




Santiago Viquez
@santiviquez.com
ML @ NannyML. Writing “The Little Book of ML Metrics” https://www.nannyml.com/metrics?via=santiago
Personal website: https://www.santiviquez.com
Personal website: https://www.santiviquez.com
It's happening!
Join us next week to ask Sebastian Raschka anything!
📅 Date: February 11th
⏰ Time: 10:00 AM – 11:00 AM EST
📍 Register: lu.ma/evqa4rct
Join us next week to ask Sebastian Raschka anything!
📅 Date: February 11th
⏰ Time: 10:00 AM – 11:00 AM EST
📍 Register: lu.ma/evqa4rct

February 9, 2025 at 8:45 PM
It's happening!
Join us next week to ask Sebastian Raschka anything!
📅 Date: February 11th
⏰ Time: 10:00 AM – 11:00 AM EST
📍 Register: lu.ma/evqa4rct
Join us next week to ask Sebastian Raschka anything!
📅 Date: February 11th
⏰ Time: 10:00 AM – 11:00 AM EST
📍 Register: lu.ma/evqa4rct
Super proud to work at a place that values open science.
Four years ago, at NannyML, we invented the first version of Confidence-Based Performance Estimation. Today, a paper about it was published in JAIR.
JAIR: jair.org/index.php/ja...
ArXiv: arxiv.org/abs/2407.08649
Four years ago, at NannyML, we invented the first version of Confidence-Based Performance Estimation. Today, a paper about it was published in JAIR.
JAIR: jair.org/index.php/ja...
ArXiv: arxiv.org/abs/2407.08649

January 21, 2025 at 11:31 PM
Super proud to work at a place that values open science.
Four years ago, at NannyML, we invented the first version of Confidence-Based Performance Estimation. Today, a paper about it was published in JAIR.
JAIR: jair.org/index.php/ja...
ArXiv: arxiv.org/abs/2407.08649
Four years ago, at NannyML, we invented the first version of Confidence-Based Performance Estimation. Today, a paper about it was published in JAIR.
JAIR: jair.org/index.php/ja...
ArXiv: arxiv.org/abs/2407.08649
Took me over an hour to fully understand the computation behind the Pair Confusion Matrix.
Hopefully, it’ll take you a lot less after reading my explanation in "The Little Book of ML Metrics"
www.nannyml.com/metrics?via=...
Hopefully, it’ll take you a lot less after reading my explanation in "The Little Book of ML Metrics"
www.nannyml.com/metrics?via=...

January 18, 2025 at 9:48 PM
Took me over an hour to fully understand the computation behind the Pair Confusion Matrix.
Hopefully, it’ll take you a lot less after reading my explanation in "The Little Book of ML Metrics"
www.nannyml.com/metrics?via=...
Hopefully, it’ll take you a lot less after reading my explanation in "The Little Book of ML Metrics"
www.nannyml.com/metrics?via=...
You can just do many things.
Yesterday was my first day at culinary school!
Yesterday was my first day at culinary school!


January 18, 2025 at 12:32 AM
You can just do many things.
Yesterday was my first day at culinary school!
Yesterday was my first day at culinary school!
If people don’t think what you do is cringe, then you’re not pushing hard enough.
Every person you admire was once considered cringe by someone.
A Writer, YouTuber, Founder, Musician, you name it. They all got to where they are because they constantly shared their work with the world. Constantly.
Every person you admire was once considered cringe by someone.
A Writer, YouTuber, Founder, Musician, you name it. They all got to where they are because they constantly shared their work with the world. Constantly.

January 16, 2025 at 4:35 AM
If people don’t think what you do is cringe, then you’re not pushing hard enough.
Every person you admire was once considered cringe by someone.
A Writer, YouTuber, Founder, Musician, you name it. They all got to where they are because they constantly shared their work with the world. Constantly.
Every person you admire was once considered cringe by someone.
A Writer, YouTuber, Founder, Musician, you name it. They all got to where they are because they constantly shared their work with the world. Constantly.
We’re deciding what book to read next in the "AI from Scratch" study group.
So far, we have these two:
1. AI Engineering by Chip Huyen
2. Hands-On Generative AI with Transformers and Diffusion Models by Omar Sanseviero and gang
Any other suggestions?
So far, we have these two:
1. AI Engineering by Chip Huyen
2. Hands-On Generative AI with Transformers and Diffusion Models by Omar Sanseviero and gang
Any other suggestions?


