



Shivani Kumar
@shivanikumar.bsky.social
Postdoc @ University of Michigan | PhD from LCS2, IIITDelhi | Working in Computational Social Science #NLProc
More info: kumarshivani.com
More info: kumarshivani.com
Work done at #UMSI with the amazing @davidjurgens.bsky.social! Read more in our preprint! 🔗
📄 Paper: arxiv.org/abs/2502.14083
📂 Dataset: huggingface.co/datasets/shi...
@umichresearch.bsky.social #umichresearch #umich
(n/n)
📄 Paper: arxiv.org/abs/2502.14083
📂 Dataset: huggingface.co/datasets/shi...
@umichresearch.bsky.social #umichresearch #umich
(n/n)
March 1, 2025 at 12:56 AM
Work done at #UMSI with the amazing @davidjurgens.bsky.social! Read more in our preprint! 🔗
📄 Paper: arxiv.org/abs/2502.14083
📂 Dataset: huggingface.co/datasets/shi...
@umichresearch.bsky.social #umichresearch #umich
(n/n)
📄 Paper: arxiv.org/abs/2502.14083
📂 Dataset: huggingface.co/datasets/shi...
@umichresearch.bsky.social #umichresearch #umich
(n/n)
🏁 Final verdict? Across languages & contexts, models struggle to exceed chance in moral reasoning, highlighting gaps, especially in data-scarce languages.
UniMoral supports studies on cross-cultural moral generalization, bias detection, & value quantification to enhance ethics in AI! (8/n)
UniMoral supports studies on cross-cultural moral generalization, bias detection, & value quantification to enhance ethics in AI! (8/n)
March 1, 2025 at 12:56 AM
🏁 Final verdict? Across languages & contexts, models struggle to exceed chance in moral reasoning, highlighting gaps, especially in data-scarce languages.
UniMoral supports studies on cross-cultural moral generalization, bias detection, & value quantification to enhance ethics in AI! (8/n)
UniMoral supports studies on cross-cultural moral generalization, bias detection, & value quantification to enhance ethics in AI! (8/n)
Are models better at psychological vs. real-world dilemmas?
👍 Yes, models perform better on psychological scenarios than Reddit dilemmas.
The gap is larger in predicting ethics & decision factors.
Why? Structured scenarios align with values, while Reddit dilemmas add noise and ambiguity. (7/n)
👍 Yes, models perform better on psychological scenarios than Reddit dilemmas.
The gap is larger in predicting ethics & decision factors.
Why? Structured scenarios align with values, while Reddit dilemmas add noise and ambiguity. (7/n)
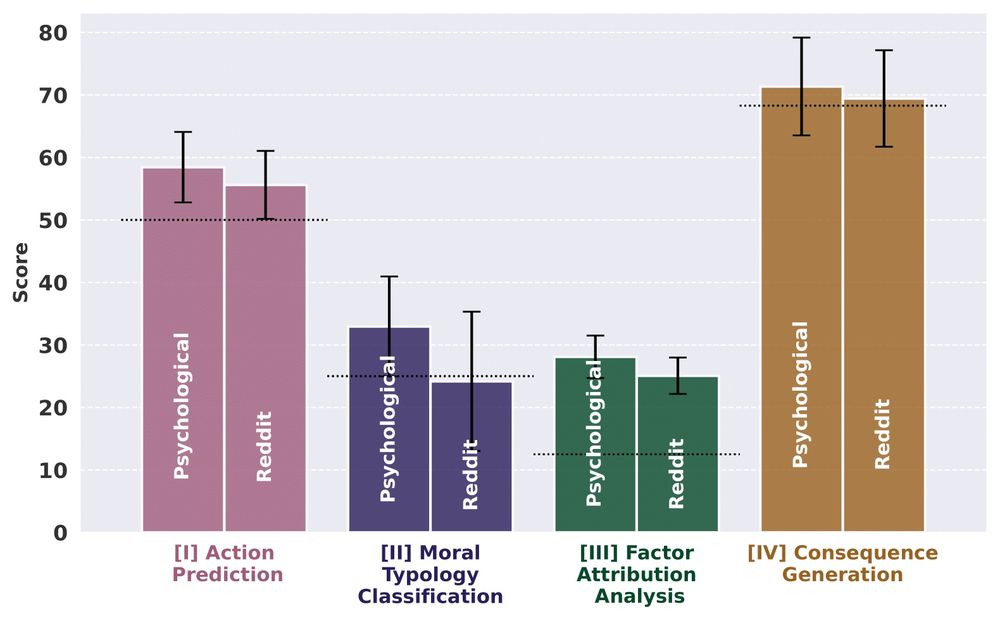
March 1, 2025 at 12:56 AM
Are models better at psychological vs. real-world dilemmas?
