



Sebastian Joseph
@sebajoe.bsky.social
CS Ph.D. Student at UT Austin
Even the best LLMs struggle to execute scientific workflows.
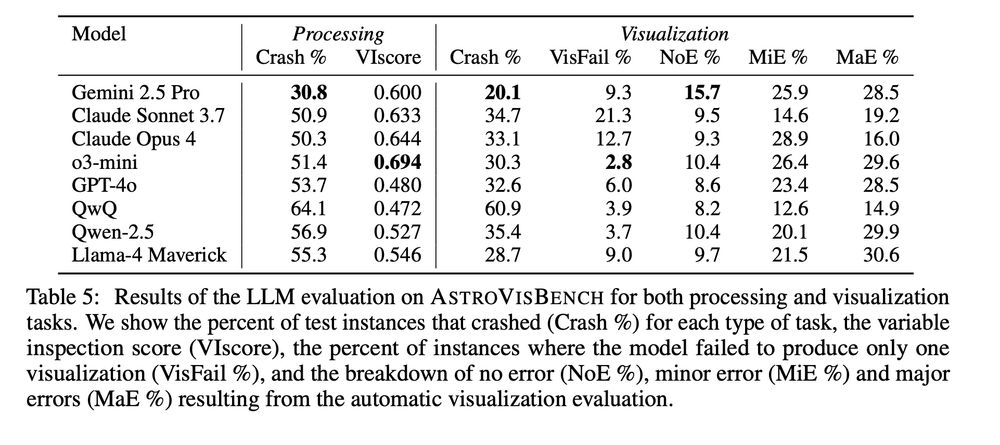
SOTA models including Gemini 2.5 Pro, Claude Opus 4, o3-mini and QwQ crash 30-60% of the time and only produce visualizations without error in less than 16% of the cases.
SOTA models including Gemini 2.5 Pro, Claude Opus 4, o3-mini and QwQ crash 30-60% of the time and only produce visualizations without error in less than 16% of the cases.
June 2, 2025 at 3:42 PM
Even the best LLMs struggle to execute scientific workflows.
SOTA models including Gemini 2.5 Pro, Claude Opus 4, o3-mini and QwQ crash 30-60% of the time and only produce visualizations without error in less than 16% of the cases.
SOTA models including Gemini 2.5 Pro, Claude Opus 4, o3-mini and QwQ crash 30-60% of the time and only produce visualizations without error in less than 16% of the cases.
We generate code from a model, run it, and evaluate the following:
Processing tasks: we compare key variable values.
Visualizations: we use a VLM judge (well correlated w/ pro astronomers) that compares a visualization’s scientific utility to that of the ground truth.
Processing tasks: we compare key variable values.
Visualizations: we use a VLM judge (well correlated w/ pro astronomers) that compares a visualization’s scientific utility to that of the ground truth.