January 13, 2025 at 9:03 PM
We’re deciding what book to read next in the "AI from Scratch" study group.
So far, we have these two:
1. AI Engineering by Chip Huyen
2. Hands-On Generative AI with Transformers and Diffusion Models by Omar Sanseviero and gang
Any other suggestions?
So far, we have these two:
1. AI Engineering by Chip Huyen
2. Hands-On Generative AI with Transformers and Diffusion Models by Omar Sanseviero and gang
Any other suggestions?
First AI from Scratch session of 2025!
A big thanks to @carloscapote.bsky.social and Michael Erasmus for their excellent explanations in today's meeting.
A big thanks to @carloscapote.bsky.social and Michael Erasmus for their excellent explanations in today's meeting.

January 12, 2025 at 9:19 PM
First AI from Scratch session of 2025!
A big thanks to @carloscapote.bsky.social and Michael Erasmus for their excellent explanations in today's meeting.
A big thanks to @carloscapote.bsky.social and Michael Erasmus for their excellent explanations in today's meeting.
Forgot to share the news, but here it is:
Our NannyML open-source package reached 2,000 GitHub stars! 🌟
Slowly but steadily 💪
Our NannyML open-source package reached 2,000 GitHub stars! 🌟
Slowly but steadily 💪

January 10, 2025 at 5:58 PM
Forgot to share the news, but here it is:
Our NannyML open-source package reached 2,000 GitHub stars! 🌟
Slowly but steadily 💪
Our NannyML open-source package reached 2,000 GitHub stars! 🌟
Slowly but steadily 💪
Another one from the book.
Log Loss (aka cross-entropy loss)!
---
If you're interested in more metric descriptions like this one, check out the book I'm writing: The Little Book of ML Metrics.
GitHub Repo: github.com/NannyML/The-...
Pre-order the book:https://www.nannyml.com/metrics
Log Loss (aka cross-entropy loss)!
---
If you're interested in more metric descriptions like this one, check out the book I'm writing: The Little Book of ML Metrics.
GitHub Repo: github.com/NannyML/The-...
Pre-order the book:https://www.nannyml.com/metrics

January 9, 2025 at 5:08 PM
Another one from the book.
Log Loss (aka cross-entropy loss)!
---
If you're interested in more metric descriptions like this one, check out the book I'm writing: The Little Book of ML Metrics.
GitHub Repo: github.com/NannyML/The-...
Pre-order the book:https://www.nannyml.com/metrics
Log Loss (aka cross-entropy loss)!
---
If you're interested in more metric descriptions like this one, check out the book I'm writing: The Little Book of ML Metrics.
GitHub Repo: github.com/NannyML/The-...
Pre-order the book:https://www.nannyml.com/metrics
Which ranking metrics am I missing?
In the coming weeks, I'll be working on the ranking chapter for "The Little Book of ML Metrics", and I want to make sure I'm not missing any popular ranking/recsys metrics.
In the coming weeks, I'll be working on the ranking chapter for "The Little Book of ML Metrics", and I want to make sure I'm not missing any popular ranking/recsys metrics.

January 8, 2025 at 8:57 PM
Which ranking metrics am I missing?
In the coming weeks, I'll be working on the ranking chapter for "The Little Book of ML Metrics", and I want to make sure I'm not missing any popular ranking/recsys metrics.
In the coming weeks, I'll be working on the ranking chapter for "The Little Book of ML Metrics", and I want to make sure I'm not missing any popular ranking/recsys metrics.
ML Books I'll Be Reading in 2025 📚
1. "AI Engineering: Building Applications with Foundation Models" (Huyen, 2024): amzn.to/4gtQgJo
We’ll probably read it in the study group "AI from Scratch."
1. "AI Engineering: Building Applications with Foundation Models" (Huyen, 2024): amzn.to/4gtQgJo
We’ll probably read it in the study group "AI from Scratch."

