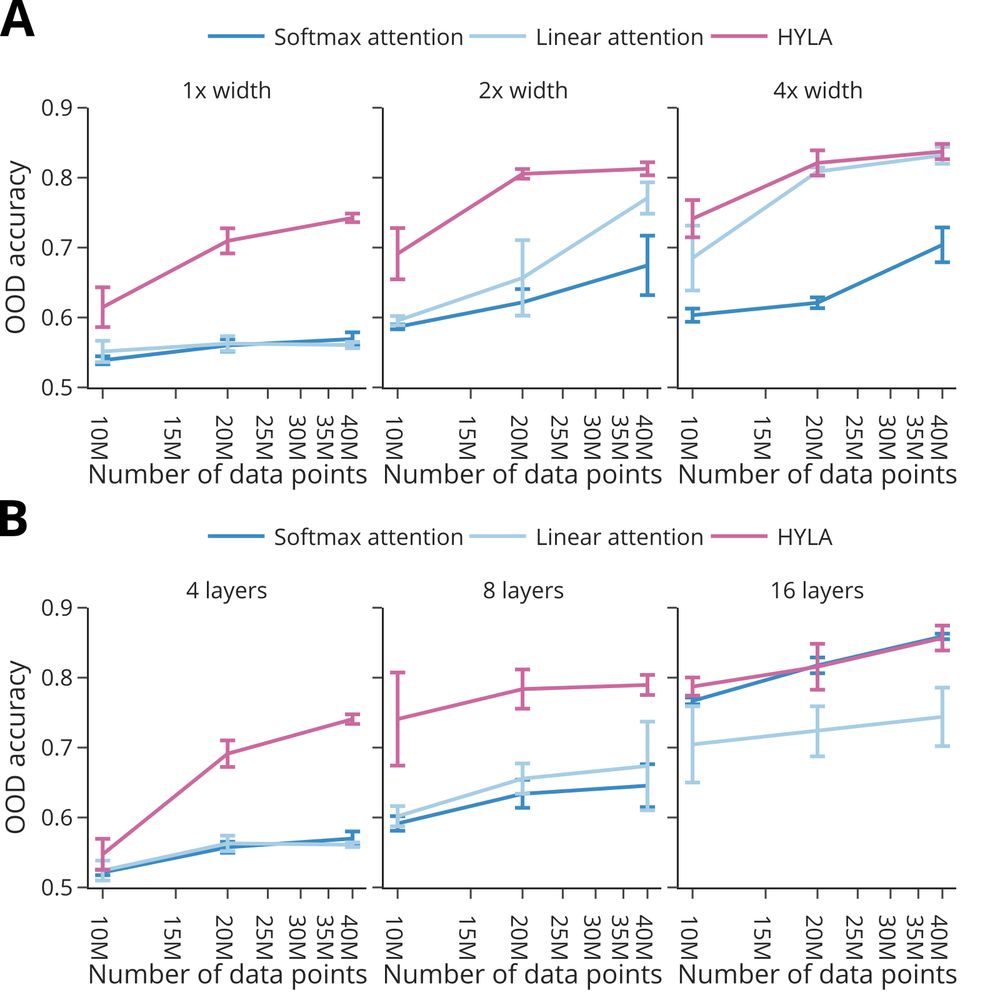
Indeed in line with the hypothesis that the hypernetwork mechanism supports compositionality, this modification (hyla) improves performance on unseen tasks.
October 28, 2024 at 3:26 PM
Indeed in line with the hypothesis that the hypernetwork mechanism supports compositionality, this modification (hyla) improves performance on unseen tasks.
So what happens if we strengthen the hypernetwork mechanism?
Could we maybe further improve compositionality?
We can for instance make the value network nonlinear - without introducing additional parameters.
Could we maybe further improve compositionality?
We can for instance make the value network nonlinear - without introducing additional parameters.
