



Yannis Kalantidis
@skamalas.bsky.social
he/him; Researcher at NAVER LABS Europe. Greek, resident a Barcelona. https://www.skamalas.com/
6/ 📄 Paper 2:
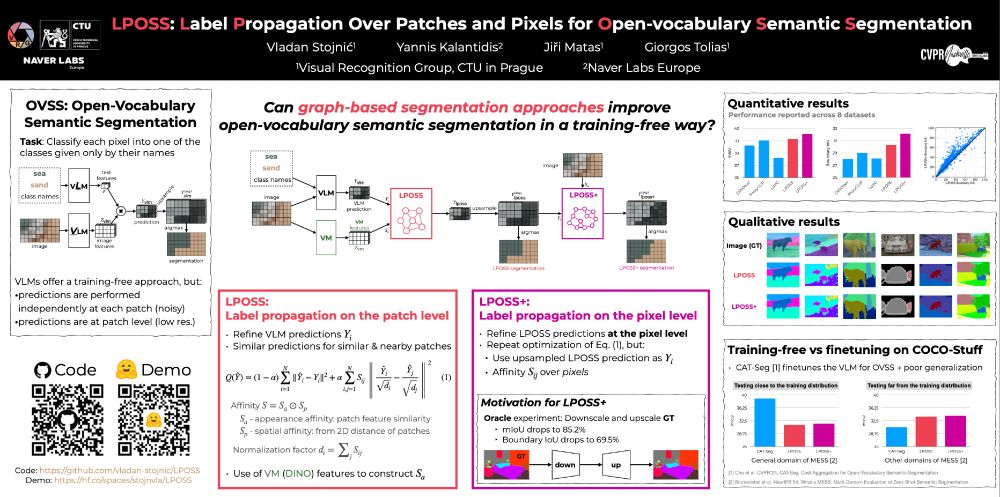
"LPOSS: Label Propagation Over Patches and Pixels for Open-Vocabulary Semantic Segmentation"
Can graph-based label propagation refine weak, patch-level predictions from VLMs like CLIP? We say yes — introducing LPOSS and LPOSS+.
"LPOSS: Label Propagation Over Patches and Pixels for Open-Vocabulary Semantic Segmentation"
Can graph-based label propagation refine weak, patch-level predictions from VLMs like CLIP? We say yes — introducing LPOSS and LPOSS+.
June 9, 2025 at 11:07 AM
6/ 📄 Paper 2:
"LPOSS: Label Propagation Over Patches and Pixels for Open-Vocabulary Semantic Segmentation"
Can graph-based label propagation refine weak, patch-level predictions from VLMs like CLIP? We say yes — introducing LPOSS and LPOSS+.
"LPOSS: Label Propagation Over Patches and Pixels for Open-Vocabulary Semantic Segmentation"
Can graph-based label propagation refine weak, patch-level predictions from VLMs like CLIP? We say yes — introducing LPOSS and LPOSS+.
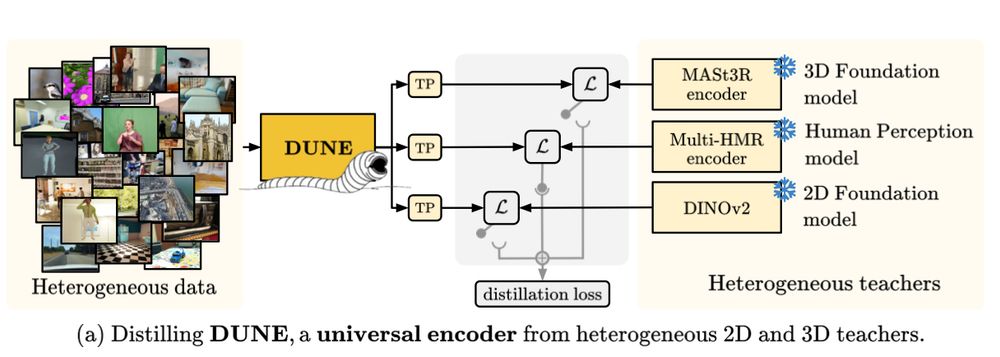
2/ 🧠 Why DUNE?
→ 2D & 3D vision models (e.g., segmentation, mono- or binocular depth, human mesh, 3D reconstruction) are siloed.
→ Can we distill their knowledge into a single universal encoder?
Yes — using multi-teacher distillation with transformer projectors, teacher dropping, and more.
→ 2D & 3D vision models (e.g., segmentation, mono- or binocular depth, human mesh, 3D reconstruction) are siloed.
→ Can we distill their knowledge into a single universal encoder?
Yes — using multi-teacher distillation with transformer projectors, teacher dropping, and more.
June 9, 2025 at 11:07 AM
2/ 🧠 Why DUNE?
→ 2D & 3D vision models (e.g., segmentation, mono- or binocular depth, human mesh, 3D reconstruction) are siloed.
→ Can we distill their knowledge into a single universal encoder?
Yes — using multi-teacher distillation with transformer projectors, teacher dropping, and more.
→ 2D & 3D vision models (e.g., segmentation, mono- or binocular depth, human mesh, 3D reconstruction) are siloed.
→ Can we distill their knowledge into a single universal encoder?
Yes — using multi-teacher distillation with transformer projectors, teacher dropping, and more.
1/ 📄 Paper 1:
"DUNE: Distilling a UNiversal Encoder from Heterogeneous 2D and 3D Teachers"
We propose DUNE: a ViT-based encoder distilled from multiple specialized 2D & 3D foundation models to unify visual tasks across 2D, 3D and human understanding.
"DUNE: Distilling a UNiversal Encoder from Heterogeneous 2D and 3D Teachers"
We propose DUNE: a ViT-based encoder distilled from multiple specialized 2D & 3D foundation models to unify visual tasks across 2D, 3D and human understanding.

June 9, 2025 at 11:07 AM
1/ 📄 Paper 1:
"DUNE: Distilling a UNiversal Encoder from Heterogeneous 2D and 3D Teachers"
We propose DUNE: a ViT-based encoder distilled from multiple specialized 2D & 3D foundation models to unify visual tasks across 2D, 3D and human understanding.
"DUNE: Distilling a UNiversal Encoder from Heterogeneous 2D and 3D Teachers"
We propose DUNE: a ViT-based encoder distilled from multiple specialized 2D & 3D foundation models to unify visual tasks across 2D, 3D and human understanding.