



@rui-xiao.bsky.social
Reposted

(2/4) COSMOS: Cross-Modality Self-Distillation for Vision Language Pre-training
Fantastic work done by Sanghwan Kim, @rui-xiao.bsky.social, Mariana Iuliana Georgescu, Stephan Alaniz, @zeynepakata.bsky.social .
📖 [Paper]: arxiv.org/abs/2412.01814
💻 [Code]: github.com/ExplainableM...
Fantastic work done by Sanghwan Kim, @rui-xiao.bsky.social, Mariana Iuliana Georgescu, Stephan Alaniz, @zeynepakata.bsky.social .
📖 [Paper]: arxiv.org/abs/2412.01814
💻 [Code]: github.com/ExplainableM...

April 28, 2025 at 11:51 AM
(2/4) COSMOS: Cross-Modality Self-Distillation for Vision Language Pre-training
Fantastic work done by Sanghwan Kim, @rui-xiao.bsky.social, Mariana Iuliana Georgescu, Stephan Alaniz, @zeynepakata.bsky.social .
📖 [Paper]: arxiv.org/abs/2412.01814
💻 [Code]: github.com/ExplainableM...
Fantastic work done by Sanghwan Kim, @rui-xiao.bsky.social, Mariana Iuliana Georgescu, Stephan Alaniz, @zeynepakata.bsky.social .
📖 [Paper]: arxiv.org/abs/2412.01814
💻 [Code]: github.com/ExplainableM...
Reposted
(1/4) FLAIR: VLM with Fine-grained Language-informed Image Representations
By @rui-xiao.bsky.social, Sanghwan Kim, Mariana Iuliana Georgescu, @zeynepakata.bsky.social,Stephan Alaniz.
😼 [Project]: explainableml.github.io/flair-website/
💻 [Code]: github.com/ExplainableM...
By @rui-xiao.bsky.social, Sanghwan Kim, Mariana Iuliana Georgescu, @zeynepakata.bsky.social,Stephan Alaniz.
😼 [Project]: explainableml.github.io/flair-website/
💻 [Code]: github.com/ExplainableM...

April 28, 2025 at 11:51 AM
(1/4) FLAIR: VLM with Fine-grained Language-informed Image Representations
By @rui-xiao.bsky.social, Sanghwan Kim, Mariana Iuliana Georgescu, @zeynepakata.bsky.social,Stephan Alaniz.
😼 [Project]: explainableml.github.io/flair-website/
💻 [Code]: github.com/ExplainableM...
By @rui-xiao.bsky.social, Sanghwan Kim, Mariana Iuliana Georgescu, @zeynepakata.bsky.social,Stephan Alaniz.
😼 [Project]: explainableml.github.io/flair-website/
💻 [Code]: github.com/ExplainableM...
Reposted
🎓 PhD Spotlight: Otniel-Bogdan Mercea
We’re excited to celebrate @merceaotniel.bsky.social , who will defend his PhD on April 16th! See the thread to feature his research highlights👇
We’re excited to celebrate @merceaotniel.bsky.social , who will defend his PhD on April 16th! See the thread to feature his research highlights👇

April 14, 2025 at 11:20 AM
🎓 PhD Spotlight: Otniel-Bogdan Mercea
We’re excited to celebrate @merceaotniel.bsky.social , who will defend his PhD on April 16th! See the thread to feature his research highlights👇
We’re excited to celebrate @merceaotniel.bsky.social , who will defend his PhD on April 16th! See the thread to feature his research highlights👇
Reposted
We introduce FLAIR, which empowers CLIP with Language-informed Image Representations via text-conditioned attention pooling.
Trained on 30M pairs, it outperforms billion-scale models on zero-shot image-text retrieval and segmentation.
📄 arxiv.org/abs/2412.03561
🔓 github.com/ExplainableM...
Trained on 30M pairs, it outperforms billion-scale models on zero-shot image-text retrieval and segmentation.
📄 arxiv.org/abs/2412.03561
🔓 github.com/ExplainableM...

