



Shauli Ravfogel
@shauli.bsky.social
Faculty fellow at NYU CDS. Previously: PhD @ BIU NLP.
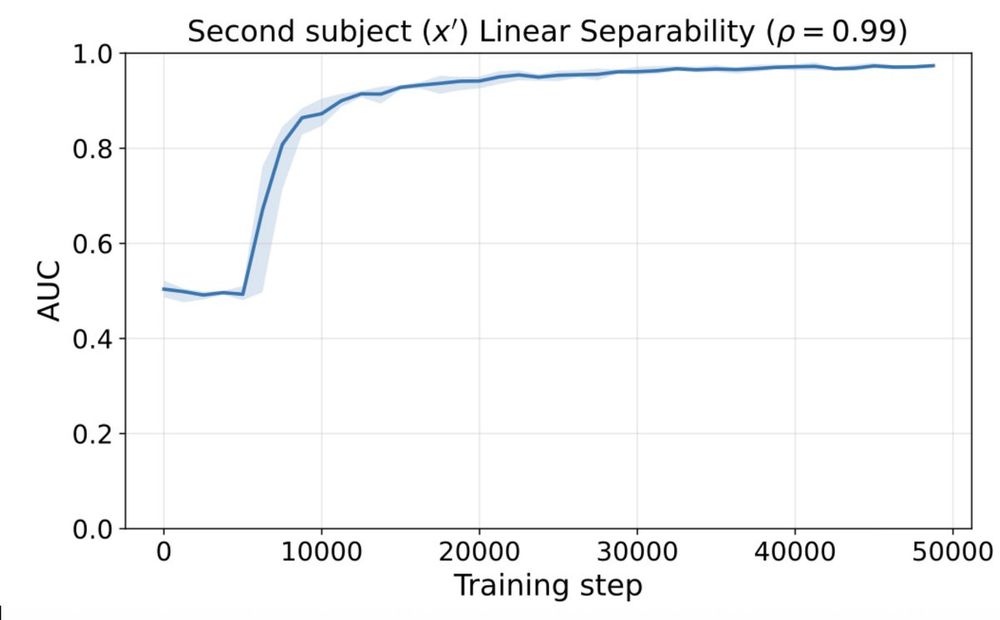
We show that a similar phenomenon is reproduced when using natural language data, instead of our synthetic data, although in “real”, pretrained LMs, the layer normalization doesn’t seem to play such an important role in inducing linear separability.
October 24, 2025 at 3:19 PM
We show that a similar phenomenon is reproduced when using natural language data, instead of our synthetic data, although in “real”, pretrained LMs, the layer normalization doesn’t seem to play such an important role in inducing linear separability.
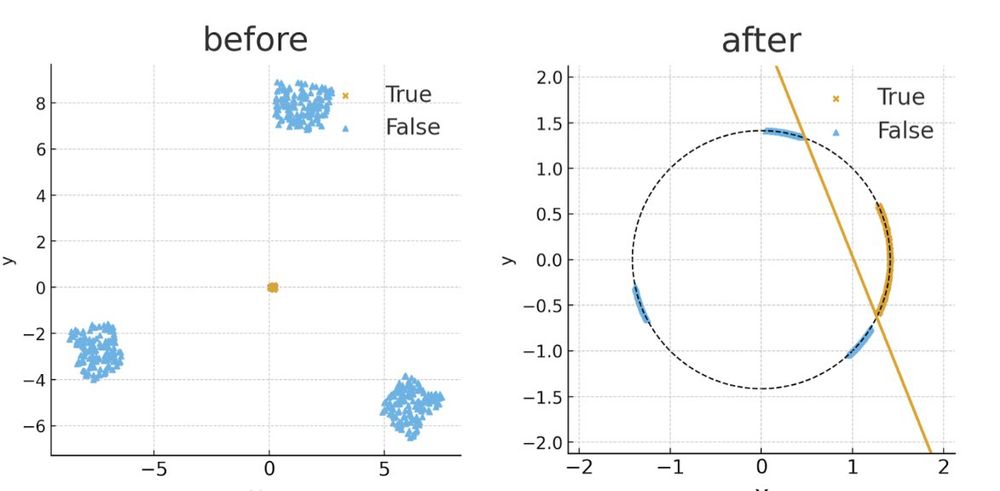
*Assuming* this structure, we prove that (1) the model represents truth linearly; (2) confidence on the false sequence is decreased. This mechanism relies on a difference in norm between true and false sequence, that the layer normalization translates to linear separability.
October 24, 2025 at 3:19 PM
*Assuming* this structure, we prove that (1) the model represents truth linearly; (2) confidence on the false sequence is decreased. This mechanism relies on a difference in norm between true and false sequence, that the layer normalization translates to linear separability.
An analysis of the first gradient steps also predicts the gradual emergence of this structure, with the block corresponding to memorization appearing first, followed by the block that gives rise to linear separability and confidence modulation.

