



Christina Sartzetaki
@sargechris.bsky.social
PhD candidate @ UvA 🇳🇱, ELLIS 🇪🇺 | {video, neuro, cognitive}-AI
Neural networks 🤖 and brains 🧠 watching videos
🔗 https://sites.google.com/view/csartzetaki/
Neural networks 🤖 and brains 🧠 watching videos
🔗 https://sites.google.com/view/csartzetaki/
9/ This is our first research output in this interesting new direction and I’m actively working on this - so stay tuned for updates and follow-up works!
Feel free to discuss your ideas and opinions with me ⬇️
December 11, 2024 at 4:13 PM
9/ This is our first research output in this interesting new direction and I’m actively working on this - so stay tuned for updates and follow-up works!
Feel free to discuss your ideas and opinions with me ⬇️
8/ 🎯 With this work we aim to forge a path that widens our understanding of temporal and semantic video representations in brains and machines, ideally leading towards more efficient video models and more mechanistic explanations of processing in the human brain.
December 11, 2024 at 4:13 PM
8/ 🎯 With this work we aim to forge a path that widens our understanding of temporal and semantic video representations in brains and machines, ideally leading towards more efficient video models and more mechanistic explanations of processing in the human brain.
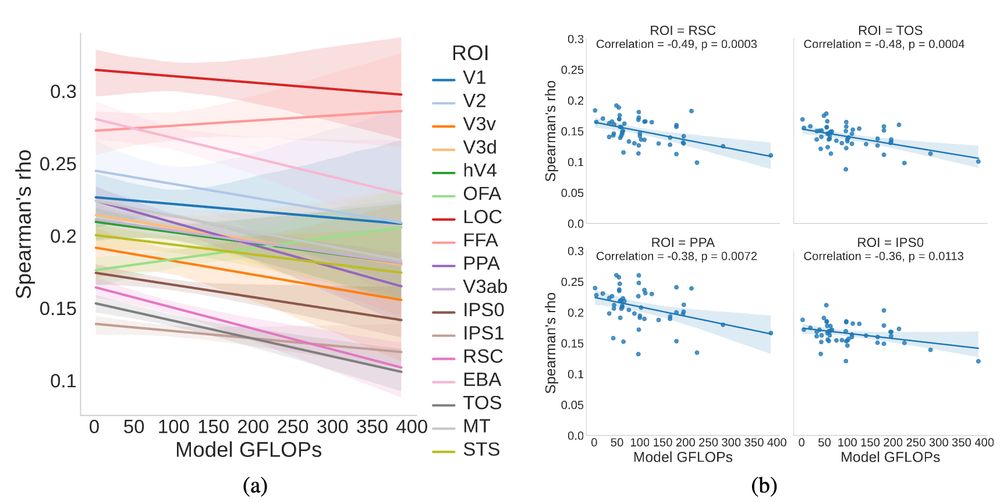
7/ We report a significant negative correlation of model FLOPs to alignment in several high-level brain areas, indicating that computationally efficient neural networks can potentially produce more human-like semantic representations.
December 11, 2024 at 4:13 PM
7/ We report a significant negative correlation of model FLOPs to alignment in several high-level brain areas, indicating that computationally efficient neural networks can potentially produce more human-like semantic representations.
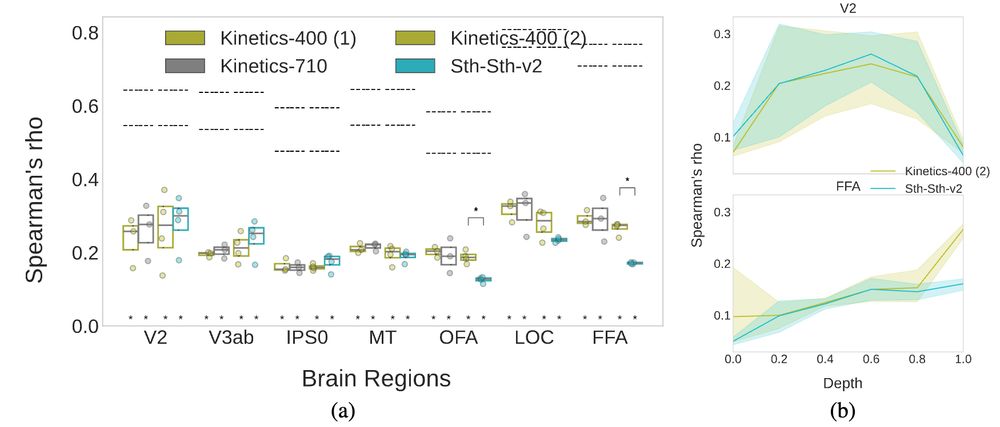
6/ Training dataset biases related to a certain functional selectivity (e.g. face features) can be transferred in brain alignment with the respective functionally selective brain area (e.g. face region FFA).
