




Charlie Snell
@seasnell.bsky.social
PhD @berkeley_ai; prev SR @GoogleDeepMind. I stare at my computer a lot and make things
Finally, we present a case study of two real world uses for emergence prediction:
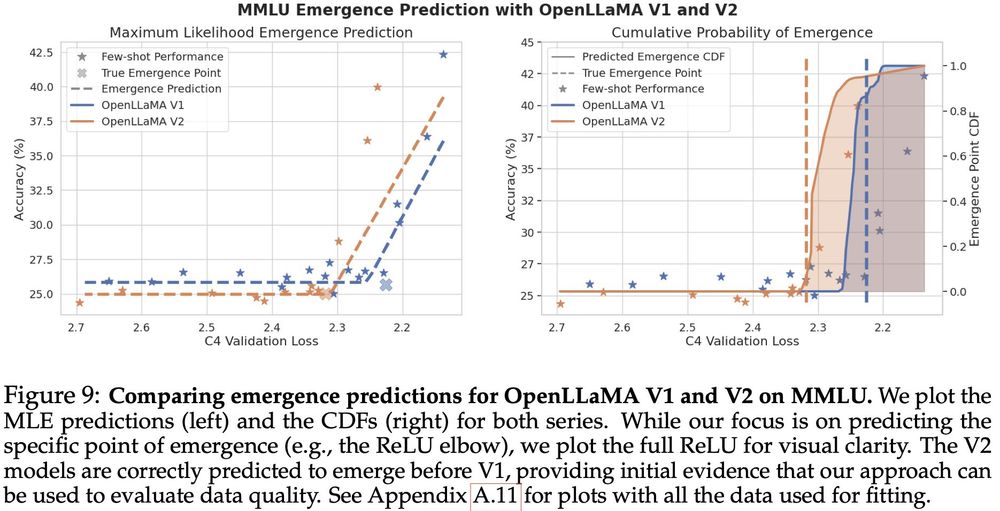
1) cheaply assessing pretraining data quality (left).
2) predicting more complex capabilities, closer to those of future frontier models, using the difficult APPS coding benchmark (right).
1) cheaply assessing pretraining data quality (left).
2) predicting more complex capabilities, closer to those of future frontier models, using the difficult APPS coding benchmark (right).

November 26, 2024 at 10:37 PM
Finally, we present a case study of two real world uses for emergence prediction:
1) cheaply assessing pretraining data quality (left).
2) predicting more complex capabilities, closer to those of future frontier models, using the difficult APPS coding benchmark (right).
1) cheaply assessing pretraining data quality (left).
2) predicting more complex capabilities, closer to those of future frontier models, using the difficult APPS coding benchmark (right).
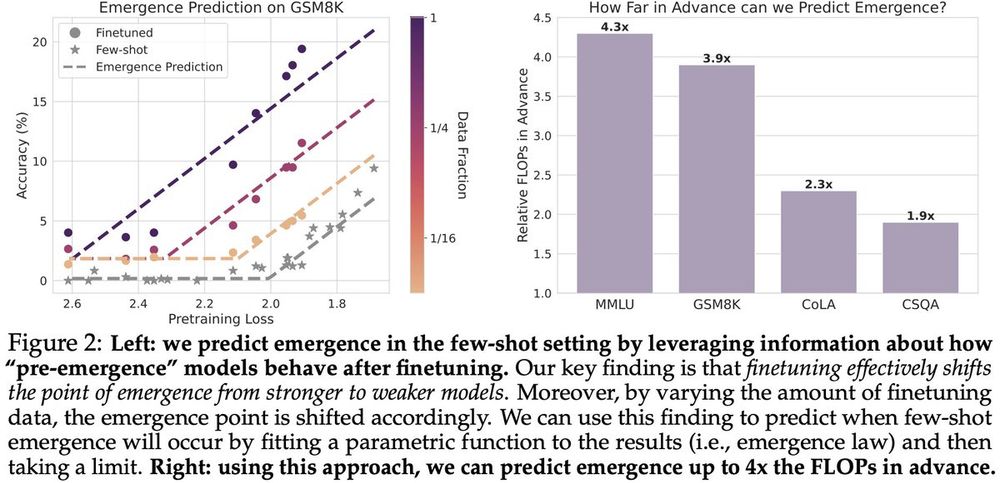
We validate our emergence law using four standard NLP benchmarks where large-scale open-source LLMs already demonstrate emergence, so we can easily check our predictions.