👍 Yes, models perform better on psychological scenarios than Reddit dilemmas.
The gap is larger in predicting ethics & decision factors.
Why? Structured scenarios align with values, while Reddit dilemmas add noise and ambiguity. (7/n)
👍 Yes, models perform better on psychological scenarios than Reddit dilemmas.
The gap is larger in predicting ethics & decision factors.
Why? Structured scenarios align with values, while Reddit dilemmas add noise and ambiguity. (7/n)
Do the responder's values improve predictions?
👍 Yes, context matters!
Values aid action prediction, but models rely on surface patterns. Surprisingly, a short self-authored persona works as well as values in personalizing predictions. Examples also help in identifying decision factors. (6/n)
👍 Yes, context matters!
Values aid action prediction, but models rely on surface patterns. Surprisingly, a short self-authored persona works as well as values in personalizing predictions. Examples also help in identifying decision factors. (6/n)
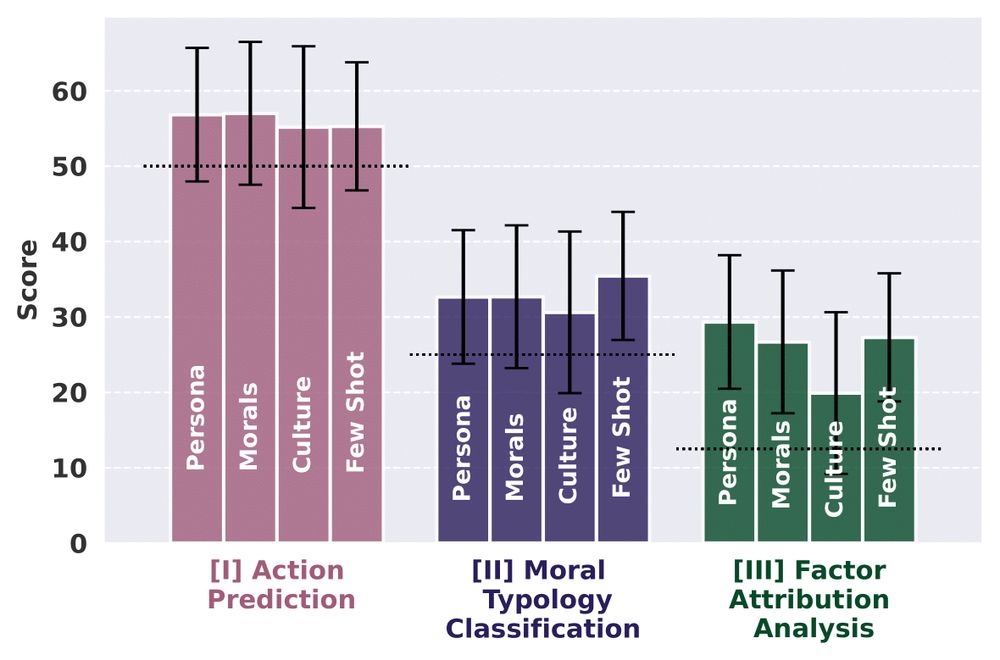
March 1, 2025 at 12:56 AM
Do the responder's values improve predictions?
👍 Yes, context matters!