FLAIR: VLM with Fine-grained Language-informed Image Representations
CLIP has shown impressive results in aligning images and texts at scale. However, its ability to capture detailed visual features remains limited because CLIP matches images and texts at a global leve...
arxiv.org
April 2, 2025 at 11:36 AM
We introduce FLAIR, which empowers CLIP with Language-informed Image Representations via text-conditioned attention pooling.
Trained on 30M pairs, it outperforms billion-scale models on zero-shot image-text retrieval and segmentation.
📄 arxiv.org/abs/2412.03561
🔓 github.com/ExplainableM...
Trained on 30M pairs, it outperforms billion-scale models on zero-shot image-text retrieval and segmentation.
📄 arxiv.org/abs/2412.03561
🔓 github.com/ExplainableM...
Reposted
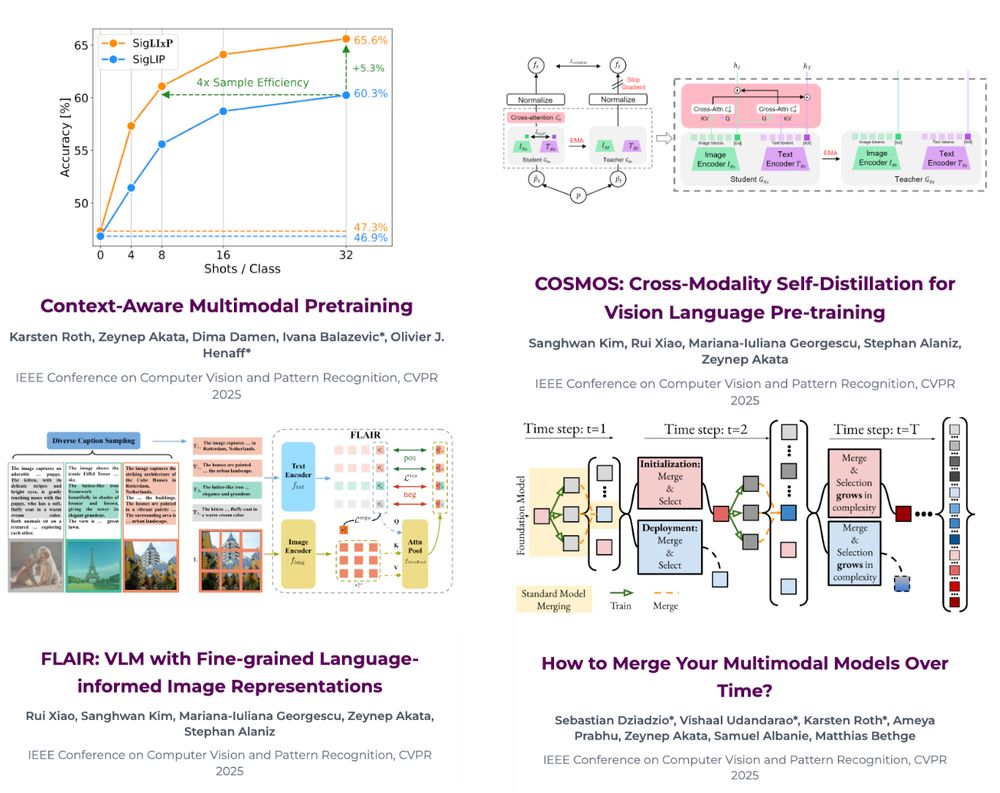
Thrilled to announce that four papers from our group have been accepted to #CVPR2025 in Nashville! 🎉 Congrats to all authors & collaborators.
Our work spans multimodal pre-training, model merging, and more.
📄 Papers & codes: eml-munich.de#publications
See threads for highlights in each paper.
#CVPR
Our work spans multimodal pre-training, model merging, and more.
📄 Papers & codes: eml-munich.de#publications
See threads for highlights in each paper.
#CVPR
April 2, 2025 at 11:36 AM
Thrilled to announce that four papers from our group have been accepted to #CVPR2025 in Nashville! 🎉 Congrats to all authors & collaborators.
Our work spans multimodal pre-training, model merging, and more.
📄 Papers & codes: eml-munich.de#publications
See threads for highlights in each paper.
#CVPR
Our work spans multimodal pre-training, model merging, and more.
📄 Papers & codes: eml-munich.de#publications
See threads for highlights in each paper.
#CVPR