We find that our emergence law can accurately predict the point of emergence up to 4x the FLOPs in advance.
We find that our emergence law can accurately predict the point of emergence up to 4x the FLOPs in advance.
November 26, 2024 at 10:37 PM
We validate our emergence law using four standard NLP benchmarks where large-scale open-source LLMs already demonstrate emergence, so we can easily check our predictions.
We find that our emergence law can accurately predict the point of emergence up to 4x the FLOPs in advance.
We find that our emergence law can accurately predict the point of emergence up to 4x the FLOPs in advance.
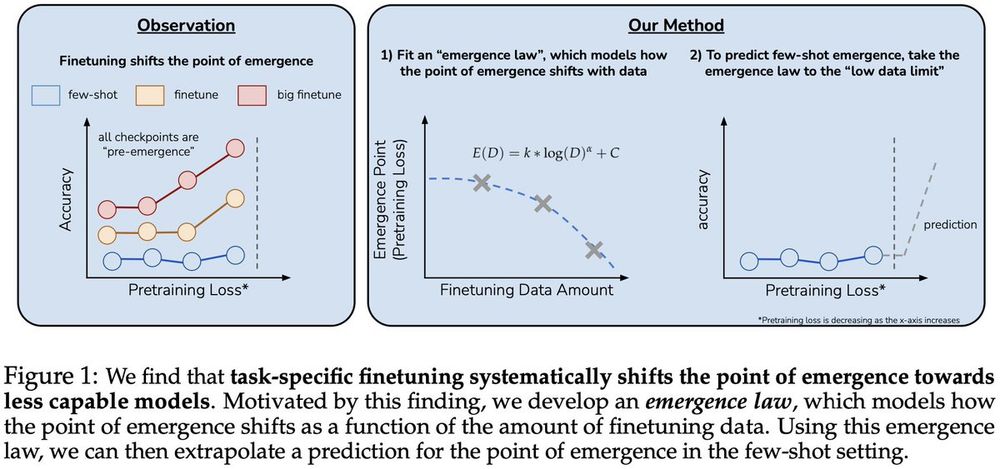
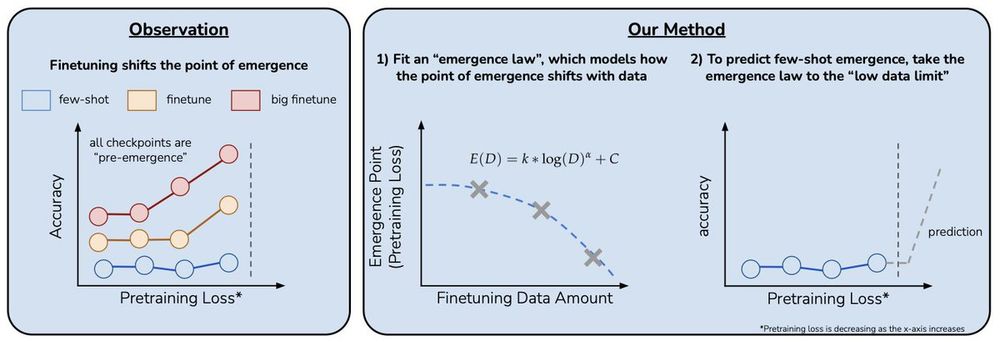
To operationalize this insight, we finetune LLMs on varying amounts of data and fit a parametric function (i.e., “emergence law”) which models how the point of emergence shifts with the amount of data. We can then extrapolate a prediction for emergence in the few-shot setting.
November 26, 2024 at 10:37 PM
To operationalize this insight, we finetune LLMs on varying amounts of data and fit a parametric function (i.e., “emergence law”) which models how the point of emergence shifts with the amount of data. We can then extrapolate a prediction for emergence in the few-shot setting.