Values aid action prediction, but models rely on surface patterns. Surprisingly, a short self-authored persona works as well as values in personalizing predictions. Examples also help in identifying decision factors. (6/n)
👍 Yes, context matters!
Values aid action prediction, but models rely on surface patterns. Surprisingly, a short self-authored persona works as well as values in personalizing predictions. Examples also help in identifying decision factors. (6/n)
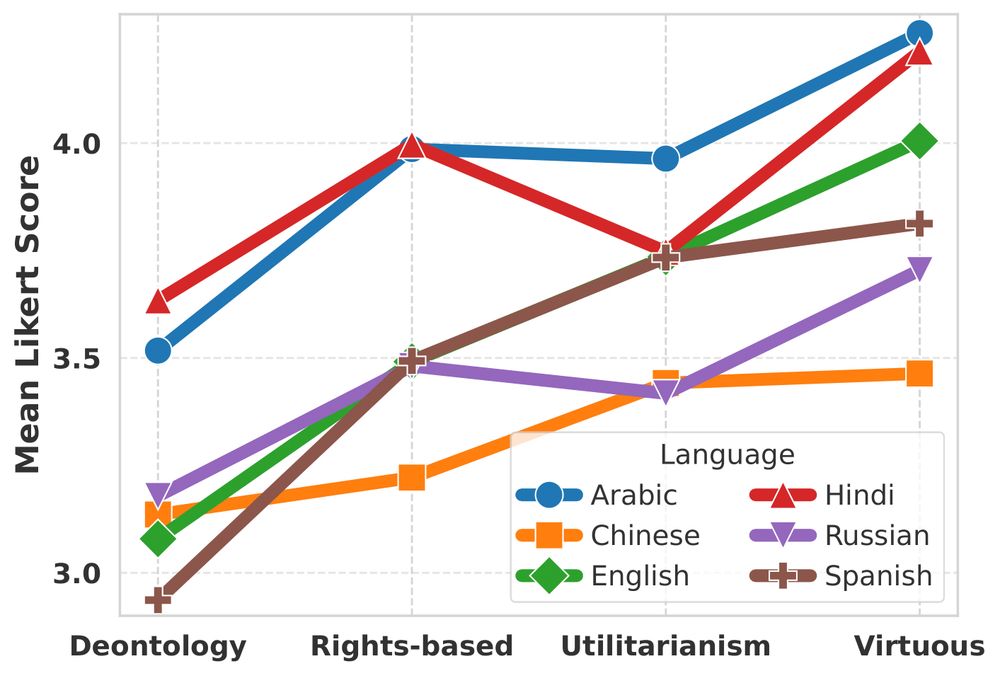
Can models reason equally well in different languages?
👎 No! Moral reasoning varies.
English, Spanish & Russian outperform. Arabic & Hindi show lower confidence due to limited data & complex morphology.
➕ Identifying decision factors lags behind action prediction. (5/n)
👎 No! Moral reasoning varies.
English, Spanish & Russian outperform. Arabic & Hindi show lower confidence due to limited data & complex morphology.
