




Shaily
@shaily99.bsky.social
PhDing at LTI, CMU
Prev: Ai2, Google Research, MSR
Evaluating language technologies, regularly ranting, and probably procrastinating.
https://sites.google.com/view/shailybhatt/
Prev: Ai2, Google Research, MSR
Evaluating language technologies, regularly ranting, and probably procrastinating.
https://sites.google.com/view/shailybhatt/
Given the growing use of LLMs in scientific processes, we tested their ability to adapt writing across communities.
They adapt jargon 😀
BUT shift all other metrics in one direction (e.g shorter length, less formal) ☹️
‼️ TLDR: homogenised writing across cultures, not adaptation.
[7/11]
They adapt jargon 😀
BUT shift all other metrics in one direction (e.g shorter length, less formal) ☹️
‼️ TLDR: homogenised writing across cultures, not adaptation.
[7/11]

June 9, 2025 at 11:30 PM
Given the growing use of LLMs in scientific processes, we tested their ability to adapt writing across communities.
They adapt jargon 😀
BUT shift all other metrics in one direction (e.g shorter length, less formal) ☹️
‼️ TLDR: homogenised writing across cultures, not adaptation.
[7/11]
They adapt jargon 😀
BUT shift all other metrics in one direction (e.g shorter length, less formal) ☹️
‼️ TLDR: homogenised writing across cultures, not adaptation.
[7/11]
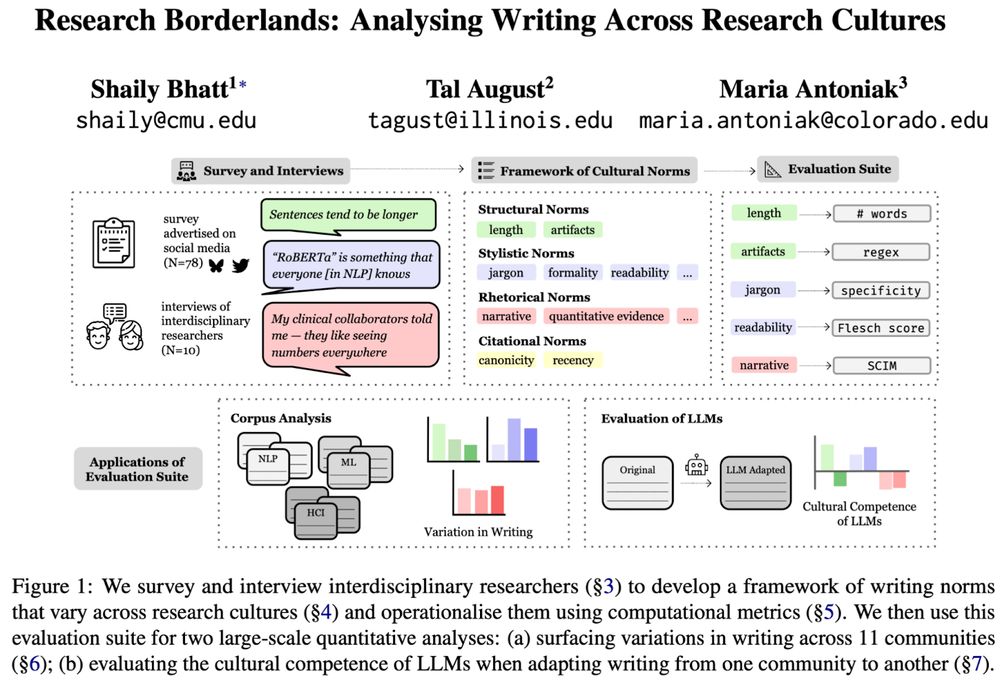
We analyzed 81K+ papers from 11 CS communities—recovering patterns our interviewees described. For example:
🖼️ Computer Vision loves figures (shocking!)
🧑🏫 Education has the most distinctive vocabulary
📈 ML/NLP emphasize "quantitative evidence" (we love our bold numbers!)
[6/11]
🖼️ Computer Vision loves figures (shocking!)
🧑🏫 Education has the most distinctive vocabulary
📈 ML/NLP emphasize "quantitative evidence" (we love our bold numbers!)
[6/11]