October 24, 2025 at 3:19 PM
An analysis of the first gradient steps also predicts the gradual emergence of this structure, with the block corresponding to memorization appearing first, followed by the block that gives rise to linear separability and confidence modulation.
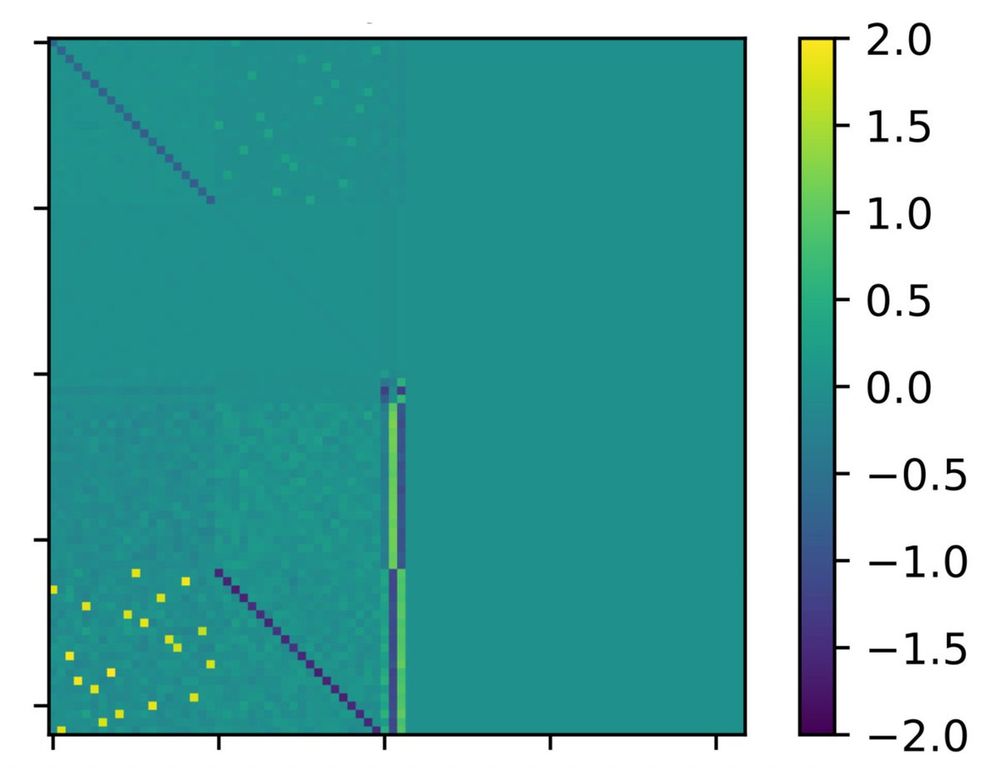
To understand the emergence, we study the structure of the attention matrix. It turns out that it is highly structured, with blocks corresponding to mapping subjects to attributes (lower left), attributes to subjects (upper middle), and additional ones.
October 24, 2025 at 3:19 PM
To understand the emergence, we study the structure of the attention matrix. It turns out that it is highly structured, with blocks corresponding to mapping subjects to attributes (lower left), attributes to subjects (upper middle), and additional ones.
False sequences contain a uniform attribute (instead of the memorized one), so the ideal behavior on them is to output a uniform guess. We see that the probability the model allocates to the memorized attribute starts dropping *exactly* when the linear truth signal emerges.