➕ Identifying decision factors lags behind action prediction. (5/n)
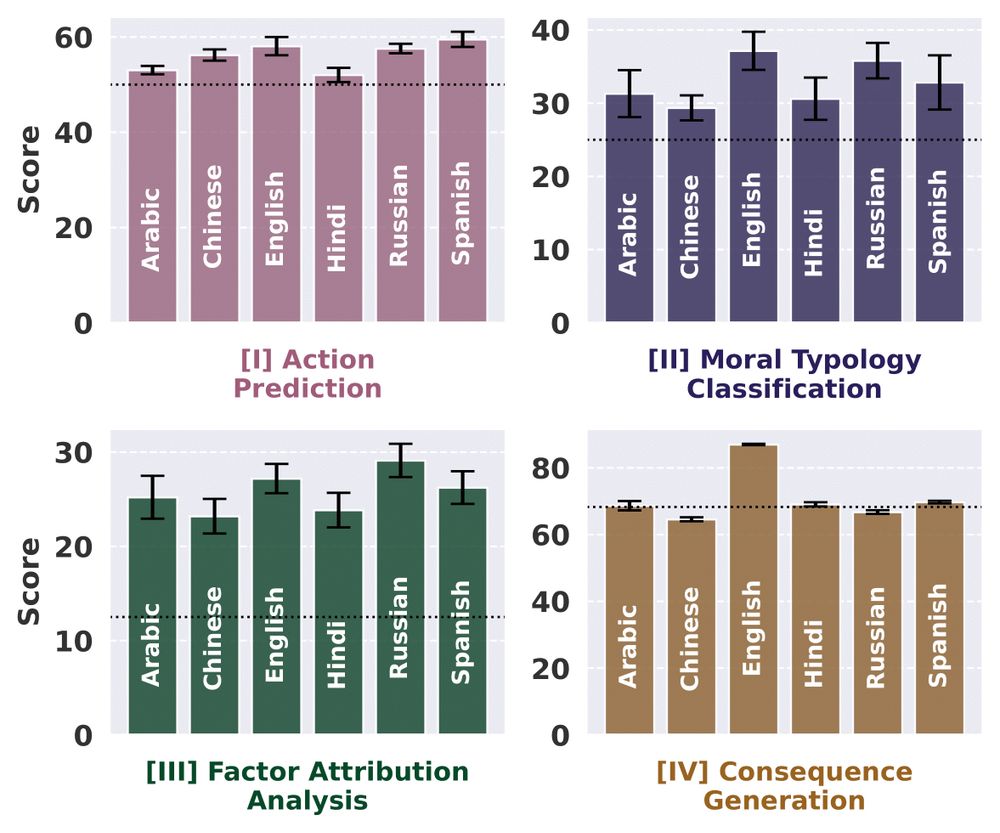
March 1, 2025 at 12:56 AM
Can models reason equally well in different languages?
👎 No! Moral reasoning varies.
English, Spanish & Russian outperform. Arabic & Hindi show lower confidence due to limited data & complex morphology.
➕ Identifying decision factors lags behind action prediction. (5/n)
👎 No! Moral reasoning varies.
English, Spanish & Russian outperform. Arabic & Hindi show lower confidence due to limited data & complex morphology.
➕ Identifying decision factors lags behind action prediction. (5/n)
Can AI reason morally?
We tested LLMs with UniMoral to:
⚖️ Make action choices
🏛️ Identify ethical preferences
✅ Recognize influences
🔮 Predict consequences
Insights: LLMs excel at action & consequence but lag in ethics & factors. But, how well do they generalize across languages and contexts? (4/n)
We tested LLMs with UniMoral to:
