




Sheridan Feucht
@sfeucht.bsky.social
PhD student doing LLM interpretability with @davidbau.bsky.social and @byron.bsky.social. (they/them) https://sfeucht.github.io
If we do the same for token induction heads, we can also get a "token lens", which reads out surface-level token information from states. Unlike raw logit lens, which reveals next-token predictions, "token lens" reveals the current token.

July 22, 2025 at 12:40 PM
If we do the same for token induction heads, we can also get a "token lens", which reads out surface-level token information from states. Unlike raw logit lens, which reveals next-token predictions, "token lens" reveals the current token.
If we apply concept lens to the word "cardinals" in three contexts, we see that Llama-2-7b has encoded this word very differently in each case!

July 22, 2025 at 12:40 PM
If we apply concept lens to the word "cardinals" in three contexts, we see that Llama-2-7b has encoded this word very differently in each case!
I'm on the train right now and just finished reading this paper for the first time--I actually just logged back on to bsky just so that I could link to it, but you beat me to the punch!
I really enjoyed your paper. This example was particularly great.
I really enjoyed your paper. This example was particularly great.

April 25, 2025 at 8:01 PM
I'm on the train right now and just finished reading this paper for the first time--I actually just logged back on to bsky just so that I could link to it, but you beat me to the punch!
I really enjoyed your paper. This example was particularly great.
I really enjoyed your paper. This example was particularly great.
Yin & Steinhardt (2025) recently showed that FV heads are more important for ICL than token induction heads. But for translation, *concept* induction heads matter too! They copy forward word meanings, whereas FV heads influence the output language.
bsky.app/profile/kay...
bsky.app/profile/kay...

April 7, 2025 at 1:54 PM
Yin & Steinhardt (2025) recently showed that FV heads are more important for ICL than token induction heads. But for translation, *concept* induction heads matter too! They copy forward word meanings, whereas FV heads influence the output language.
bsky.app/profile/kay...
bsky.app/profile/kay...
Concept heads also output language-agnostic word representations. If we patch the outputs of these heads from one translation prompt to another, we can change the *meaning* of the outputted word, without changing the language. (see prior work from @butanium.bsky.social and @wendlerc.bsky.social)

April 7, 2025 at 1:54 PM
Concept heads also output language-agnostic word representations. If we patch the outputs of these heads from one translation prompt to another, we can change the *meaning* of the outputted word, without changing the language. (see prior work from @butanium.bsky.social and @wendlerc.bsky.social)
Token induction heads are still important, though. When we ablate them over long sequences, models start to paraphrase instead of copying. We take this to mean that token induction heads are responsible for *exact* copying (which concept induction heads apparently can't do).

April 7, 2025 at 1:54 PM
Token induction heads are still important, though. When we ablate them over long sequences, models start to paraphrase instead of copying. We take this to mean that token induction heads are responsible for *exact* copying (which concept induction heads apparently can't do).
But how do we know these heads copy semantics? When we ablate concept induction heads, performance drops drastically for translation, synonyms, and antonyms: all tasks that require copying *meaning*, not just literal tokens.

April 7, 2025 at 1:54 PM
But how do we know these heads copy semantics? When we ablate concept induction heads, performance drops drastically for translation, synonyms, and antonyms: all tasks that require copying *meaning*, not just literal tokens.
Previous work showed that token induction heads attend to the next token to be copied (*window*pane). Analogously, we find that concept induction heads attend to the end of the next multi-token word to be copied (windowp*ane*).

April 7, 2025 at 1:54 PM
Previous work showed that token induction heads attend to the next token to be copied (*window*pane). Analogously, we find that concept induction heads attend to the end of the next multi-token word to be copied (windowp*ane*).
--using causal interventions. Essentially, we pick out all of the attention heads that are responsible for promoting future entity tokens (e.g. "ax" in "waxwing"). We hypothesize that heads carrying an entire entity actually represent the *meaning* of that chunk of tokens.

April 7, 2025 at 1:54 PM
--using causal interventions. Essentially, we pick out all of the attention heads that are responsible for promoting future entity tokens (e.g. "ax" in "waxwing"). We hypothesize that heads carrying an entire entity actually represent the *meaning* of that chunk of tokens.
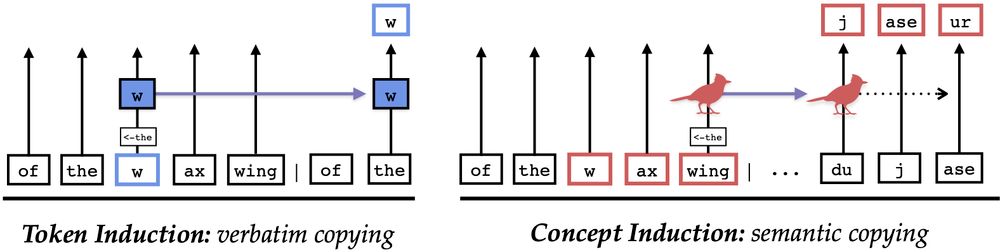
There are multiple ways to copy text! Copying a wifi password like hxioW2qN52 is different than copying a meaningful one like OwlDoorGlass. Nonsense copying requires each char to be transferred one-by-one, but meaningful words can be copied all at once. Turns out, LLMs do both.

April 7, 2025 at 1:54 PM
There are multiple ways to copy text! Copying a wifi password like hxioW2qN52 is different than copying a meaningful one like OwlDoorGlass. Nonsense copying requires each char to be transferred one-by-one, but meaningful words can be copied all at once. Turns out, LLMs do both.
[📄] Are LLMs mindless token-shifters, or do they build meaningful representations of language? We study how LLMs copy text in-context, and physically separate out two types of induction heads: token heads, which copy literal tokens, and concept heads, which copy word meanings.
April 7, 2025 at 1:54 PM
[📄] Are LLMs mindless token-shifters, or do they build meaningful representations of language? We study how LLMs copy text in-context, and physically separate out two types of induction heads: token heads, which copy literal tokens, and concept heads, which copy word meanings.
Japonaise Bakery in Brookline :) 🥐

November 24, 2024 at 8:57 PM
Japonaise Bakery in Brookline :) 🥐