January 2, 2025 at 2:59 PM
ML Books I'll Be Reading in 2025 📚
1. "AI Engineering: Building Applications with Foundation Models" (Huyen, 2024): amzn.to/4gtQgJo
We’ll probably read it in the study group "AI from Scratch."
1. "AI Engineering: Building Applications with Foundation Models" (Huyen, 2024): amzn.to/4gtQgJo
We’ll probably read it in the study group "AI from Scratch."
During the pandemic—specifically, on May 7, 2020—I wrote some goals on a piece of paper. I folded it, stored it in my wallet, and forgot about it.
Today, I found it and realized I’ve accomplished all of them.
Today, I found it and realized I’ve accomplished all of them.

December 30, 2024 at 4:17 AM
During the pandemic—specifically, on May 7, 2020—I wrote some goals on a piece of paper. I folded it, stored it in my wallet, and forgot about it.
Today, I found it and realized I’ve accomplished all of them.
Today, I found it and realized I’ve accomplished all of them.
Univariate data drift doesn't show the full picture.
Take a look at this demo created by my colleague @anopsy.bsky.social
There are two univariate distributions (top and right) which remain almost unchanged during the whole process.
Take a look at this demo created by my colleague @anopsy.bsky.social
There are two univariate distributions (top and right) which remain almost unchanged during the whole process.

December 17, 2024 at 6:21 PM
Univariate data drift doesn't show the full picture.
Take a look at this demo created by my colleague @anopsy.bsky.social
There are two univariate distributions (top and right) which remain almost unchanged during the whole process.
Take a look at this demo created by my colleague @anopsy.bsky.social
There are two univariate distributions (top and right) which remain almost unchanged during the whole process.
Yesterday I forgot to post about our study group meeting 😅
It was an amazing one! @carloscapote.bsky.social walked us through Chapter 5: Pretraining on Unlabeled Data.
Next week, we’ll take a short break, but we’ll be back after the holidays to finish Chapters 6 and 7 💪
It was an amazing one! @carloscapote.bsky.social walked us through Chapter 5: Pretraining on Unlabeled Data.
Next week, we’ll take a short break, but we’ll be back after the holidays to finish Chapters 6 and 7 💪

December 16, 2024 at 5:10 PM
Yesterday I forgot to post about our study group meeting 😅
It was an amazing one! @carloscapote.bsky.social walked us through Chapter 5: Pretraining on Unlabeled Data.
Next week, we’ll take a short break, but we’ll be back after the holidays to finish Chapters 6 and 7 💪
It was an amazing one! @carloscapote.bsky.social walked us through Chapter 5: Pretraining on Unlabeled Data.
Next week, we’ll take a short break, but we’ll be back after the holidays to finish Chapters 6 and 7 💪
F1-score often takes all the credit. But what F1-score doesn't want you to know is that it wouldn't be so popular without its big brother, F-beta.
Check out other metrics at:
github.com/NannyML/The-...
Check out other metrics at:
github.com/NannyML/The-...

December 12, 2024 at 4:21 PM
F1-score often takes all the credit. But what F1-score doesn't want you to know is that it wouldn't be so popular without its big brother, F-beta.
Check out other metrics at:
github.com/NannyML/The-...
Check out other metrics at:
github.com/NannyML/The-...
800 GitHub stars on The Little Book of ML Metrics 🌟
But even more exciting than the stars is that for the past week, every day I've been waking up to at least two PRs from the community helping me write the book 🔥
But even more exciting than the stars is that for the past week, every day I've been waking up to at least two PRs from the community helping me write the book 🔥

December 10, 2024 at 3:40 PM
800 GitHub stars on The Little Book of ML Metrics 🌟
But even more exciting than the stars is that for the past week, every day I've been waking up to at least two PRs from the community helping me write the book 🔥
But even more exciting than the stars is that for the past week, every day I've been waking up to at least two PRs from the community helping me write the book 🔥
Today’s session was a fun one.
We started putting everything together and implemented a GPT model.
My favorite part of the book is the way Sebastian outlined and structured it to progressively build on previous sections. That alone makes it worth every penny.
We started putting everything together and implemented a GPT model.
My favorite part of the book is the way Sebastian outlined and structured it to progressively build on previous sections. That alone makes it worth every penny.