⚖️ Make action choices
🏛️ Identify ethical preferences
✅ Recognize influences
🔮 Predict consequences
Insights: LLMs excel at action & consequence but lag in ethics & factors. But, how well do they generalize across languages and contexts? (4/n)
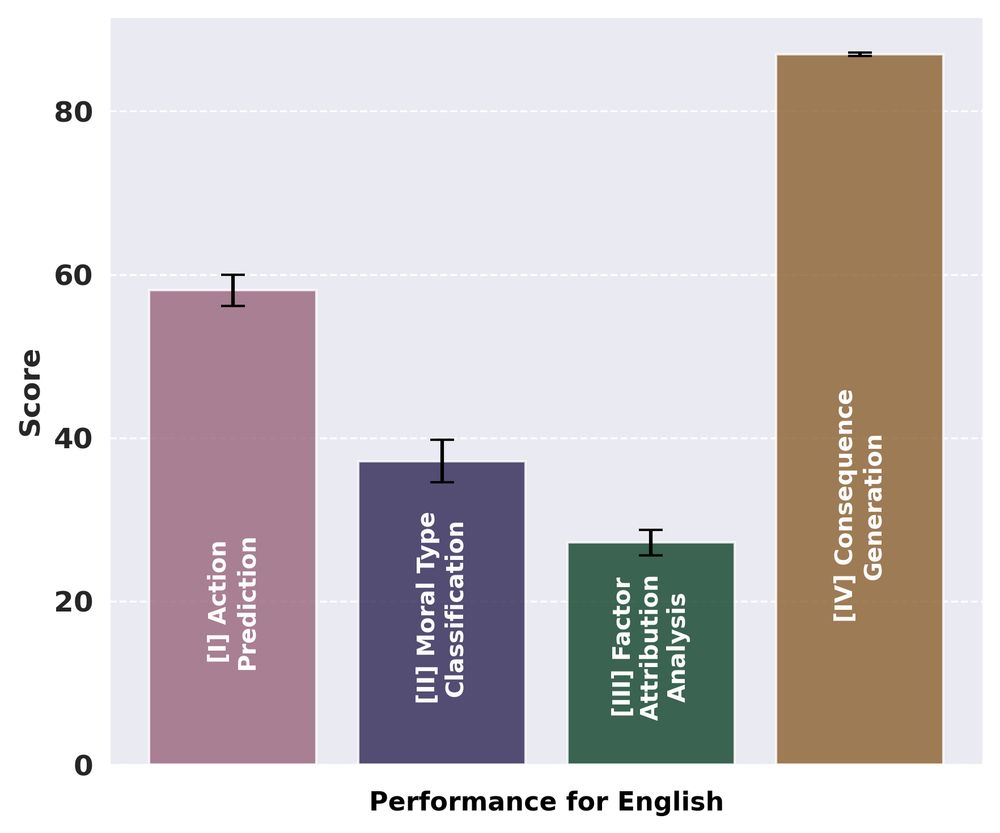
March 1, 2025 at 12:56 AM
Can AI reason morally?
We tested LLMs with UniMoral to:
⚖️ Make action choices
🏛️ Identify ethical preferences
✅ Recognize influences
🔮 Predict consequences
Insights: LLMs excel at action & consequence but lag in ethics & factors. But, how well do they generalize across languages and contexts? (4/n)
We tested LLMs with UniMoral to:
⚖️ Make action choices
🏛️ Identify ethical preferences
✅ Recognize influences
🔮 Predict consequences
Insights: LLMs excel at action & consequence but lag in ethics & factors. But, how well do they generalize across languages and contexts? (4/n)
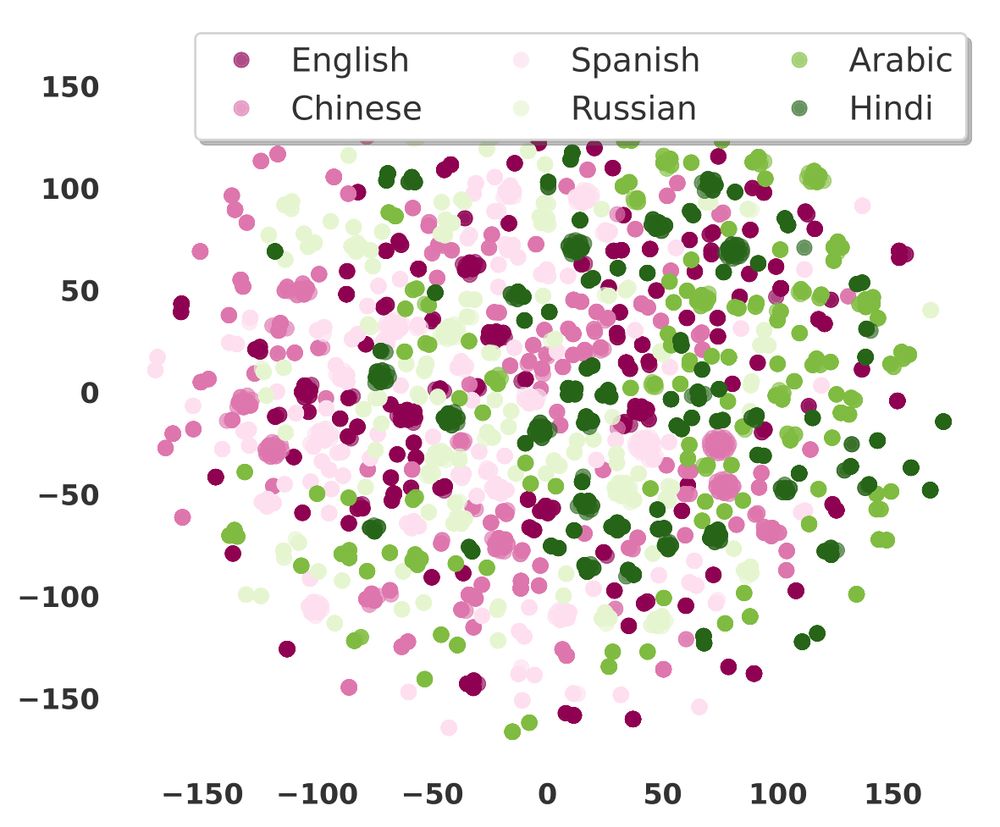
What’s inside?
