



@simjeg.bsky.social
Senior LLM Technologist @NVIDIA
Views and opinions are my own
Views and opinions are my own
-> Repo: github.com/NVIDIA/kvpress (⭐️ me)
-> Blog post: huggingface.co/spaces/nvidi... (🔺me)
-> Space: huggingface.co/spaces/nvidi... (❤️me)
(2/2)
-> Blog post: huggingface.co/spaces/nvidi... (🔺me)
-> Space: huggingface.co/spaces/nvidi... (❤️me)
(2/2)

GitHub - NVIDIA/kvpress: LLM KV cache compression made easy
LLM KV cache compression made easy. Contribute to NVIDIA/kvpress development by creating an account on GitHub.
github.com
January 23, 2025 at 10:03 AM
-> Repo: github.com/NVIDIA/kvpress (⭐️ me)
-> Blog post: huggingface.co/spaces/nvidi... (🔺me)
-> Space: huggingface.co/spaces/nvidi... (❤️me)
(2/2)
-> Blog post: huggingface.co/spaces/nvidi... (🔺me)
-> Space: huggingface.co/spaces/nvidi... (❤️me)
(2/2)
nice work ! Identifying patterns could be done on the fly:
bsky.app/profile/simj...
bsky.app/profile/simj...
Hidden states in LLM ~ follow normal distributions. Consequently, both queries and keys also follow a normal distribution and if you replace all queries and keys by their average counterpart, this magically explains the slash pattern observed in attention matrices

November 22, 2024 at 7:35 AM
nice work ! Identifying patterns could be done on the fly:
bsky.app/profile/simj...
bsky.app/profile/simj...
of course it's different ! transformer is an MLP predicting the parameters of another MLP 😀
November 21, 2024 at 6:46 PM
of course it's different ! transformer is an MLP predicting the parameters of another MLP 😀
You can reproduce this plot using this colab notebook: colab.research.google.com/drive/1DbAEm.... We used this property to create a new KV cache compression called Expected Attention in our kvpress repository:

Google Colab
colab.research.google.com
November 20, 2024 at 10:06 AM
You can reproduce this plot using this colab notebook: colab.research.google.com/drive/1DbAEm.... We used this property to create a new KV cache compression called Expected Attention in our kvpress repository:
I created a DistillationPress that distills the (K,V) cache into a compressed (Kc,Vc) cache by minimizing ||A(q,K,V) - A(q,Kc,Vc)||^2. Checkout my notebook here: github.com/NVIDIA/kvpre.... More work needs to be done, it's just a first step (3/3)
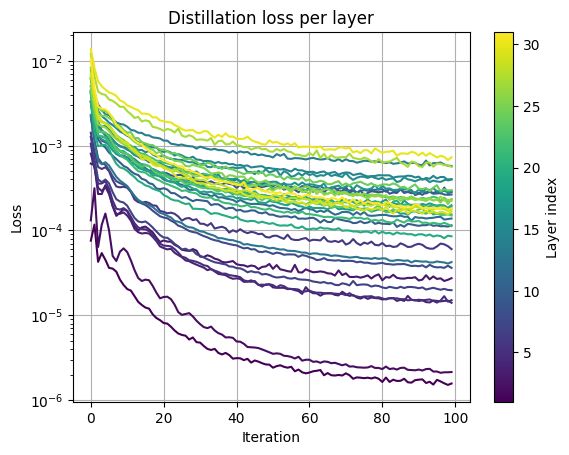
November 20, 2024 at 9:55 AM
I created a DistillationPress that distills the (K,V) cache into a compressed (Kc,Vc) cache by minimizing ||A(q,K,V) - A(q,Kc,Vc)||^2. Checkout my notebook here: github.com/NVIDIA/kvpre.... More work needs to be done, it's just a first step (3/3)
KV cache quantization ? KV cache pruning ? KV cache approximation ? Replace "KV cache" by "MLP" and you'll see most of the research has already been explored🤯 So I gave it a try in within our new kvpress repo 👇 (2/3)
November 20, 2024 at 9:55 AM
KV cache quantization ? KV cache pruning ? KV cache approximation ? Replace "KV cache" by "MLP" and you'll see most of the research has already been explored🤯 So I gave it a try in within our new kvpress repo 👇 (2/3)
This release also introduces a new method we developed: Expected Attention! 🎯 By leveraging the normal distribution of LLM hidden states, it measures the importance of each key-value pair. Learn more in this notebook: github.com/NVIDIA/kvpre... (4/4)

kvpress/notebooks/expected_attention.ipynb at main · NVIDIA/kvpress
LLM KV cache compression made easy. Contribute to NVIDIA/kvpress development by creating an account on GitHub.
github.com
November 19, 2024 at 2:25 PM
This release also introduces a new method we developed: Expected Attention! 🎯 By leveraging the normal distribution of LLM hidden states, it measures the importance of each key-value pair. Learn more in this notebook: github.com/NVIDIA/kvpre... (4/4)
kvpress aims at helping researchers and developers to create and benchmark KV cache compression techniques offering a user-friendly repo built on 🤗 Transformers. All implemented methods are training free and model agnostic (3/4)
November 19, 2024 at 2:25 PM
kvpress aims at helping researchers and developers to create and benchmark KV cache compression techniques offering a user-friendly repo built on 🤗 Transformers. All implemented methods are training free and model agnostic (3/4)
Long-context LLMs are resource-heavy due to KV cache growth: e.g., 1M tokens for Llama 3.1-70B (float16) needs 330GB of memory 😬. This challenge has driven intense research into KV cache compression, with many submissions to #ICLR2025. (2/4)
November 19, 2024 at 2:25 PM
Long-context LLMs are resource-heavy due to KV cache growth: e.g., 1M tokens for Llama 3.1-70B (float16) needs 330GB of memory 😬. This challenge has driven intense research into KV cache compression, with many submissions to #ICLR2025. (2/4)