June 9, 2025 at 11:30 PM
We analyzed 81K+ papers from 11 CS communities—recovering patterns our interviewees described. For example:
🖼️ Computer Vision loves figures (shocking!)
🧑🏫 Education has the most distinctive vocabulary
📈 ML/NLP emphasize "quantitative evidence" (we love our bold numbers!)
[6/11]
🖼️ Computer Vision loves figures (shocking!)
🧑🏫 Education has the most distinctive vocabulary
📈 ML/NLP emphasize "quantitative evidence" (we love our bold numbers!)
[6/11]
We then operationalise this framework using computational metrics and create an 🛠️ evaluation suite 🛠️.
This suite can be used to analyse both human-written research papers as well as LLM-generated text.
[5/11]
This suite can be used to analyse both human-written research papers as well as LLM-generated text.
[5/11]

June 9, 2025 at 11:30 PM
We then operationalise this framework using computational metrics and create an 🛠️ evaluation suite 🛠️.
This suite can be used to analyse both human-written research papers as well as LLM-generated text.
[5/11]
This suite can be used to analyse both human-written research papers as well as LLM-generated text.
[5/11]
Their insights led to a ✨framework of research cultural norms ✨ spanning four categories:
🏗️ Structural (length, figures/tables)
🕺 Stylistic (jargon, formality, readability)
⚖️ Rhetorical (evidence, framing, narrative flow)
📖 Citational (who is cited, how)
[4/11]
🏗️ Structural (length, figures/tables)
🕺 Stylistic (jargon, formality, readability)
⚖️ Rhetorical (evidence, framing, narrative flow)
📖 Citational (who is cited, how)
[4/11]

June 9, 2025 at 11:30 PM
Their insights led to a ✨framework of research cultural norms ✨ spanning four categories:
🏗️ Structural (length, figures/tables)
🕺 Stylistic (jargon, formality, readability)
⚖️ Rhetorical (evidence, framing, narrative flow)
📖 Citational (who is cited, how)
[4/11]
🏗️ Structural (length, figures/tables)
🕺 Stylistic (jargon, formality, readability)
⚖️ Rhetorical (evidence, framing, narrative flow)
📖 Citational (who is cited, how)
[4/11]
Ever had an R2 say “this doesn’t sound like an ACL paper”? You’re not alone.
As an interviewee said:
🗣️ “There's a way to write ... that makes it way more likely a paper with the same results gets accepted or not.”
What are these tacit cultural norms and can LLMs follow them?
[2/11]
As an interviewee said:
🗣️ “There's a way to write ... that makes it way more likely a paper with the same results gets accepted or not.”
What are these tacit cultural norms and can LLMs follow them?
[2/11]

June 9, 2025 at 11:30 PM
Ever had an R2 say “this doesn’t sound like an ACL paper”? You’re not alone.
As an interviewee said:
🗣️ “There's a way to write ... that makes it way more likely a paper with the same results gets accepted or not.”
What are these tacit cultural norms and can LLMs follow them?
[2/11]
As an interviewee said:
🗣️ “There's a way to write ... that makes it way more likely a paper with the same results gets accepted or not.”
What are these tacit cultural norms and can LLMs follow them?
[2/11]
🖋️ Curious how writing differs across (research) cultures?
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
June 9, 2025 at 11:30 PM
🖋️ Curious how writing differs across (research) cultures?
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
Now even I can tell my kids: "street light ke niche jake padhte the"
#pittsburghstorm #36hrslater
(The ghost town is my street).
#pittsburghstorm #36hrslater
(The ghost town is my street).
May 1, 2025 at 3:08 AM
Now even I can tell my kids: "street light ke niche jake padhte the"
#pittsburghstorm #36hrslater
(The ghost town is my street).
#pittsburghstorm #36hrslater
(The ghost town is my street).
I'm just saying, it's not wrong; especially when you have to debug it.

February 13, 2025 at 12:11 AM
I'm just saying, it's not wrong; especially when you have to debug it.
This is a good start!! More *CL conferences should come 😍
@aaclmeeting.bsky.social
@aaclmeeting.bsky.social

February 1, 2025 at 1:32 PM
This is a good start!! More *CL conferences should come 😍
@aaclmeeting.bsky.social
@aaclmeeting.bsky.social
Attaching a partial screenshot of what a filled out version looked like when I used it for EMNLP.