December 8, 2024 at 8:04 PM
Today’s session was a fun one.
We started putting everything together and implemented a GPT model.
My favorite part of the book is the way Sebastian outlined and structured it to progressively build on previous sections. That alone makes it worth every penny.
We started putting everything together and implemented a GPT model.
My favorite part of the book is the way Sebastian outlined and structured it to progressively build on previous sections. That alone makes it worth every penny.
Performance metrics are aggregates.
Watch out for underperforming segments 👀
Watch out for underperforming segments 👀

December 5, 2024 at 5:07 PM
Performance metrics are aggregates.
Watch out for underperforming segments 👀
Watch out for underperforming segments 👀
There are scenarios where data drift can improve model performance.
This happens when the production data moves to regions where the model is more confident in its predictions.
This happens when the production data moves to regions where the model is more confident in its predictions.
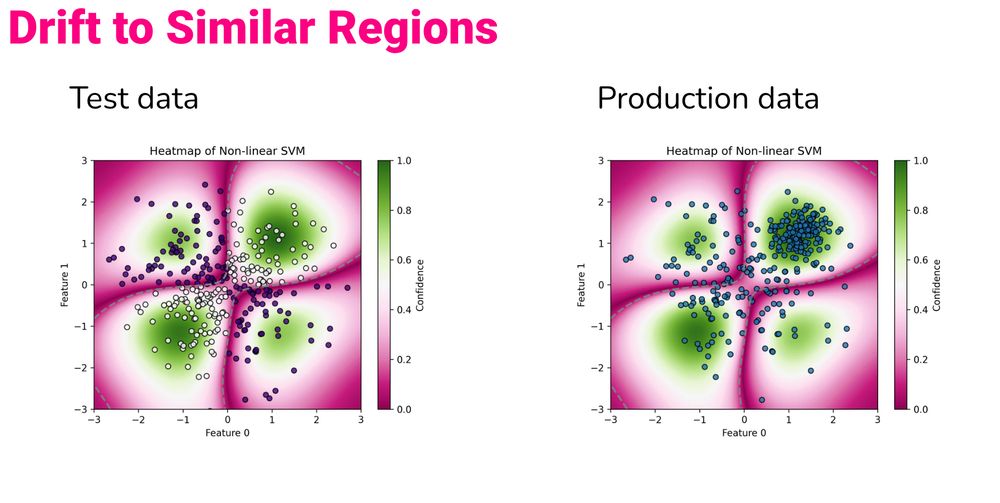
December 4, 2024 at 5:45 PM
There are scenarios where data drift can improve model performance.
This happens when the production data moves to regions where the model is more confident in its predictions.
This happens when the production data moves to regions where the model is more confident in its predictions.
Today, I opened a ton of good first issues. So, if you'd like to help me write The Little ML Metrics Book, hit me up, and I'll guide you through your first issue.
github.com/NannyML/The-...
github.com/NannyML/The-...

November 30, 2024 at 6:04 AM
Today, I opened a ton of good first issues. So, if you'd like to help me write The Little ML Metrics Book, hit me up, and I'll guide you through your first issue.
github.com/NannyML/The-...
github.com/NannyML/The-...
Let me try something

November 28, 2024 at 12:45 PM
Let me try something
I asked an AI Engineer what it would cost to create this today.
I will never forget his answer…
“We can’t, we don’t know how to do it.”
I will never forget his answer…
“We can’t, we don’t know how to do it.”

November 27, 2024 at 4:39 PM
I asked an AI Engineer what it would cost to create this today.
I will never forget his answer…
“We can’t, we don’t know how to do it.”
I will never forget his answer…
“We can’t, we don’t know how to do it.”
Richard S. Sutton: "I'll write an introduction to RL."
Also Richard: Writes a 552-page-long book
Also Richard: Writes a 552-page-long book

November 26, 2024 at 5:22 PM
Richard S. Sutton: "I'll write an introduction to RL."
Also Richard: Writes a 552-page-long book
Also Richard: Writes a 552-page-long book

Today's session was a great one.
I feel like the intuition behind Q, K, and V matrices in self-attention finally clicked for many of us.
I feel like the intuition behind Q, K, and V matrices in self-attention finally clicked for many of us.

November 25, 2024 at 3:53 AM
Today's session was a great one.
I feel like the intuition behind Q, K, and V matrices in self-attention finally clicked for many of us.
I feel like the intuition behind Q, K, and V matrices in self-attention finally clicked for many of us.