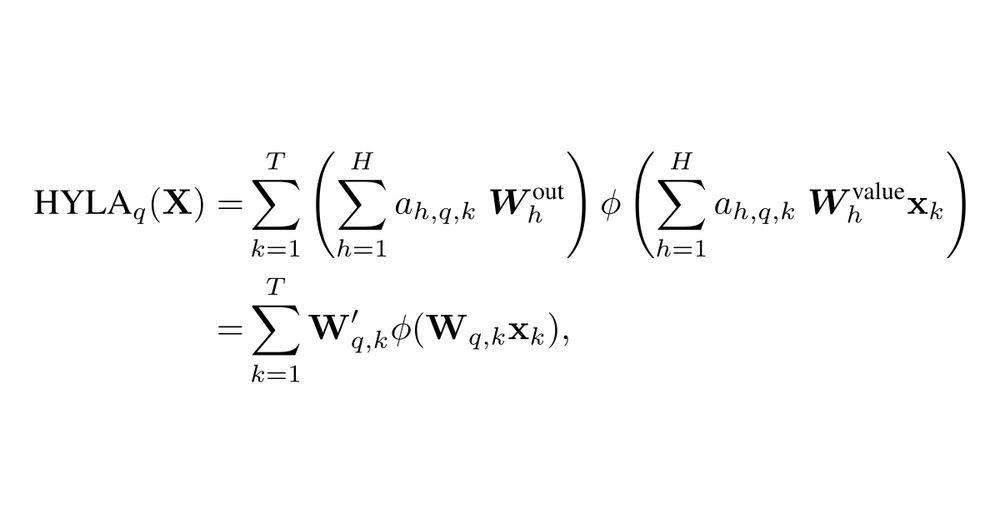
October 28, 2024 at 3:26 PM
So what happens if we strengthen the hypernetwork mechanism?
Could we maybe further improve compositionality?
We can for instance make the value network nonlinear - without introducing additional parameters.
Could we maybe further improve compositionality?
We can for instance make the value network nonlinear - without introducing additional parameters.
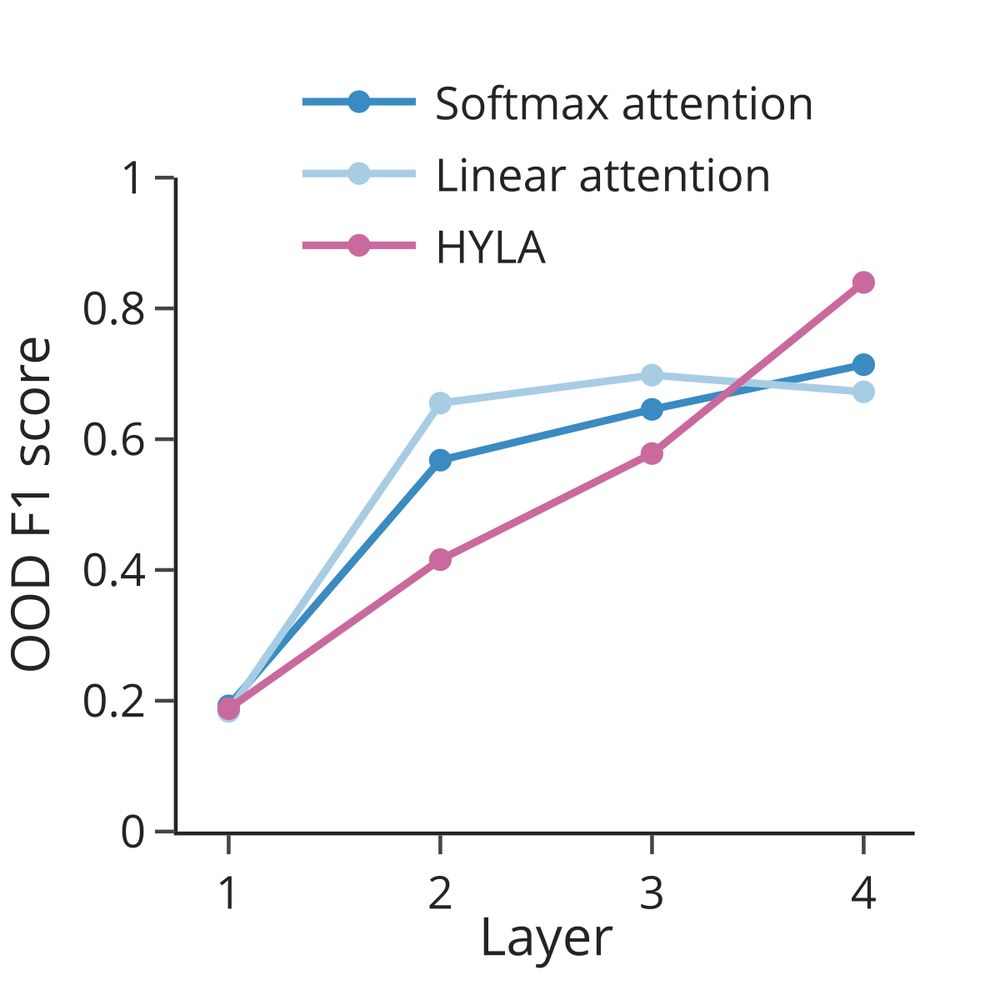
Training a simple decoder on the latent codes of training tasks allows us to predict the operations performed by the network on unseen tasks - especially for later layers.