December 11, 2024 at 4:13 PM
6/ Training dataset biases related to a certain functional selectivity (e.g. face features) can be transferred in brain alignment with the respective functionally selective brain area (e.g. face region FFA).
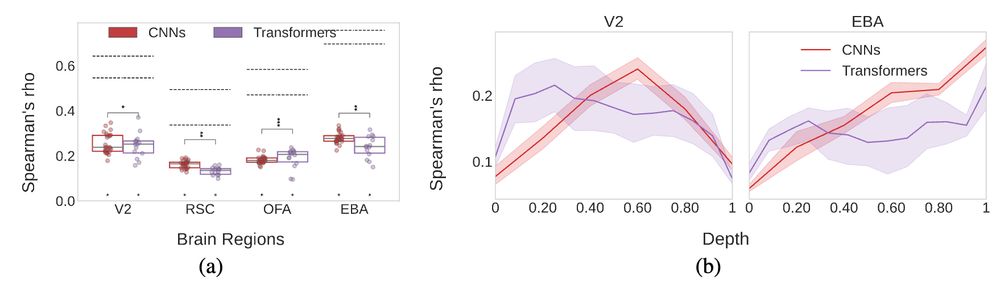
5/ Comparing model architectures, CNNs exhibit a better hierarchy overall (with a clear mid-depth peak for early regions and gradual improvement as depth increases for late regions). Transformers however, achieve an impressive correlation to early regions even from one tenth of layer depth.
December 11, 2024 at 4:13 PM
5/ Comparing model architectures, CNNs exhibit a better hierarchy overall (with a clear mid-depth peak for early regions and gradual improvement as depth increases for late regions). Transformers however, achieve an impressive correlation to early regions even from one tenth of layer depth.
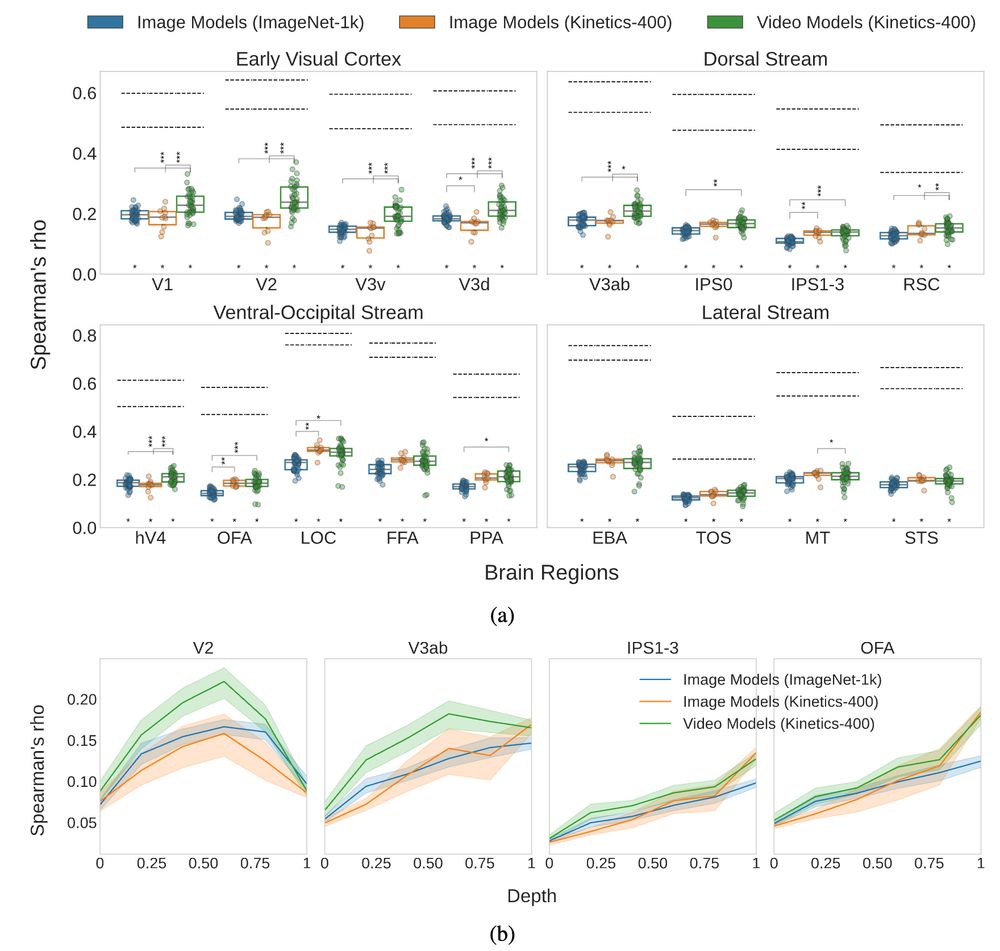
4/ We decouple temporal modeling from action space optimization by adding image action recognition models as control. Our results show that temporal modeling is key for alignment to early visual brain regions, while a relevant classification task is key for alignment to higher-level regions.