October 24, 2025 at 3:19 PM
False sequences contain a uniform attribute (instead of the memorized one), so the ideal behavior on them is to output a uniform guess. We see that the probability the model allocates to the memorized attribute starts dropping *exactly* when the linear truth signal emerges.
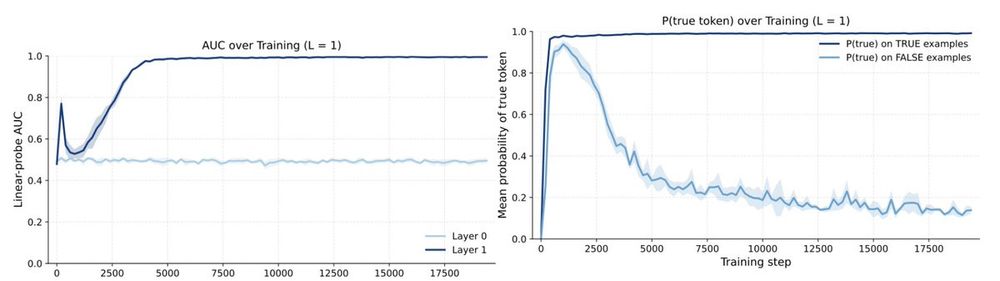
We train a simplified transformer model on this task, with a single layer and a single attention head. We see an abrupt emergence of linear separability of the hidden representations by factuality.
October 24, 2025 at 3:19 PM
We train a simplified transformer model on this task, with a single layer and a single attention head. We see an abrupt emergence of linear separability of the hidden representations by factuality.
We start with a “truth co-occurrence" hypothesis: false assertions tend to co-occur. Thus, LMs are incentivized to infer the truth latent variable to reduce future loss. We define a factual recall task, where each instance contains two sequences, whose truthfulness correlates.

October 24, 2025 at 3:19 PM
We start with a “truth co-occurrence" hypothesis: false assertions tend to co-occur. Thus, LMs are incentivized to infer the truth latent variable to reduce future loss. We define a factual recall task, where each instance contains two sequences, whose truthfulness correlates.
New NeurIPS paper! Why do LMs represent concepts linearly? We focus on LMs's tendency to linearly separate true and false assertions, and provide an analysis of the truth circuit in a toy model. A joint work with Gilad Yehudai, @tallinzen.bsky.social, Joan Bruna and @albertobietti.bsky.social.

October 24, 2025 at 3:19 PM
New NeurIPS paper! Why do LMs represent concepts linearly? We focus on LMs's tendency to linearly separate true and false assertions, and provide an analysis of the truth circuit in a toy model. A joint work with Gilad Yehudai, @tallinzen.bsky.social, Joan Bruna and @albertobietti.bsky.social.
7/8 This factor space lets us (i) flag benchmarks that add little new information, (ii) predict a new model’s full profile from a small task subset, and (iii) choose the best model for an unseen task with minimal trials.

July 31, 2025 at 12:37 PM
7/8 This factor space lets us (i) flag benchmarks that add little new information, (ii) predict a new model’s full profile from a small task subset, and (iii) choose the best model for an unseen task with minimal trials.
6/8 From this analysis, eight main latent skills emerge—e.g., General NLU, Long-document comprehension, Precision-sensitive answers—allowing each model to receive a more fine-grained skill profile instead of one aggregated number.

July 31, 2025 at 12:37 PM
6/8 From this analysis, eight main latent skills emerge—e.g., General NLU, Long-document comprehension, Precision-sensitive answers—allowing each model to receive a more fine-grained skill profile instead of one aggregated number.
5/8 Using Principal-Axis Factoring, we separate shared variance (true shared skills) from task-specific noise, yielding an interpretable low-dimensional latent space.

July 31, 2025 at 12:37 PM
5/8 Using Principal-Axis Factoring, we separate shared variance (true shared skills) from task-specific noise, yielding an interpretable low-dimensional latent space.
1/8 Happy to share our new paper—“IQ Test for LLMs”—co-authored with Aviya Maimon, Amir DN Cohen, @neurogal.bsky.social and Reut Tsarfaty. We propose to rethink how language models are evaluated by focusing on the latent capabilities that explain benchmark results.
Arxiv: arxiv.org/pdf/2507.20208
Arxiv: arxiv.org/pdf/2507.20208

July 31, 2025 at 12:37 PM
1/8 Happy to share our new paper—“IQ Test for LLMs”—co-authored with Aviya Maimon, Amir DN Cohen, @neurogal.bsky.social and Reut Tsarfaty. We propose to rethink how language models are evaluated by focusing on the latent capabilities that explain benchmark results.
Arxiv: arxiv.org/pdf/2507.20208
Arxiv: arxiv.org/pdf/2507.20208
We also demonstrate that the generated counterfactuals can be used for data augmentation, helping the model become more invariant to sensitive features. (5/6)

February 12, 2025 at 3:19 PM
We also demonstrate that the generated counterfactuals can be used for data augmentation, helping the model become more invariant to sensitive features. (5/6)
Focusing on intervening in the gender concept, we find that the intervention causes changes beyond explicit markers such as pronouns, demonstrating *which* biases are encoded in the representation, and explicitly presenting them in natural language. (4/6)