October 28, 2024 at 3:25 PM
Training a simple decoder on the latent codes of training tasks allows us to predict the operations performed by the network on unseen tasks - especially for later layers.
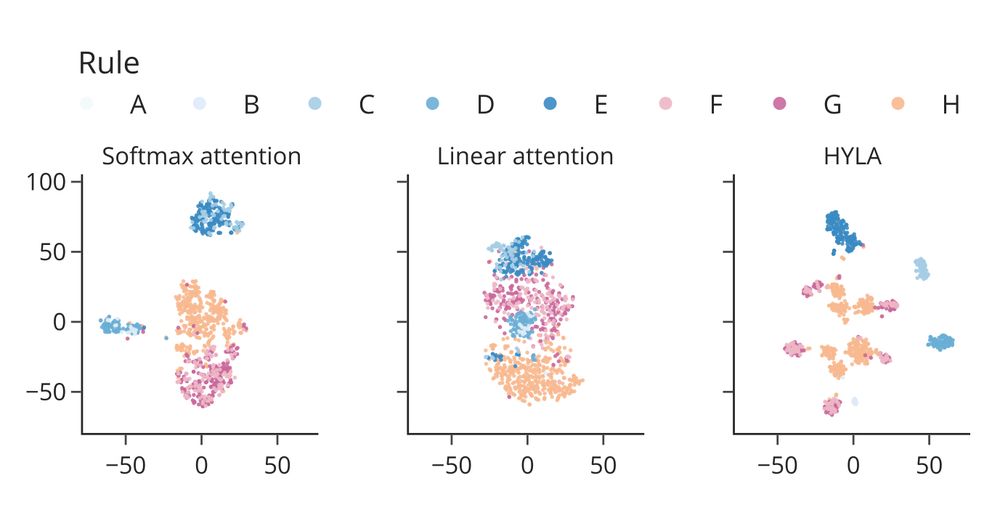
To test this hypothesis we train small transformer models to solve abstract reasoning tasks. When we look at the latent code of tasks they have never seen before, we find a highly structured space.
October 28, 2024 at 3:25 PM
To test this hypothesis we train small transformer models to solve abstract reasoning tasks. When we look at the latent code of tasks they have never seen before, we find a highly structured space.
From the hypernetwork perspective, a compact latent code specifies key-query specific operations.
Importantly, these operations are reusable: the same hypernetwork is used across all key-query pairs.
Could their reuse allow transformers to compositionally generalize?
Importantly, these operations are reusable: the same hypernetwork is used across all key-query pairs.
Could their reuse allow transformers to compositionally generalize?
October 28, 2024 at 3:24 PM
From the hypernetwork perspective, a compact latent code specifies key-query specific operations.
Importantly, these operations are reusable: the same hypernetwork is used across all key-query pairs.
Could their reuse allow transformers to compositionally generalize?
Importantly, these operations are reusable: the same hypernetwork is used across all key-query pairs.
Could their reuse allow transformers to compositionally generalize?