December 11, 2024 at 4:13 PM
4/ We decouple temporal modeling from action space optimization by adding image action recognition models as control. Our results show that temporal modeling is key for alignment to early visual brain regions, while a relevant classification task is key for alignment to higher-level regions.
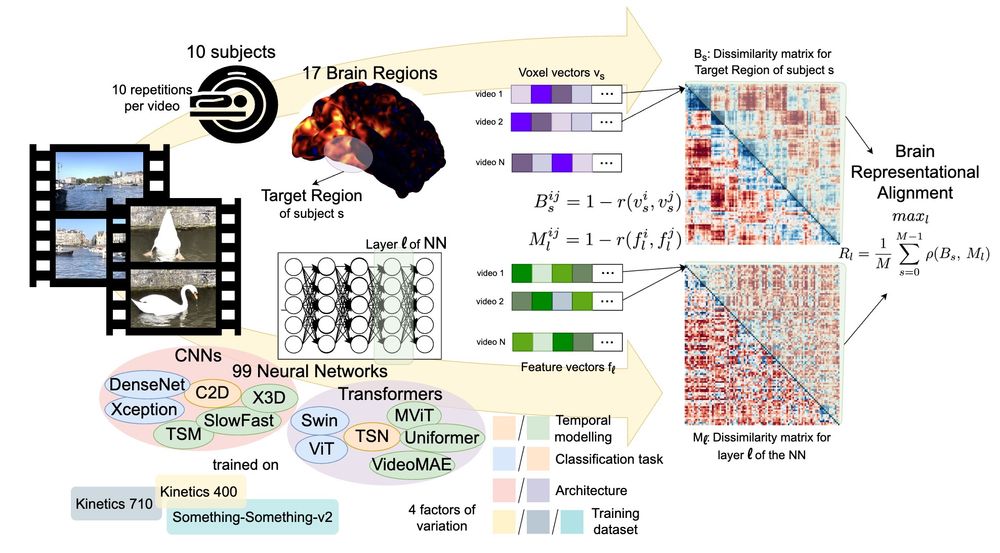
3/ We disentangle 4 factors of variation (temporal modeling, classification task, architecture, and training dataset) that affect model-brain alignment, which we measure by conducting Representational Similarity Analysis (RSA) across multiple brain regions and model layers.
December 11, 2024 at 4:13 PM
3/ We disentangle 4 factors of variation (temporal modeling, classification task, architecture, and training dataset) that affect model-brain alignment, which we measure by conducting Representational Similarity Analysis (RSA) across multiple brain regions and model layers.
2/ We take a step in this direction by performing a large-scale benchmarking of models on their representational alignment to the recently released Bold Moments Dataset of fMRI recordings from humans watching videos.
December 11, 2024 at 4:13 PM
2/ We take a step in this direction by performing a large-scale benchmarking of models on their representational alignment to the recently released Bold Moments Dataset of fMRI recordings from humans watching videos.
1/ Humans are very efficient in processing continuous visual input, neural networks trained to process videos are still not up to that standard.
What can we learn from comparing the internal representations of the two systems (biological and artificial)?
December 11, 2024 at 4:13 PM
1/ Humans are very efficient in processing continuous visual input, neural networks trained to process videos are still not up to that standard.
What can we learn from comparing the internal representations of the two systems (biological and artificial)?