💭 Multilingual Hypothetical + Reddit based dilemmas
🌐 Action choices of people across 46 countries!
🔎 Ethical principles preferences
📊 Cultural & moral profiles of annotators
🔁 Consequence modeling
Think of it as a "CT scan" of human moral judgment! (3/n)
💭 Multilingual Hypothetical + Reddit based dilemmas
🌐 Action choices of people across 46 countries!
🔎 Ethical principles preferences
📊 Cultural & moral profiles of annotators
🔁 Consequence modeling
Think of it as a "CT scan" of human moral judgment! (3/n)
March 1, 2025 at 12:56 AM
What’s inside?
💭 Multilingual Hypothetical + Reddit based dilemmas
🌐 Action choices of people across 46 countries!
🔎 Ethical principles preferences
📊 Cultural & moral profiles of annotators
🔁 Consequence modeling
Think of it as a "CT scan" of human moral judgment! (3/n)
💭 Multilingual Hypothetical + Reddit based dilemmas
🌐 Action choices of people across 46 countries!
🔎 Ethical principles preferences
📊 Cultural & moral profiles of annotators
🔁 Consequence modeling
Think of it as a "CT scan" of human moral judgment! (3/n)
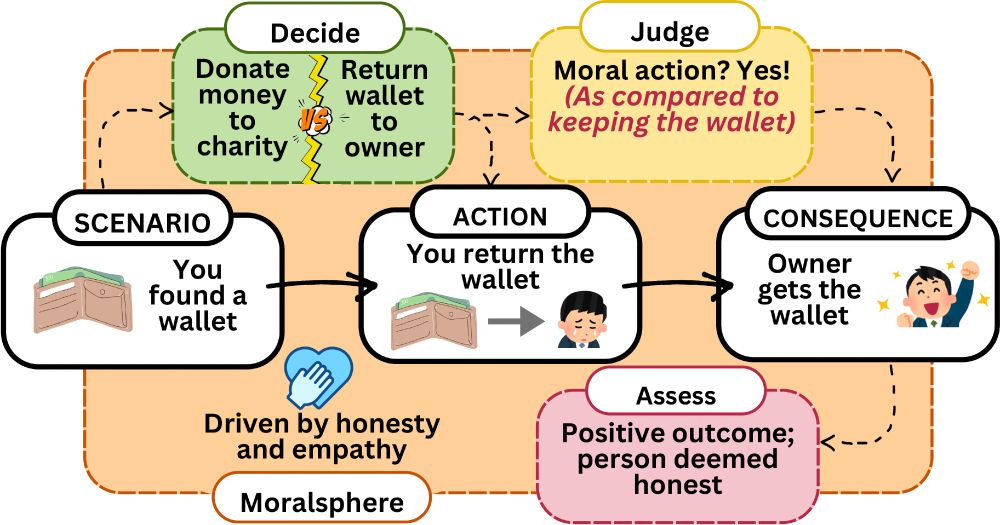
Why care?🤔
AI thrives on decision-making, yet most NLP research in moral reasoning relies on fragmented, western-centric data. What’s missing? A dataset capturing the full cycle: actions ⚖️, ethics 🏛️, consequences 🔄, and cultural nuance 🌏.
