




Sebastian Raschka (rasbt)
@sebastianraschka.com
ML/AI researcher & former stats professor turned LLM research engineer. Author of "Build a Large Language Model From Scratch" (https://amzn.to/4fqvn0D) & reasoning (https://mng.bz/Nwr7).
Also blogging about AI research at magazine.sebastianraschka.com.
Also blogging about AI research at magazine.sebastianraschka.com.
I just saw the Kimi K2 Thinking release!
Kimi K2 is based on the DeepSeek V3/R1 architecture, and here's a side-by-side comparison.
In short, Kimi K2 is a slightly scaled DeepSeek V3/R1. And the gains are in the data and training recipes. Hopefully, we will see some details on those soon, too.
Kimi K2 is based on the DeepSeek V3/R1 architecture, and here's a side-by-side comparison.
In short, Kimi K2 is a slightly scaled DeepSeek V3/R1. And the gains are in the data and training recipes. Hopefully, we will see some details on those soon, too.

November 6, 2025 at 7:35 PM
I just saw the Kimi K2 Thinking release!
Kimi K2 is based on the DeepSeek V3/R1 architecture, and here's a side-by-side comparison.
In short, Kimi K2 is a slightly scaled DeepSeek V3/R1. And the gains are in the data and training recipes. Hopefully, we will see some details on those soon, too.
Kimi K2 is based on the DeepSeek V3/R1 architecture, and here's a side-by-side comparison.
In short, Kimi K2 is a slightly scaled DeepSeek V3/R1. And the gains are in the data and training recipes. Hopefully, we will see some details on those soon, too.
My new field guide to alternatives to standard LLMs:
Gated DeltaNet hybrids (Qwen3-Next, Kimi Linear), text diffusion, code world models, and small reasoning transformers.
🔗 magazine.sebastianraschka.com/p/beyond-sta...
Gated DeltaNet hybrids (Qwen3-Next, Kimi Linear), text diffusion, code world models, and small reasoning transformers.
🔗 magazine.sebastianraschka.com/p/beyond-sta...

November 4, 2025 at 2:49 PM
My new field guide to alternatives to standard LLMs:
Gated DeltaNet hybrids (Qwen3-Next, Kimi Linear), text diffusion, code world models, and small reasoning transformers.
🔗 magazine.sebastianraschka.com/p/beyond-sta...
Gated DeltaNet hybrids (Qwen3-Next, Kimi Linear), text diffusion, code world models, and small reasoning transformers.
🔗 magazine.sebastianraschka.com/p/beyond-sta...
Just saw the benchmarks of the new open-weight MiniMax-M2 LLM, and the performance is too good to ignore :). So, I just amended my "The Big LLM Architecture Comparison" with entry number 13!
Link to the full article: magazine.sebastianraschka.com/p/the-big-ll...
Link to the full article: magazine.sebastianraschka.com/p/the-big-ll...

October 28, 2025 at 4:48 PM
Just saw the benchmarks of the new open-weight MiniMax-M2 LLM, and the performance is too good to ignore :). So, I just amended my "The Big LLM Architecture Comparison" with entry number 13!
Link to the full article: magazine.sebastianraschka.com/p/the-big-ll...
Link to the full article: magazine.sebastianraschka.com/p/the-big-ll...
ha, very timely! Just got back from the conference and haven't had a chance to read the M2 report. But based on the Model Hub, it seems that SWA is not the default (similar to the recent Mistral Models) 🤔
(Source: huggingface.co/MiniMaxAI/Mi...)
(Source: huggingface.co/MiniMaxAI/Mi...)

October 27, 2025 at 6:11 PM
ha, very timely! Just got back from the conference and haven't had a chance to read the M2 report. But based on the Model Hub, it seems that SWA is not the default (similar to the recent Mistral Models) 🤔
(Source: huggingface.co/MiniMaxAI/Mi...)
(Source: huggingface.co/MiniMaxAI/Mi...)
A short talk on the main architecture components of LLMs this year + a look beyond the transformer architecture: www.youtube.com/watch?v=lONy...

October 27, 2025 at 3:45 PM
A short talk on the main architecture components of LLMs this year + a look beyond the transformer architecture: www.youtube.com/watch?v=lONy...
🔗 Mixture of Experts (MoE): github.com/rasbt/LLMs-f...

