




Ryo Kamoi
@ryokamoi.bsky.social
#NLProc PhD Student at Penn State. Prev: MS at UT Austin, BE at Keio Univ, Intern at Microsoft OAR and Amazon Alexa.
https://ryokamoi.github.io/
https://ryokamoi.github.io/
Our paper VisOnlyQA has been accepted to
@colmweb.org #COLM2025! See you in Montreal🍁
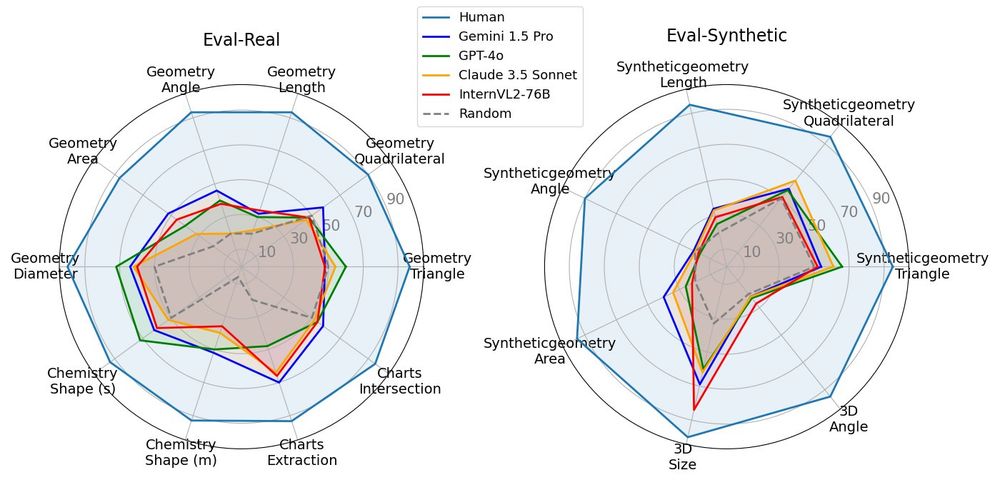
We find that even recent Vision Language Models struggle with simple questions about geometric properties in images, such as "What is the degree of angle AOD?"🧐
arxiv.org/abs/2412.00947
bsky.app/profile/ryok...
@colmweb.org #COLM2025! See you in Montreal🍁
We find that even recent Vision Language Models struggle with simple questions about geometric properties in images, such as "What is the degree of angle AOD?"🧐
arxiv.org/abs/2412.00947
bsky.app/profile/ryok...


July 13, 2025 at 7:05 PM
Our paper VisOnlyQA has been accepted to
@colmweb.org #COLM2025! See you in Montreal🍁
We find that even recent Vision Language Models struggle with simple questions about geometric properties in images, such as "What is the degree of angle AOD?"🧐
arxiv.org/abs/2412.00947
bsky.app/profile/ryok...
@colmweb.org #COLM2025! See you in Montreal🍁
We find that even recent Vision Language Models struggle with simple questions about geometric properties in images, such as "What is the degree of angle AOD?"🧐
arxiv.org/abs/2412.00947
bsky.app/profile/ryok...
VLMEvalKit now supports our VisOnlyQA dataset 🔥🔥🔥
github.com/open-compass...
VisOnlyQA reveals that even recent LVLMs like GPT-4o and Gemini 1.5 Pro stumble on simple visual perception questions, e.g., "What is the degree of angle AOD?"🧐
arxiv.org/abs/2412.00947
github.com/open-compass...
VisOnlyQA reveals that even recent LVLMs like GPT-4o and Gemini 1.5 Pro stumble on simple visual perception questions, e.g., "What is the degree of angle AOD?"🧐
arxiv.org/abs/2412.00947
December 6, 2024 at 3:38 PM
VLMEvalKit now supports our VisOnlyQA dataset 🔥🔥🔥
github.com/open-compass...
VisOnlyQA reveals that even recent LVLMs like GPT-4o and Gemini 1.5 Pro stumble on simple visual perception questions, e.g., "What is the degree of angle AOD?"🧐
arxiv.org/abs/2412.00947
github.com/open-compass...
VisOnlyQA reveals that even recent LVLMs like GPT-4o and Gemini 1.5 Pro stumble on simple visual perception questions, e.g., "What is the degree of angle AOD?"🧐
arxiv.org/abs/2412.00947
Interestingly, our experiments suggest that stronger language models improve visual perception of LVLMs, even when using the same visual encoders (ViT).
We conclude that we need to improve both the training data and model architecture of LVLMs for better visual perception. [4/n]
We conclude that we need to improve both the training data and model architecture of LVLMs for better visual perception. [4/n]

December 4, 2024 at 7:05 PM
Interestingly, our experiments suggest that stronger language models improve visual perception of LVLMs, even when using the same visual encoders (ViT).
We conclude that we need to improve both the training data and model architecture of LVLMs for better visual perception. [4/n]
We conclude that we need to improve both the training data and model architecture of LVLMs for better visual perception. [4/n]
We hypothesize that the weak visual perception is due to the lack of training data. To verify this, we make training data for VisOnlyQA, but we observe that the performance after fine-tuning depends on tasks and models, suggesting that training data is not the only problem. [3/n]

December 4, 2024 at 7:05 PM
We hypothesize that the weak visual perception is due to the lack of training data. To verify this, we make training data for VisOnlyQA, but we observe that the performance after fine-tuning depends on tasks and models, suggesting that training data is not the only problem. [3/n]
VisOnlyQA includes questions about geometric and numerical information on scientific figures.
Recent benchmarks for LVLMs often involve reasoning or knowledge, putting less focus on visual perception. In contrast, VisOnlyQA is designed to evaluate visual perception directly [2/n]
Recent benchmarks for LVLMs often involve reasoning or knowledge, putting less focus on visual perception. In contrast, VisOnlyQA is designed to evaluate visual perception directly [2/n]

December 4, 2024 at 7:05 PM
VisOnlyQA includes questions about geometric and numerical information on scientific figures.
Recent benchmarks for LVLMs often involve reasoning or knowledge, putting less focus on visual perception. In contrast, VisOnlyQA is designed to evaluate visual perception directly [2/n]
Recent benchmarks for LVLMs often involve reasoning or knowledge, putting less focus on visual perception. In contrast, VisOnlyQA is designed to evaluate visual perception directly [2/n]
📢 New preprint! Do LVLMs have strong visual perception capabilities? Not quite yet...
We introduce VisOnlyQA, a new dataset for evaluating the visual perception of LVLMs, but existing LVLMs perform poorly on our dataset. [1/n]
arxiv.org/abs/2412.00947
github.com/psunlpgroup/...
We introduce VisOnlyQA, a new dataset for evaluating the visual perception of LVLMs, but existing LVLMs perform poorly on our dataset. [1/n]
arxiv.org/abs/2412.00947
github.com/psunlpgroup/...


December 4, 2024 at 7:05 PM
📢 New preprint! Do LVLMs have strong visual perception capabilities? Not quite yet...
We introduce VisOnlyQA, a new dataset for evaluating the visual perception of LVLMs, but existing LVLMs perform poorly on our dataset. [1/n]
arxiv.org/abs/2412.00947
github.com/psunlpgroup/...
We introduce VisOnlyQA, a new dataset for evaluating the visual perception of LVLMs, but existing LVLMs perform poorly on our dataset. [1/n]
arxiv.org/abs/2412.00947
github.com/psunlpgroup/...