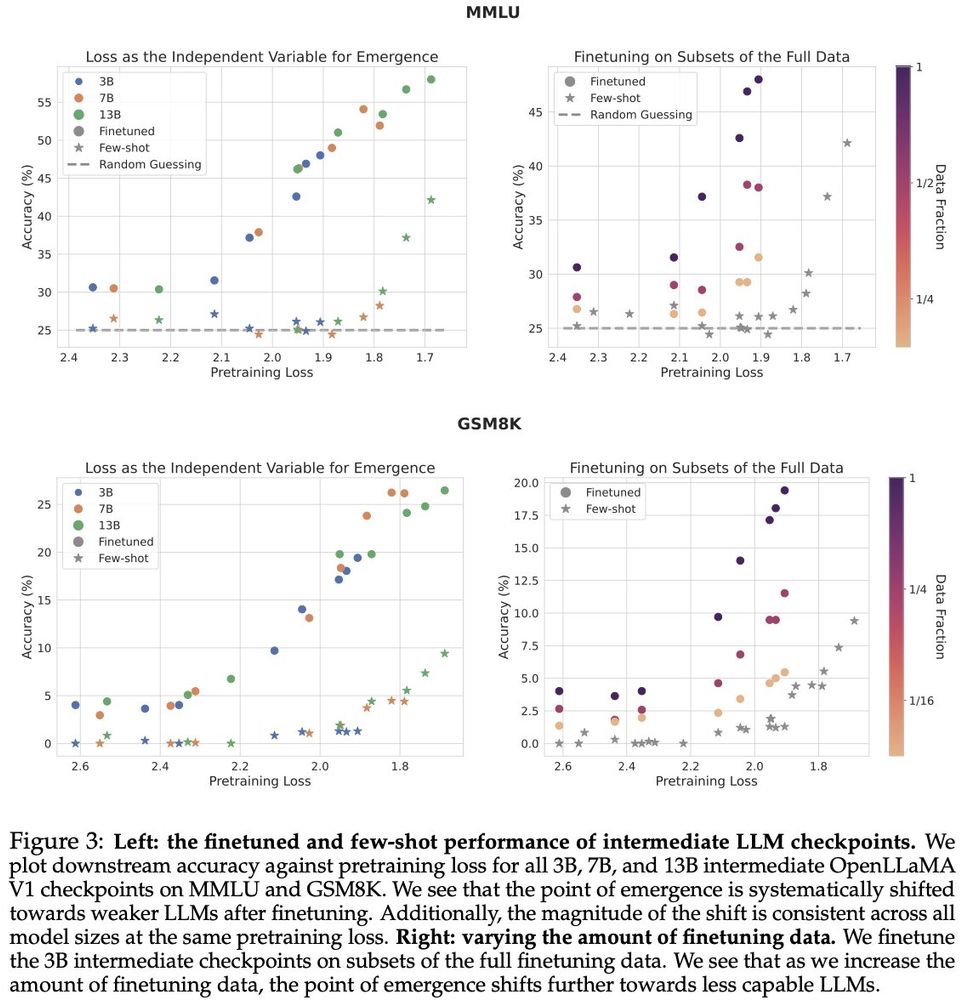
We then discover a simple insight for this problem:
finetuning LLMs on a given task can shift the point in scaling at which emergence occurs towards less capable LLMs, and the magnitude of this shift is modulated by the amount of finetuning data.
finetuning LLMs on a given task can shift the point in scaling at which emergence occurs towards less capable LLMs, and the magnitude of this shift is modulated by the amount of finetuning data.
November 26, 2024 at 10:37 PM
We then discover a simple insight for this problem:
finetuning LLMs on a given task can shift the point in scaling at which emergence occurs towards less capable LLMs, and the magnitude of this shift is modulated by the amount of finetuning data.
finetuning LLMs on a given task can shift the point in scaling at which emergence occurs towards less capable LLMs, and the magnitude of this shift is modulated by the amount of finetuning data.
Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task?
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
November 26, 2024 at 10:37 PM
Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task?
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