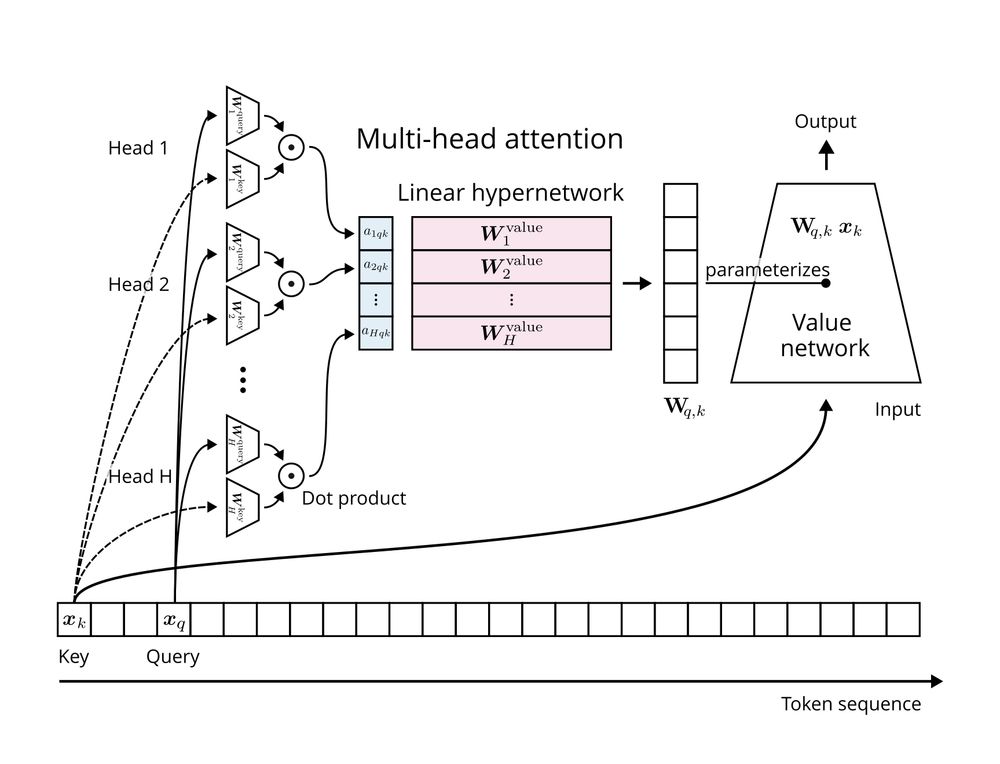
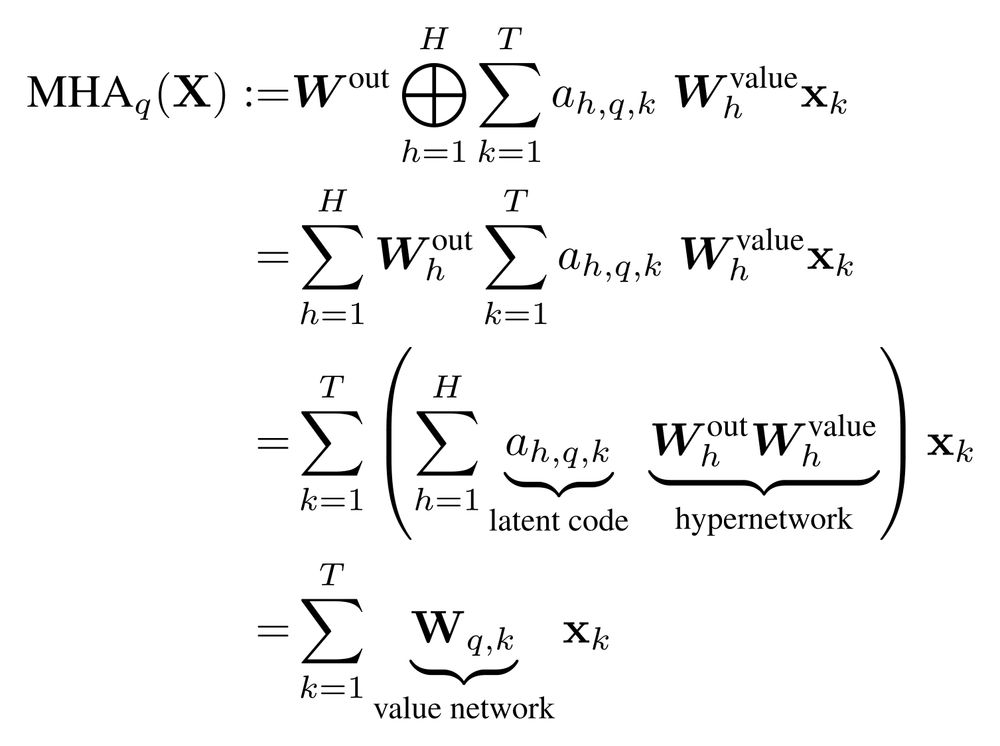
For a given query, multi-head attention can be rewritten as a sum over the outputs of key-query specific value networks configured by a hypernetwork.