June 2, 2025 at 3:42 PM
We generate code from a model, run it, and evaluate the following:
Processing tasks: we compare key variable values.
Visualizations: we use a VLM judge (well correlated w/ pro astronomers) that compares a visualization’s scientific utility to that of the ground truth.
Processing tasks: we compare key variable values.
Visualizations: we use a VLM judge (well correlated w/ pro astronomers) that compares a visualization’s scientific utility to that of the ground truth.
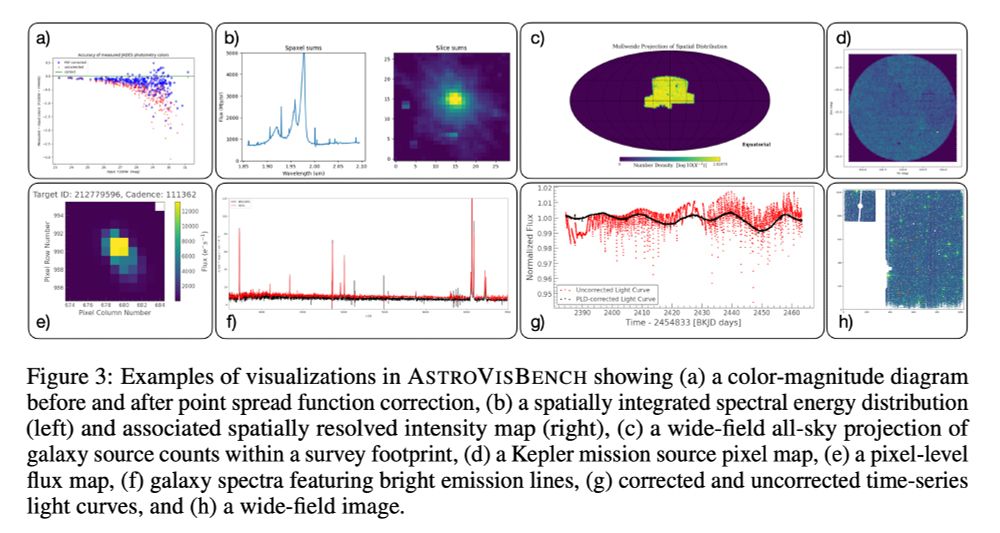
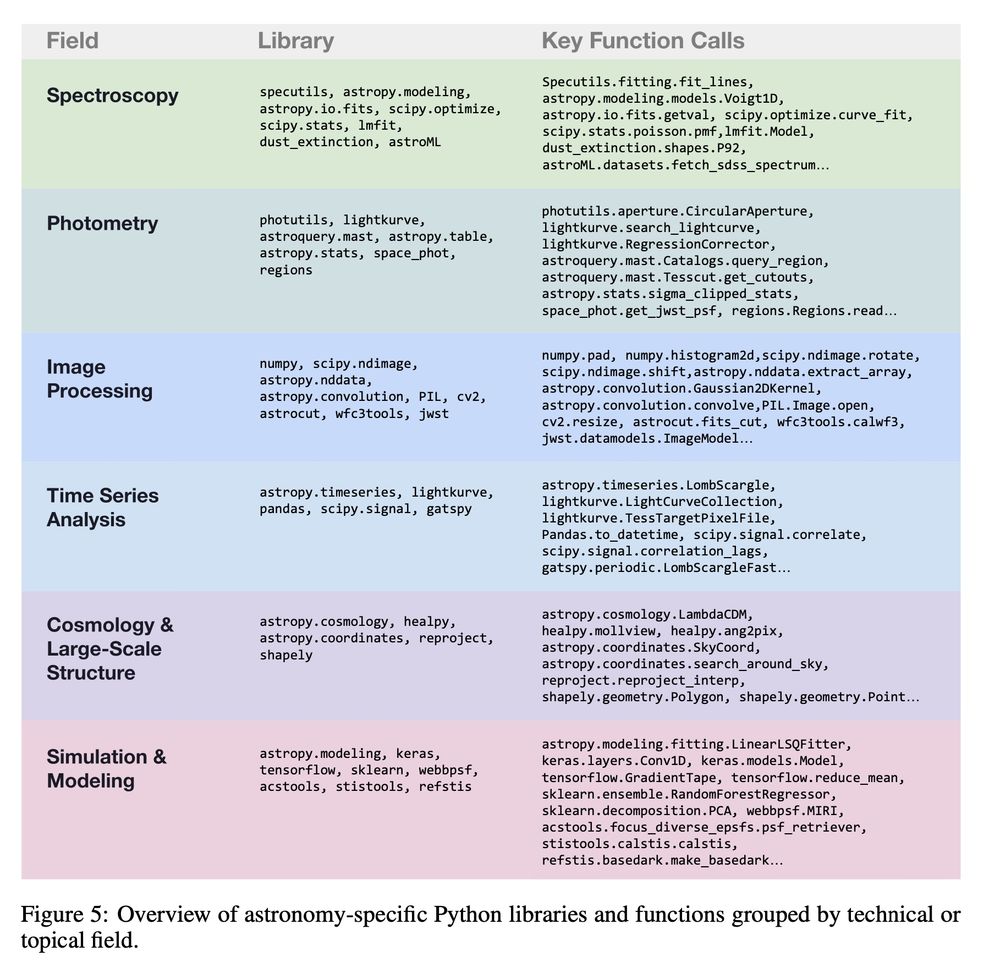
We created AstroVisBench from expert-curated jupyter notebooks for astronomy tasks, from which we constructed 432 sets of processing and plotting tasks. It tests a diverse set of visualizations and long-tail API use.
June 2, 2025 at 3:42 PM
We created AstroVisBench from expert-curated jupyter notebooks for astronomy tasks, from which we constructed 432 sets of processing and plotting tasks. It tests a diverse set of visualizations and long-tail API use.
How good are LLMs at 🔭 scientific computing and visualization 🔭?
AstroVisBench tests how well LLMs implement scientific workflows in astronomy and visualize results.
SOTA models like Gemini 2.5 Pro & Claude 4 Opus only match ground truth scientific utility 16% of the time. 🧵
AstroVisBench tests how well LLMs implement scientific workflows in astronomy and visualize results.
SOTA models like Gemini 2.5 Pro & Claude 4 Opus only match ground truth scientific utility 16% of the time. 🧵


June 2, 2025 at 3:42 PM
How good are LLMs at 🔭 scientific computing and visualization 🔭?
AstroVisBench tests how well LLMs implement scientific workflows in astronomy and visualize results.
SOTA models like Gemini 2.5 Pro & Claude 4 Opus only match ground truth scientific utility 16% of the time. 🧵
AstroVisBench tests how well LLMs implement scientific workflows in astronomy and visualize results.
SOTA models like Gemini 2.5 Pro & Claude 4 Opus only match ground truth scientific utility 16% of the time. 🧵