October 20, 2025 at 1:48 PM
🔗 Mixture of Experts (MoE): github.com/rasbt/LLMs-f...
Chapter 3, and with it the first 176 pages, is now live! (mng.bz/lZ5B)

October 16, 2025 at 1:35 PM
Chapter 3, and with it the first 176 pages, is now live! (mng.bz/lZ5B)
Sliding Window Attention
🔗 github.com/rasbt/LLMs-f...
🔗 github.com/rasbt/LLMs-f...

October 13, 2025 at 1:51 PM
Sliding Window Attention
🔗 github.com/rasbt/LLMs-f...
🔗 github.com/rasbt/LLMs-f...
Multi-Head Latent Attention
🔗 github.com/rasbt/LLMs-f...
🔗 github.com/rasbt/LLMs-f...

October 12, 2025 at 1:57 PM
Multi-Head Latent Attention
🔗 github.com/rasbt/LLMs-f...
🔗 github.com/rasbt/LLMs-f...
Just a bit of weekend coding fun: A memory estimator to calculate the savings when using grouped-query attention vs multi-head attention (+ code implementations of course).
🔗 github.com/rasbt/LLMs-f...
Will add this for multi-head latent, sliding, and sparse attention as well.
🔗 github.com/rasbt/LLMs-f...
Will add this for multi-head latent, sliding, and sparse attention as well.

October 11, 2025 at 1:46 PM
Just a bit of weekend coding fun: A memory estimator to calculate the savings when using grouped-query attention vs multi-head attention (+ code implementations of course).
🔗 github.com/rasbt/LLMs-f...
Will add this for multi-head latent, sliding, and sparse attention as well.
🔗 github.com/rasbt/LLMs-f...
Will add this for multi-head latent, sliding, and sparse attention as well.
From the Hierarchical Reasoning Model (HRM) to a new Tiny Recursive Model (TRM).
A few months ago, the HRM made big waves in the AI research community as it showed really good performance on the ARC challenge despite its small 27M size. (That's about 22x smaller than the smallest Qwen3 0.6B model.)
A few months ago, the HRM made big waves in the AI research community as it showed really good performance on the ARC challenge despite its small 27M size. (That's about 22x smaller than the smallest Qwen3 0.6B model.)

October 9, 2025 at 4:23 PM
From the Hierarchical Reasoning Model (HRM) to a new Tiny Recursive Model (TRM).
A few months ago, the HRM made big waves in the AI research community as it showed really good performance on the ARC challenge despite its small 27M size. (That's about 22x smaller than the smallest Qwen3 0.6B model.)
A few months ago, the HRM made big waves in the AI research community as it showed really good performance on the ARC challenge despite its small 27M size. (That's about 22x smaller than the smallest Qwen3 0.6B model.)
It only took 13 years, but dark mode is finally here
sebastianraschka.com/blog/2021/dl...
sebastianraschka.com/blog/2021/dl...

October 8, 2025 at 1:50 AM
It only took 13 years, but dark mode is finally here
sebastianraschka.com/blog/2021/dl...
sebastianraschka.com/blog/2021/dl...
Just shared a new article on "The State of Reinforcement Learning for LLM Reasoning"!
If you are new to reinforcement learning, this article has a generous intro section (PPO, GRPO, etc)
Also, I cover 15 recent articles focused on RL & Reasoning.
🔗 magazine.sebastianraschka.com/p/the-state-...
If you are new to reinforcement learning, this article has a generous intro section (PPO, GRPO, etc)
Also, I cover 15 recent articles focused on RL & Reasoning.
🔗 magazine.sebastianraschka.com/p/the-state-...

April 19, 2025 at 1:48 PM
Just shared a new article on "The State of Reinforcement Learning for LLM Reasoning"!
If you are new to reinforcement learning, this article has a generous intro section (PPO, GRPO, etc)
Also, I cover 15 recent articles focused on RL & Reasoning.
🔗 magazine.sebastianraschka.com/p/the-state-...
If you are new to reinforcement learning, this article has a generous intro section (PPO, GRPO, etc)
Also, I cover 15 recent articles focused on RL & Reasoning.
🔗 magazine.sebastianraschka.com/p/the-state-...
Coded Llama 3.2 model from scratch and shared it on the HF Hub.
Why? Because I think 1B & 3B models are great for experimentation, and I wanted to share a clean, readable implementation for learning and research: huggingface.co/rasbt/llama-...
Why? Because I think 1B & 3B models are great for experimentation, and I wanted to share a clean, readable implementation for learning and research: huggingface.co/rasbt/llama-...