November 23, 2024 at 4:07 PM
Attaching a partial screenshot of what a filled out version looked like when I used it for EMNLP.
Last, we find weak correlations between the text distribution of outputs and cultural values of countries used in intrinsic evals implying that intrinsic and extrinsic measures might not correlate.
This underscores the importance of evaluating models in user-facing tasks.
[6/7]
This underscores the importance of evaluating models in user-facing tasks.
[6/7]

November 9, 2024 at 5:24 PM
Last, we find weak correlations between the text distribution of outputs and cultural values of countries used in intrinsic evals implying that intrinsic and extrinsic measures might not correlate.
This underscores the importance of evaluating models in user-facing tasks.
[6/7]
This underscores the importance of evaluating models in user-facing tasks.
[6/7]
We see culturally relevant words:
✨ names (Raj🇮🇳, Tommy🇺🇲, Ali🇦🇫)
✨ artefacts (temple🇮🇳, bao🇨🇳)
and factually varying words:
✨ parliaments (Lok Sabha🇮🇳, Bundestag🇩🇪)
✨ political parties (BJP🇮🇳, NDP🇨🇦, PDP🇳🇬)
✨ polarised issues (brexit🇬🇧, gun🇺🇲)
etc.
[5/7]
✨ names (Raj🇮🇳, Tommy🇺🇲, Ali🇦🇫)
✨ artefacts (temple🇮🇳, bao🇨🇳)
and factually varying words:
✨ parliaments (Lok Sabha🇮🇳, Bundestag🇩🇪)
✨ political parties (BJP🇮🇳, NDP🇨🇦, PDP🇳🇬)
✨ polarised issues (brexit🇬🇧, gun🇺🇲)
etc.
[5/7]

November 9, 2024 at 5:24 PM
We see culturally relevant words:
✨ names (Raj🇮🇳, Tommy🇺🇲, Ali🇦🇫)
✨ artefacts (temple🇮🇳, bao🇨🇳)
and factually varying words:
✨ parliaments (Lok Sabha🇮🇳, Bundestag🇩🇪)
✨ political parties (BJP🇮🇳, NDP🇨🇦, PDP🇳🇬)
✨ polarised issues (brexit🇬🇧, gun🇺🇲)
etc.
[5/7]
✨ names (Raj🇮🇳, Tommy🇺🇲, Ali🇦🇫)
✨ artefacts (temple🇮🇳, bao🇨🇳)
and factually varying words:
✨ parliaments (Lok Sabha🇮🇳, Bundestag🇩🇪)
✨ political parties (BJP🇮🇳, NDP🇨🇦, PDP🇳🇬)
✨ polarised issues (brexit🇬🇧, gun🇺🇲)
etc.
[5/7]
Quantifying lexical variance in outputs, we find:
✨ Statistically significant variance across nationalities i.e., non-trivial adaptations.
✨ Higher variance in stories than QA, as the latter is more factual.
✨ More interquartile distance in QA due to more topic diversity.
[4/7]
✨ Statistically significant variance across nationalities i.e., non-trivial adaptations.
✨ Higher variance in stories than QA, as the latter is more factual.
✨ More interquartile distance in QA due to more topic diversity.
[4/7]

November 9, 2024 at 5:24 PM
Quantifying lexical variance in outputs, we find:
✨ Statistically significant variance across nationalities i.e., non-trivial adaptations.
✨ Higher variance in stories than QA, as the latter is more factual.
✨ More interquartile distance in QA due to more topic diversity.
[4/7]
✨ Statistically significant variance across nationalities i.e., non-trivial adaptations.
✨ Higher variance in stories than QA, as the latter is more factual.
✨ More interquartile distance in QA due to more topic diversity.
[4/7]
I will be at #EMNLP2024 presenting our work on "Extrinsic Evaluation of Cultural Competence in Large Language Models" in Poster Session 12 on Thursday 2-3:30 PM.
In this work we take the first steps towards asking whether LLMs can cater to diverse cultures in *user-facing generative* tasks.
[1/7]
In this work we take the first steps towards asking whether LLMs can cater to diverse cultures in *user-facing generative* tasks.
[1/7]

November 9, 2024 at 5:24 PM
I will be at #EMNLP2024 presenting our work on "Extrinsic Evaluation of Cultural Competence in Large Language Models" in Poster Session 12 on Thursday 2-3:30 PM.
In this work we take the first steps towards asking whether LLMs can cater to diverse cultures in *user-facing generative* tasks.
[1/7]
In this work we take the first steps towards asking whether LLMs can cater to diverse cultures in *user-facing generative* tasks.
[1/7]