These hypernetworks are comparably simple: Both the hypernetwork and its value network are linear.
So why could this matter?
These hypernetworks are comparably simple: Both the hypernetwork and its value network are linear.
So why could this matter?
October 28, 2024 at 3:23 PM
For a given query, multi-head attention can be rewritten as a sum over the outputs of key-query specific value networks configured by a hypernetwork.
These hypernetworks are comparably simple: Both the hypernetwork and its value network are linear.
So why could this matter?
These hypernetworks are comparably simple: Both the hypernetwork and its value network are linear.
So why could this matter?
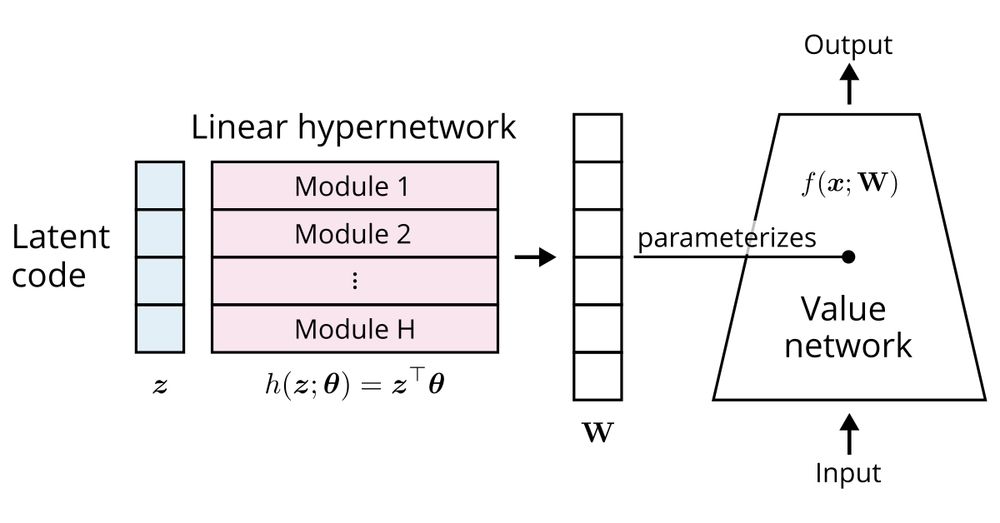
We know that hypernetworks - neural networks that generate the weights of another neural network - can compositionally generalize. So, should we build more hypernetworks into our transformers?
It turns out that attention with multiple heads already has them built-in!
It turns out that attention with multiple heads already has them built-in!
October 28, 2024 at 3:22 PM
We know that hypernetworks - neural networks that generate the weights of another neural network - can compositionally generalize. So, should we build more hypernetworks into our transformers?
It turns out that attention with multiple heads already has them built-in!
It turns out that attention with multiple heads already has them built-in!
Neural networks used to struggle with compositionality but transformers got really good at it. How come?
And why does attention work so much better with multiple heads?
There might be a common answer to both of these questions.
And why does attention work so much better with multiple heads?
There might be a common answer to both of these questions.

October 28, 2024 at 3:22 PM
Neural networks used to struggle with compositionality but transformers got really good at it. How come?
And why does attention work so much better with multiple heads?
There might be a common answer to both of these questions.
And why does attention work so much better with multiple heads?
There might be a common answer to both of these questions.