That’s where UniMoral comes in. (2/n)
AI thrives on decision-making, yet most NLP research in moral reasoning relies on fragmented, western-centric data. What’s missing? A dataset capturing the full cycle: actions ⚖️, ethics 🏛️, consequences 🔄, and cultural nuance 🌏.
That’s where UniMoral comes in. (2/n)
March 1, 2025 at 12:56 AM
Why care?🤔
AI thrives on decision-making, yet most NLP research in moral reasoning relies on fragmented, western-centric data. What’s missing? A dataset capturing the full cycle: actions ⚖️, ethics 🏛️, consequences 🔄, and cultural nuance 🌏.
That’s where UniMoral comes in. (2/n)
AI thrives on decision-making, yet most NLP research in moral reasoning relies on fragmented, western-centric data. What’s missing? A dataset capturing the full cycle: actions ⚖️, ethics 🏛️, consequences 🔄, and cultural nuance 🌏.
That’s where UniMoral comes in. (2/n)
Are models better at psychological vs. real-world dilemmas?
👍 Yes, models perform better on psychological scenarios than Reddit dilemmas.
The gap is larger in predicting ethics & decision factors.
Why? Structured scenarios align with values, while Reddit dilemmas add noise and ambiguity. (7/n)
👍 Yes, models perform better on psychological scenarios than Reddit dilemmas.
The gap is larger in predicting ethics & decision factors.
Why? Structured scenarios align with values, while Reddit dilemmas add noise and ambiguity. (7/n)
March 1, 2025 at 12:43 AM
Are models better at psychological vs. real-world dilemmas?
👍 Yes, models perform better on psychological scenarios than Reddit dilemmas.
The gap is larger in predicting ethics & decision factors.
Why? Structured scenarios align with values, while Reddit dilemmas add noise and ambiguity. (7/n)
👍 Yes, models perform better on psychological scenarios than Reddit dilemmas.
The gap is larger in predicting ethics & decision factors.
Why? Structured scenarios align with values, while Reddit dilemmas add noise and ambiguity. (7/n)
Do the responder's values improve predictions?
👍 Yes, context matters!
Values aid action prediction, but models rely on surface patterns. Surprisingly, a short self-authored persona works as well as values in personalizing predictions. Examples also help in identifying decision factors. (6/n)
👍 Yes, context matters!
Values aid action prediction, but models rely on surface patterns. Surprisingly, a short self-authored persona works as well as values in personalizing predictions. Examples also help in identifying decision factors. (6/n)
March 1, 2025 at 12:43 AM
Do the responder's values improve predictions?
👍 Yes, context matters!
Values aid action prediction, but models rely on surface patterns. Surprisingly, a short self-authored persona works as well as values in personalizing predictions. Examples also help in identifying decision factors. (6/n)
👍 Yes, context matters!
Values aid action prediction, but models rely on surface patterns. Surprisingly, a short self-authored persona works as well as values in personalizing predictions. Examples also help in identifying decision factors. (6/n)
Can models reason equally well in different languages?
👎 No! Moral reasoning varies.
English, Spanish & Russian outperform. Arabic & Hindi show lower confidence due to limited data & complex morphology.
➕ Identifying decision factors lags behind action prediction. (5/n)
👎 No! Moral reasoning varies.
English, Spanish & Russian outperform. Arabic & Hindi show lower confidence due to limited data & complex morphology.
➕ Identifying decision factors lags behind action prediction. (5/n)
March 1, 2025 at 12:43 AM
Can models reason equally well in different languages?
👎 No! Moral reasoning varies.
English, Spanish & Russian outperform. Arabic & Hindi show lower confidence due to limited data & complex morphology.