March 31, 2025 at 5:13 PM
Coded Llama 3.2 model from scratch and shared it on the HF Hub.
Why? Because I think 1B & 3B models are great for experimentation, and I wanted to share a clean, readable implementation for learning and research: huggingface.co/rasbt/llama-...
Why? Because I think 1B & 3B models are great for experimentation, and I wanted to share a clean, readable implementation for learning and research: huggingface.co/rasbt/llama-...
My next tutorial on pretraining an LLM from scratch is now out. It starts with a step-by-step walkthrough of understanding, calculating, and optimizing the loss. After training, we update the text generation function with temperature scaling and top-k sampling: www.youtube.com/watch?v=Zar2...

March 23, 2025 at 1:38 PM
My next tutorial on pretraining an LLM from scratch is now out. It starts with a step-by-step walkthrough of understanding, calculating, and optimizing the loss. After training, we update the text generation function with temperature scaling and top-k sampling: www.youtube.com/watch?v=Zar2...
Yup, you can find it here: github.com/rasbt/LLMs-f...

March 17, 2025 at 6:25 PM
Yup, you can find it here: github.com/rasbt/LLMs-f...
Yesterday, Google released Gemma 3, their latest open-weight LLM. Finally, a new addition to the "Big 5" of open-weight models (Gemma, Llama, DeepSeek, Qwen, and Mistral). I just went through the Gemma 3 report and experimented a bit with the models, and there are plenty of interesting tidbits:

March 13, 2025 at 4:03 PM
Yesterday, Google released Gemma 3, their latest open-weight LLM. Finally, a new addition to the "Big 5" of open-weight models (Gemma, Llama, DeepSeek, Qwen, and Mistral). I just went through the Gemma 3 report and experimented a bit with the models, and there are plenty of interesting tidbits:
I honestly don't know. I remember that the publisher put together a complimentary free "Test yourself" ebook for people who already purchased the book (www.manning.com/books/test-y...), maybe someone uploaded it / is selling it on Amazon. Let me ask the publisher to ask what's up with that.

March 6, 2025 at 3:40 PM
I honestly don't know. I remember that the publisher put together a complimentary free "Test yourself" ebook for people who already purchased the book (www.manning.com/books/test-y...), maybe someone uploaded it / is selling it on Amazon. Let me ask the publisher to ask what's up with that.
Takeaways from the latest State of ML Competitions report mlcontests.com/state-of-mac...:
- Python & PyTorch still dominate
- 80%+ use NVIDIA GPUs, but no multi-node setups 🤔
- LoRA still popular for training efficiency, but full finetuning gains traction.
Surprisingly, CNNs still lead in CV comps
- Python & PyTorch still dominate
- 80%+ use NVIDIA GPUs, but no multi-node setups 🤔
- LoRA still popular for training efficiency, but full finetuning gains traction.
Surprisingly, CNNs still lead in CV comps

March 5, 2025 at 4:24 PM
Takeaways from the latest State of ML Competitions report mlcontests.com/state-of-mac...:
- Python & PyTorch still dominate
- 80%+ use NVIDIA GPUs, but no multi-node setups 🤔
- LoRA still popular for training efficiency, but full finetuning gains traction.
Surprisingly, CNNs still lead in CV comps
- Python & PyTorch still dominate
- 80%+ use NVIDIA GPUs, but no multi-node setups 🤔
- LoRA still popular for training efficiency, but full finetuning gains traction.
Surprisingly, CNNs still lead in CV comps
Here’s the 2025 LLM roadmap 😊
1. Code and train your own LLM to really understand the fundamentals
2. Train models more conveniently using production-ready libraries
3. Learn about the big-picture considerations for real-world LLM/AI apps
1. Code and train your own LLM to really understand the fundamentals
2. Train models more conveniently using production-ready libraries
3. Learn about the big-picture considerations for real-world LLM/AI apps
February 23, 2025 at 7:41 PM
Here’s the 2025 LLM roadmap 😊
1. Code and train your own LLM to really understand the fundamentals
2. Train models more conveniently using production-ready libraries
3. Learn about the big-picture considerations for real-world LLM/AI apps
1. Code and train your own LLM to really understand the fundamentals
2. Train models more conveniently using production-ready libraries
3. Learn about the big-picture considerations for real-world LLM/AI apps
Thanks! And yes, I added a "more native" uv guide to explain this.