February 12, 2025 at 3:19 PM
Focusing on intervening in the gender concept, we find that the intervention causes changes beyond explicit markers such as pronouns, demonstrating *which* biases are encoded in the representation, and explicitly presenting them in natural language. (4/6)
Many techniques have been proposed to intervene in the high-dimensional representation space of language models. However, it's difficult to understand which features are being modified, and how. Our goal is to translate those intervened representations back into natural language. (2/6)

February 12, 2025 at 3:19 PM
Many techniques have been proposed to intervene in the high-dimensional representation space of language models. However, it's difficult to understand which features are being modified, and how. Our goal is to translate those intervened representations back into natural language. (2/6)
Our paper "A Practical Method for Generating String Counterfactuals" has been accepted to the findings of NAACL 2025! a joint work with @matan-avitan.bsky.social , @yoavgo.bsky.social and Ryan Cotterell. We propose "Intervention Lens", a technique to explain intervention in natural language. (1/6)

February 12, 2025 at 3:19 PM
Our paper "A Practical Method for Generating String Counterfactuals" has been accepted to the findings of NAACL 2025! a joint work with @matan-avitan.bsky.social , @yoavgo.bsky.social and Ryan Cotterell. We propose "Intervention Lens", a technique to explain intervention in natural language. (1/6)
A quick update: I’ve completed my PhD at Bar-Ilan University. After an amazing research visit in Prof. Ryan Cotterell’s lab at ETH Zurich, I am super excited to join NYU Center for Data Science as a Faculty Fellow!

December 30, 2024 at 3:22 PM
A quick update: I’ve completed my PhD at Bar-Ilan University. After an amazing research visit in Prof. Ryan Cotterell’s lab at ETH Zurich, I am super excited to join NYU Center for Data Science as a Faculty Fellow!
We show that even minor interventions can cause unintended effects. Experiments reveal that techniques like knowledge editing or linear steering often impact unrelated aspects, leading to semantic drift where counterfactuals share only a small prefix with the original. (5/7)

November 12, 2024 at 4:00 PM
We show that even minor interventions can cause unintended effects. Experiments reveal that techniques like knowledge editing or linear steering often impact unrelated aspects, leading to semantic drift where counterfactuals share only a small prefix with the original. (5/7)
Leveraging the Gumbel-max trick and hindsight sampling, we propose an algorithm for counterfactual generation, conditioning on an observed string. This allows us to create minimal pairs to test if interventions target specific features or introduce unintended side effects. (4/7)

November 12, 2024 at 4:00 PM
Leveraging the Gumbel-max trick and hindsight sampling, we propose an algorithm for counterfactual generation, conditioning on an observed string. This allows us to create minimal pairs to test if interventions target specific features or introduce unintended side effects. (4/7)
By reformulating LMs as generalized structural-equation models, we control the randomness in the generation, ensuring that the intervention in the model is the only induced change. This allows us to define a joint distribution over (original, counterfactual) string pairs. (3/7)

November 12, 2024 at 4:00 PM
By reformulating LMs as generalized structural-equation models, we control the randomness in the generation, ensuring that the intervention in the model is the only induced change. This allows us to define a joint distribution over (original, counterfactual) string pairs. (3/7)
Interventions allow us to induce changes in LMs, but counterfactuals—at Pearl’s highest causal level—reveal how interventions change outputs. These are often conflated. We clarify this distinction and introduce a framework to generate true counterfactuals directly from LMs. (2/7)

November 12, 2024 at 4:00 PM
Interventions allow us to induce changes in LMs, but counterfactuals—at Pearl’s highest causal level—reveal how interventions change outputs. These are often conflated. We clarify this distinction and introduce a framework to generate true counterfactuals directly from LMs. (2/7)
Happy to share our work "Counterfactual Generation from Language Models" with @AnejSvete, @vesteinns, and Ryan Cotterell! We tackle generating true counterfactual strings from LMs after interventions and introduce a simple algorithm for it. (1/7) arxiv.org/pdf/2411.07180

November 12, 2024 at 4:00 PM
Happy to share our work "Counterfactual Generation from Language Models" with @AnejSvete, @vesteinns, and Ryan Cotterell! We tackle generating true counterfactual strings from LMs after interventions and introduce a simple algorithm for it. (1/7) arxiv.org/pdf/2411.07180