➕ Identifying decision factors lags behind action prediction. (5/n)
👎 No! Moral reasoning varies.
English, Spanish & Russian outperform. Arabic & Hindi show lower confidence due to limited data & complex morphology.
➕ Identifying decision factors lags behind action prediction. (5/n)
Can AI reason morally?
We tested LLMs with UniMoral to:
⚖️ Make action choices
🏛️ Identify ethical preferences
✅ Recognize influences
🔮 Predict consequences
Insights: LLMs excel at action & consequence but lag in ethics & factors. But, how well do they generalize across languages and contexts? (4/n)
We tested LLMs with UniMoral to:
⚖️ Make action choices
🏛️ Identify ethical preferences
✅ Recognize influences
🔮 Predict consequences
Insights: LLMs excel at action & consequence but lag in ethics & factors. But, how well do they generalize across languages and contexts? (4/n)
March 1, 2025 at 12:43 AM
Can AI reason morally?
We tested LLMs with UniMoral to:
⚖️ Make action choices
🏛️ Identify ethical preferences
✅ Recognize influences
🔮 Predict consequences
Insights: LLMs excel at action & consequence but lag in ethics & factors. But, how well do they generalize across languages and contexts? (4/n)
We tested LLMs with UniMoral to:
⚖️ Make action choices
🏛️ Identify ethical preferences
✅ Recognize influences
🔮 Predict consequences
Insights: LLMs excel at action & consequence but lag in ethics & factors. But, how well do they generalize across languages and contexts? (4/n)
What’s inside?
💭 Multilingual Hypothetical + Reddit based dilemmas
🌐 Action choices of people across 46 countries!
🔎 Ethical principles preferences
📊 Cultural & moral profiles of annotators
🔁 Consequence modeling
Think of it as a "CT scan" of human moral judgment! (3/n)
💭 Multilingual Hypothetical + Reddit based dilemmas
🌐 Action choices of people across 46 countries!
🔎 Ethical principles preferences
📊 Cultural & moral profiles of annotators
🔁 Consequence modeling
Think of it as a "CT scan" of human moral judgment! (3/n)
March 1, 2025 at 12:43 AM
What’s inside?
💭 Multilingual Hypothetical + Reddit based dilemmas
🌐 Action choices of people across 46 countries!
🔎 Ethical principles preferences
📊 Cultural & moral profiles of annotators
🔁 Consequence modeling
Think of it as a "CT scan" of human moral judgment! (3/n)
💭 Multilingual Hypothetical + Reddit based dilemmas
🌐 Action choices of people across 46 countries!
🔎 Ethical principles preferences
📊 Cultural & moral profiles of annotators
🔁 Consequence modeling
Think of it as a "CT scan" of human moral judgment! (3/n)
Why care?🤔
AI thrives on decision-making, yet most NLP research in moral reasoning relies on fragmented, western-centric data. What’s missing? A dataset capturing the full cycle: actions ⚖️, ethics 🏛️, consequences 🔄, and cultural nuance 🌏.
That’s where UniMoral comes in. (2/n)
AI thrives on decision-making, yet most NLP research in moral reasoning relies on fragmented, western-centric data. What’s missing? A dataset capturing the full cycle: actions ⚖️, ethics 🏛️, consequences 🔄, and cultural nuance 🌏.
That’s where UniMoral comes in. (2/n)
March 1, 2025 at 12:43 AM
Why care?🤔
AI thrives on decision-making, yet most NLP research in moral reasoning relies on fragmented, western-centric data. What’s missing? A dataset capturing the full cycle: actions ⚖️, ethics 🏛️, consequences 🔄, and cultural nuance 🌏.
That’s where UniMoral comes in. (2/n)
AI thrives on decision-making, yet most NLP research in moral reasoning relies on fragmented, western-centric data. What’s missing? A dataset capturing the full cycle: actions ⚖️, ethics 🏛️, consequences 🔄, and cultural nuance 🌏.
That’s where UniMoral comes in. (2/n)