February 16, 2025 at 2:37 PM
Thanks! And yes, I added a "more native" uv guide to explain this.
Yes, if you install uv then you can use uv to install python. I added a second doc describing that more native uv workflow: github.com/rasbt/LLMs-f...
February 16, 2025 at 2:36 PM
Yes, if you install uv then you can use uv to install python. I added a second doc describing that more native uv workflow: github.com/rasbt/LLMs-f...
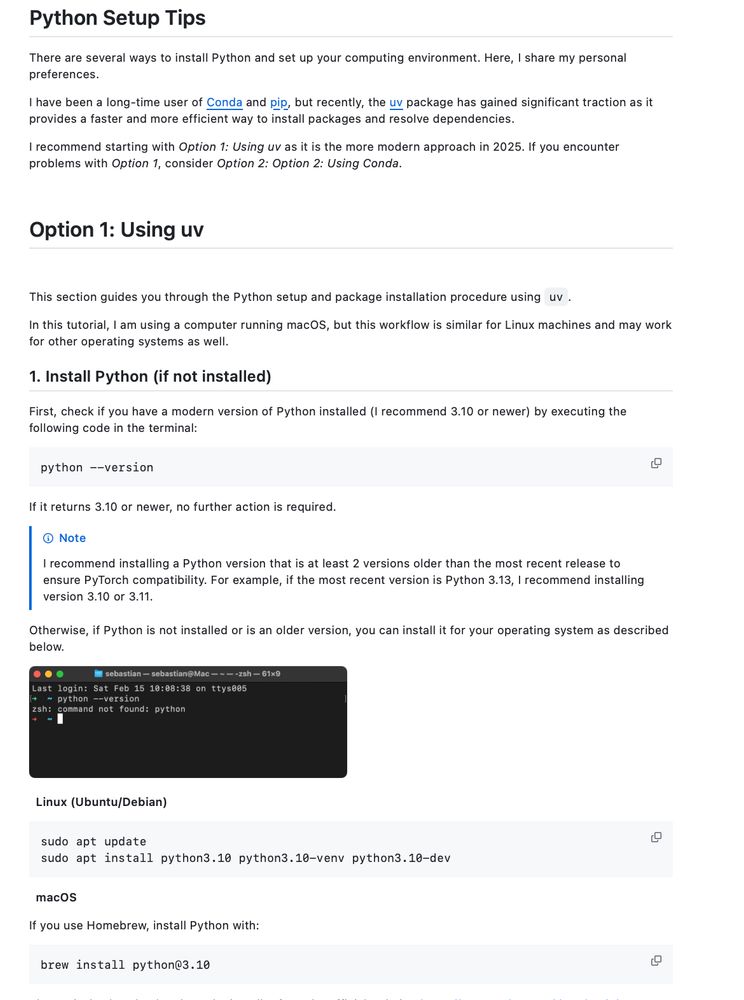
In any case, I added a doc for native `uv add`: github.com/rasbt/LLMs-f...
February 16, 2025 at 3:06 AM
In any case, I added a doc for native `uv add`: github.com/rasbt/LLMs-f...
It's 2025, and I’ve finally updated my Python setup guide to use uv + venv instead of conda + pip!
Here's my go-to recommendation for uv + venv in Python projects for faster installs, better dependency management: github.com/rasbt/LLMs-f...
(Any additional suggestions?)
Here's my go-to recommendation for uv + venv in Python projects for faster installs, better dependency management: github.com/rasbt/LLMs-f...
(Any additional suggestions?)
February 15, 2025 at 7:14 PM
It's 2025, and I’ve finally updated my Python setup guide to use uv + venv instead of conda + pip!
Here's my go-to recommendation for uv + venv in Python projects for faster installs, better dependency management: github.com/rasbt/LLMs-f...
(Any additional suggestions?)
Here's my go-to recommendation for uv + venv in Python projects for faster installs, better dependency management: github.com/rasbt/LLMs-f...
(Any additional suggestions?)
Can we merge the query and key weight matrices in an LLM into a single covariance matrix and still train effectively? Here are some promising early results from a reader: github.com/rasbt/LLMs-f...
Anyone else familiar with projects that tried this?
Anyone else familiar with projects that tried this?

February 14, 2025 at 2:13 PM
Can we merge the query and key weight matrices in an LLM into a single covariance matrix and still train effectively? Here are some promising early results from a reader: github.com/rasbt/LLMs-f...
Anyone else familiar with projects that tried this?
Anyone else familiar with projects that tried this?